In this method the LaserData struct is used to track the measured distances from the walls to the robot. To make the robot drive forward the sendBaseReference command is used, and the robot moves in the x direction at a speed of 0.2. Once it reaches the wall in front of it and the range values drop to below 0.2, motion is halted and a message is printed to the screen before exiting the program.
Some experimentation was done to test different speeds and thresholds for the stopping range values. When the speed was higher than the stopping range value the robot would actually crash into the wall first before stopping, and if it was lower then the robot would stop slightly farther away from the wall. However, this only seemed to be the case when the stopping value was very low (e.g. 0.1), but increasing it to 0.2, for example, allowed the speed to be increased to 0.4 without any crashing.
Method 2
In method 3 a LaserData structure is created to get measurements of the distance between the robot and its surroundings. A variable of type double is created which is named LowerLimit, referring to the minimal distance between the wall and the robot where action should be taken. This lower limit is set at 0.3 meters. Furthermore, four other variables of type double are defined to create two cones, a left and right cone. Namely, LeftCone1 (n = 999) referring to the end of the measurement range, LeftCone2 (n = 500) referring to the beginning of the second half of the measurement range, RightCone1 (n = 499) referring to the end of the first half of the measurement range and RightCone2 (n = 0) referring to the beginning of the measurement range. Lastly, turning angles of pi/6 to the right and left are defined as TurningAngleRight and TurningAngleLeft, respectively.
After creating all necessary variables, a while-loop is created which holds true for io.ok(). First, a base reference with a velocity of 0.2 in the X-direction is send to the robot using the function io.sendBaseReference(0.2,0,0). Then, the LaserData structure is read, checking if there is new data. If this holds true a for-loop is created that iterates over all the distance measurements. Two if-statements then check if a certain distance measurement is in the right or left cone and below the lower limit. When in the right cone and below the lower limit a command is send to the robot to stop moving and then turn left with the function io.sendBaseReference(0,0,TurningAngleLeft). Else, when in the left cone and below the lower limit a command is send to the robot to again stop moving and then turn to the right with the function io.sendBaseReference(0,0,TurningAngleRight).
Testing with the first given map it is clear no collision is made between the robot and the walls. Although when it changes direction it does so with a fixed value, overall not making any significant progress when driving around the space. Testing with different values for turning angles, smaller cones or a higher lower limit all produce different behaviours but one can't be called better than the other.
Method 3 working as intended. Difficulty with getting out of two corners, due to a large turning angle.
Comparison of Method 1 and Method 2 for Robot Navigation
Method 1: Simple Forward Movement with Stopping Threshold
Summary:
Approach: The robot moves forward at a set speed until the measured distance to the wall drops below a predefined threshold (e.g., 0.2 meters). Upon reaching this distance, the robot halts.
Key Components:
LaserData: Used to measure distances to the walls.
sendBaseReference: Command to move the robot forward at a speed of 0.2 m/s.
Stopping Threshold: A predefined distance where the robot stops to avoid collision.
Strengths:
Simplicity: The method is straightforward, focusing on forward movement and stopping based on a distance threshold.
Predictability: The robot's behavior is easy to predict and control with a simple speed and distance relationship.
Limitations:
Limited Flexibility: Only stops the robot; no turning or dynamic obstacle avoidance.
Potential Collisions: If the stopping threshold is too low relative to the speed, the robot risks crashing into the wall.
Best Situations:
Straight, unobstructed paths: Ideal for scenarios where the robot can move straight without the need for complex navigation.
Predictable environments: Works well in environments where walls and obstacles are well known and spaced out.
Method 2: Dynamic Obstacle Avoidance with Cones and Turning
Summary:
Approach: The robot moves forward and uses distance measurements to dynamically avoid obstacles. It turns left or right based on the proximity of objects within predefined cones on either side.
Key Components:
LaserData: Used to get distance measurements.
LowerLimit: The minimum safe distance to an obstacle (e.g., 0.3 meters).
Cones: Defined regions (left and right) for detecting obstacles.
Turning Angles: Fixed angles for turning left or right to avoid obstacles.
Strengths:
Dynamic Navigation: Capable of navigating through more complex environments by adjusting direction to avoid collisions.
Obstacle Avoidance: Uses distance measurements within specific cones to turn away from obstacles dynamically.
Limitations:
Fixed Turning Angles: Turning is not adaptive; fixed angles may not always be optimal for all scenarios.
Potential for Non-linear Movement: The robot may not make significant forward progress if continuously turning.
Best Situations:
Complex environments: Suitable for spaces with many obstacles where dynamic avoidance is necessary.
Dynamic obstacle presence: Works well when the robot needs to react to moving obstacles or changing surroundings.
Conclusion
Comparison Summary:
Method 1 is simpler and more suited for straightforward navigation where obstacles are predictable and minimal.
Method 2 offers more flexibility and is better suited for environments where the robot needs to navigate around obstacles dynamically.
Which is Better?
Method 2 is generally better for more complex navigation tasks due to its ability to dynamically avoid obstacles and adapt its path. It prevents collisions more effectively than Method 1 and can handle more diverse environments. However, for simple and controlled settings, Method 1 provides a straightforward and reliable solution.
Exercise 2
Method 1
The previously described method was tested on the two provided maps with input speeds of (0.3, 0, +-0.3) and a stopping value of 0.2. With both maps the robot successfully came to a stop before crashing, although it struggled when driving into a corner and stopped much closer to the wall than it did in previous tests.
Method 1 on Map 1.
Method 1 on Map 2.
method 2:
for method 2 there was a slightly different approach. laserdata was scanned (not full range about 200 to 800). every time it runs into a wall the robot turns randomly. it wil turn the same direction until it sees the robot is free to drive. This added random turning makes it possible that the robot randomly finds exits and explores the map. The code translated wel to bobo where it stopped without bumping and turned around to explore.
live test
Method 2 on general map
Method 3:
In the two videos where both maps are simulated with method 3 of the don_crash algorithm, the results are very similar to the results in the map of exercise 1.
Method 3 riding around without collision on map 1Method 3 riding around without colliding on map 2
Practical Exercises 1
On the robot-laptop open rviz. Observe the laser data. How much noise is there on the laser? What objects can be seen by the laser? Which objects cannot? How do your own legs look like to the robot.
When running the sim-rviz environment on the Bobo robot there was significant noise even when remaining stationary, as shown in the GIF below. Due to the density in hit points for the lasers, the measurement of solid flat walls was reliable. However, the noise had high amounts of variation when looking at the edges or corners of a wall, especially when corners were slightly behind the robot, which could indicate weak peripheral vision. Then, black coloured and thin objects were placed in front of the sensors and the robot struggled to detect them. Even when they are detected they still appear on the visualization with heavy amounts of noise. In contrast, our own legs, rolled up pieces of paper and contours were more clearly defined when placed in front of the robot.
Video of noise measurements in the sim-rviz environment.
Take your example of don't crash and test it on the robot. Does it work like in simulation? Why? Why not? (choose the most promising version of don't crash that you have.)
Two different don't crash codes were tested on the robot. The first code contained the method of detecting walls within a certain distance and telling the robot to stop and remain in position once it came too close. The second code contained the more elaborate method where the robot looked for the next direction of movement that did not have any walls within a set distance, and then continued driving in that direction. For the first code, it became apparent that in the simulation there was a higher margin for error in terms of how close the robot could get to the walls without the system alerting the user of a crash. For the real life test to work, the moving speed had to be reduced and the distance threshold increased to account for things like the robot's size. For the second code, the robot was able to follow simulation results and managed to perform well without needing modifications. GIFs of both code tests can be seen below.
Video of tests on the first code.
Video of tests on the second code.
If necessary make changes to your code and test again. What changes did you have to make? Why? Was this something you could have found in simulation?
As stated before, some changes had to be made to the moving speed and threshold for distances that counted as a "crash". This is not something that was immediately apparent in the simulations beforehand, but in hindsight it could have been prevented before testing the code on the actual robot. Of course, the robot in the simulations might not have the same dimensions as its real life counterpart, and so, the measure tool in the rviz environment could have been use to precisely measure the distance at which the robot was stopping, and whether or not it would be far enough for an actual robot.
Secondly, these min and max values can be used in 2 for loops to iterate over the velocities and subsequently angular velocities using a predefined step size
Iterate through the discretized values (v, w) of the union of Vs, Vd and Ws and Wd:
Calculate the Admissable (angular) Velocities (Va,Wa) using v and w
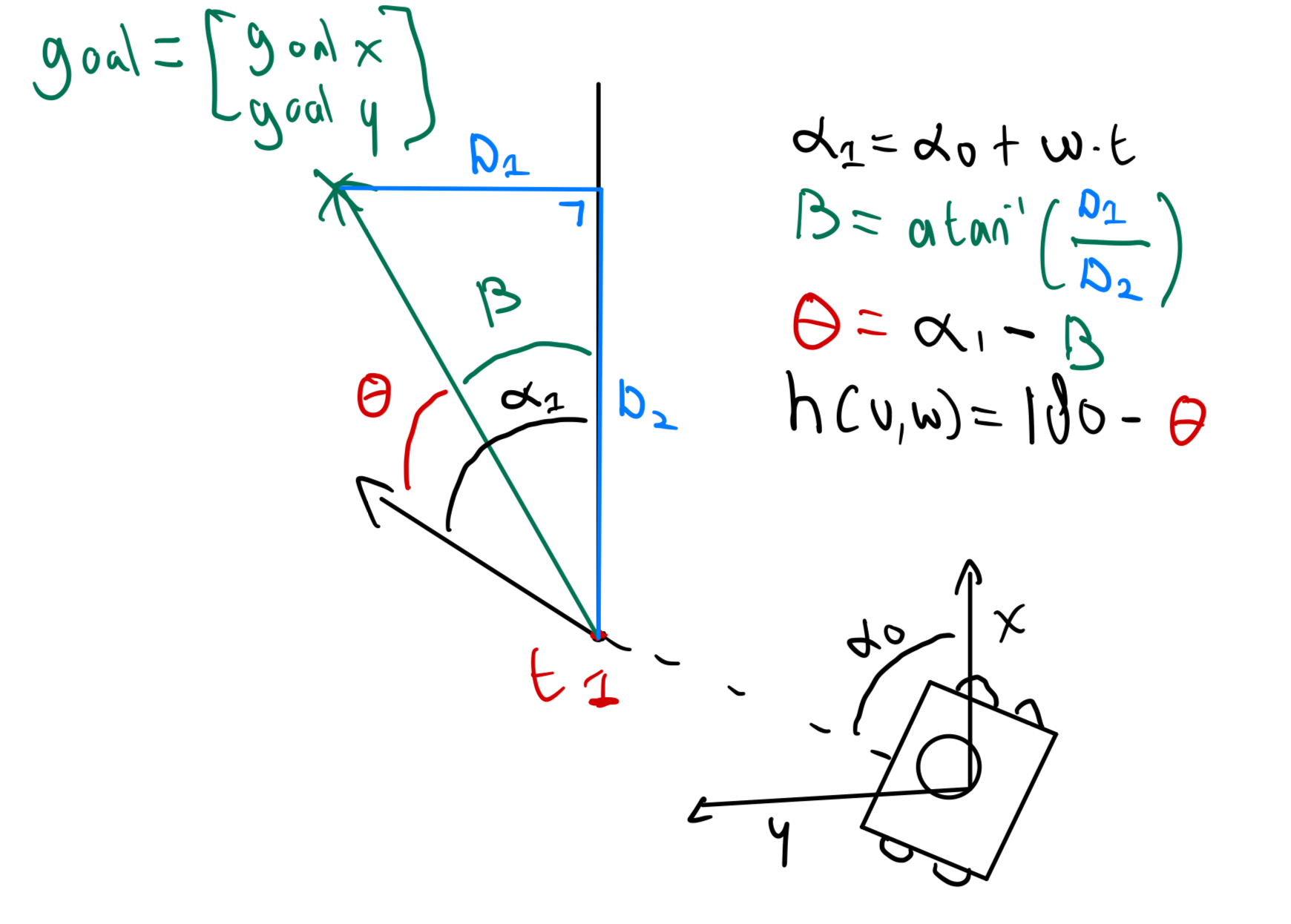
The calculation of the trajectory distance from the robot to an obstacle in its path.Using the v and w, a trajectory is calculated. On this trajectory, only a certain amount of points are taken into account, which are represented by the red points in the visualization. At these points on this trajectory, it is checked whether the robot will hit an obstacle by checking if the distance from the point to an obstacle is closer to the obstacle than the clearance distance. This clearance distance is thus dependent on the size of the robot. If it is true that the robot will hit the obstacle, the trajectory distance from the robot to that obstacle is calculated, represented by the green line. This is done for each point on the trajectory and the smallest distance of trajectory of the robot to an obstacle is saved. This distance can subsequently be used to calculate Va and Wa using: Va = {v,w | v ≤ (2d(v,w)*V_max_deacceleration)½ ∧ w ≤ (2d(v,w)*w_max_deacceleration)½}.
Check if v and w are also in Va and Wa, if this is the case:
Calculate the optimization function value. If this value is higher than the previous optimization value, set the current v and w to v_final and w_final
The calculation of the heading reward.The optimization function is given by: G(v,w) = σ(kh * h(v,w) + kd * d(v,w) + ks * s(v,w)). The d(v,w) and s(v,w) are straightforward and have already been calculated. The target heading towards goal reward h(v,w) can be obtained as seen in the visualisation.
Return v_final, w_final
Questions
1. What are the advantages and disadvantages of your solutions?
Advantages:
By constantly calculating possible trajectories it is able to avoid dynamic and static obstacles.
By including the robot acceleration and deceleration constraints it ensures for a smooth navigation without abrupt movements.
Disadvantages:
DWA may get trapped in a local minima.
There is a high computational load in calculating the multiple trajectories in real-time.
The performance is dependent on several hyperparameters. In addition, these hyperparameters can differ depending on the robot. Therefore, it is important and time-consuming to tune those parameters.
In the current approach, the robot hitting an obstacle is checked by the clearance radius which is used as a circle around the trajectory point in the future. However, the robot is not a circle. Moreover, it also depends on the location of the lidar sensor on the actual robot, which might differ between robots.
2. What are possible scenarios which can result in failures?
Like mentioned in question 1 DWA can get trapped in a local minima.
Solution: Include the global planner so it doesn't drive into a local minimum. Moreover, it can be checked if for a sequence of time the speed has been 0 (or very low), if this is the case, the robot can be turned 90. This allows the robot to look for new possibilities of bypassing the obstacles.
Solution: Increase Ks and decrease Kh so the robot is less constrained to drive directly towards the goal, and is more motivated to bypass the obstacle. Moreover, just like the local minima, it can be checked whether the speed has been 0 (or very low) for a certain amount of time. If this is the case, the robot can be turned for 90 degrees, allowing the robot to potentially look for new possibilities to bypass the obstacle.
3. How are the local and global planner linked together?
When linking global and local together, the waypoints generated by the global planner can be used as input in the DWA function. This function will subsequently output the best (angular) velocity. Once the waypoint is reached, the next waypoint given by the global planner will be used.
Vector Field Histograms
Vector Field Histograms (VFH) are a robot control algorithm used for real-time obstacle avoidance. VFH works by creating a histogram grid that represents the robot's surroundings, where each cell contains a value corresponding to the density of obstacles. The algorithm calculates a polar histogram from this grid to determine the direction with the least obstacle density, allowing the robot to navigate safely by selecting a path with minimal risk of collision. This approach is efficient and effective for navigating through complex and dynamic environments.
Case specific aproach
In our implementation of VFH, the following steps were taken:
Laser Data Acquisition: Laser data is obtained using the getLaserdata function, ensuring compatibility with all robots.
Data Preparation: The number of laser readings is rounded down to the nearest multiple of ten to avoid erroneous values. So, if there are 1003 scan values, then the last 3 values are removed and the maximum angle updated accordingly to keep the length of the scanData to a number divisible by ten. This is simply for allowing histogram bins of 10 scan values to avoid making the algorithm too computationally heavy. This is important to do as the three testing robots have different numbers of laser beams.
Data Binning: The laser readings are divided into bins by dividing the length of scanData by 10.
Histogram Calculation: These bins are used to create the vector field histogram. This histogram is a graph with angles on the x-axis and the likelihood of a blocking object on the y-axis. For each bin, the values are calculated using the following steps:
In batches of 10, loop over the values in the scanData.
Check the validity of the value, if it is larger than the set maximum window then set it to the maximum window's value. If it is less than the set minimum window, then set it to the minimum window's value.
Add the sum of inverse of the 10 values in a batch to create each bin in the histogram. Using the inverse ensures that angles with a far range value are given a low bin score and thus, increases the chances of the robot orienting itself towards walls that are farther away.
Path Selection: Angles where the y-axis value is below a certain threshold indicate unobstructed paths. The algorithm selects the angle that is both unobstructed and closest to the desired goal.
This approach ensures accurate and efficient obstacle avoidance, allowing the robot to navigate safely and effectively.
The optimization
A schematic overivew of the inclusions of the robot dimensions.
To optimize the Vector Field Histogram (VFH) algorithm for robot control, it’s crucial to consider the robot's dimensions to ensure it maintains a safe distance of at least 25 cm from walls and corners. This safety margin accounts for noise and potential calculation errors in the sensor data. Integrating the robot’s radius directly into the measured distance is complex due to the angular nature of laser measurements, which can distort data, especially over longer distances. These distortions may lead to missed corners and falsely indicated large open spaces in the histogram.
Why There Are Errors in Laser Data:
Angle of Incidence: The accuracy of a laser measurement depends on the angle at which the laser beam hits an obstacle. At oblique angles, reflections can be inaccurate, causing errors in the perceived distance.
Beam Divergence: As the laser beam travels further, it spreads out, potentially intersecting multiple surfaces or missing narrow objects entirely.
Surface Reflectivity: Different materials reflect laser beams differently. Reflective surfaces can scatter the beam, while non-reflective surfaces can absorb it, leading to inconsistent measurements.
Sensor Resolution: The resolution of the laser sensor decreases with distance, resulting in less precise measurements for far-away objects.
Algorithm for Generating Circles:
To address these issues, we developed an algorithm that generates circles at each point where the laser detects an object. Each circle has a radius that includes the robot's size plus a safety margin. Here's how it works:
Laser Detection Points: The laser detects obstacles and plots points in a coordinate system relative to the robot's position.
Generating Circles: At each detection point, a circle is drawn with a radius that includes the robot's dimensions and a safety buffer.
Intersection Determination: When a new laser point is detected, the algorithm checks if it intersects any existing circles. Intersections indicate proximity to obstacles, even if the obstacles are not directly in the path of the laser beam.
Adjusting Measured Distances: If an intersection occurs, the measured distance is adjusted to the closest point of intersection, effectively "blocking" narrow paths and corners that could mislead the robot.
This approach ensures the robot maintains a safe clearance from walls and corners, preventing it from navigating into risky or confined spaces. The algorithm effectively accounts for potential errors in laser data, enhancing the overall safety and reliability of the robot's navigation.
Results
The robot successfully navigates its environment while maintaining a safe distance from the walls, as demonstrated in the videos. Currently, it operates at a speed of 0.15 m/s, which is relatively low. This slow speed is necessary because the histogram calculations can yield suboptimal values if the decision-making time is too short. The most significant area for improvement in the system is increasing its decision-making efficiency. Future enhancements will include a stop mechanism that allows the robot to halt at critical decision points. At these points, the robot will rotate and scan the environment again before proceeding. This will reduce incorrect movements and enhance the robot's robustness and reliability.
Regarding the tuning of parameters, a significant amount of testing had to be done to bridge the results of the simulation with the real life testing sessions. Initially, the threshold for acceptable directions to take were estimated using the sum of the inverse of 10 measurements that were 1 meter away, so it was set to 10. However, with the addition of the spherical intersections, essentially all the range values decreased and the threshold value had to increase to 30-40. There is not a single specific threshold value set, as different values seem to perform better depending on which map the robot is tested in. For future improvements, it would be more robust to have a more calculated threshold value that performs well with all maps and different scenarios.
Test on Map 1.
Test on Map 2.
Test on Map 3.
Test on Map 4.
VFH test on Bobo with a setup similar to Map 3.
The VFH algorithm was also tested in real life on the Bobo robot - a video of which can be seen on the right. The testing environment was set up to replicate Map 3 from the simulations, but due to a shortage of walls only the main obstacles could be placed for this test. As can be seen in the video, the robot was able to evade the first two obstacles, but not the last one which it crashed into (the dontCrash algorithm had not been implemented yet at this stage). Another observation that can be made is that it is not clearing the obstacles with the same amount of space as the robot in the simulations did. Possible environmental causes could be a difference in laser measurements, low reflections of the laser beams due to the darker wall colours and the lack of the outside walls. However, it is also clear that the algorithm's code could be improved to handle these external factors which will always be present regardless of the robot being tested on. Threshold values could be tuned again with a larger robot radius set to increase the chances of cleanly evading obstacles. The data processing could also be made more robust to reduce the variation in laser measurements from noise. Lastly, the previously mentioned imporvement of forcing the robot to stop and rotate/scan its next path before moving forward could also give it more time to decide how to evade an obstacle.
Questions
What are the advantages and disadvantages of your solutions? The algorithm is computationally efficient. The laser scan data gets looped through a few times (collecting laser data, making the VFH from the laserdata, optional filtering of the VFH, choosing the best angle). This way the algorithm updates the robot without too much delay from the real time data. A disadvantage of the algorithm is that it does not account well for size of the robot. Even when inflating the walls in software the casting of the laser beam make it unpredictable if you actually drive aground a wall instead of next to the wall. It does drive itself around but the path is not always optimal.
What are possible scenarios which can result in failures?The algorithm will not navigate mazes itself. If there are too many obstructions the robot could get stuck between a few points. When entering for example something like a U shape that is larger than its viewing window. The robot will enter the hallway thinking it's is free, when seeing the end walls it will turn around until it doesn't see the wall anymore. At that point the robot will again turn around to get stuck in a loop.
How would you prevent these scenarios from happening?By integrating a good global planner the robot already will not go into these U shapes. If it finds itself stuck on a point that a global map didn't see the robot can report this back and again find a global route that can be locally navigated.
How are the local and global planner linked together?The VFH algorithm is structured using header files and separate class files. There is one main file, "Local_Nav.cpp", which runs the EMC environment and executes things like the import of odometry and laser data, and it then feeds those values into functions that will handle the calculations of the algorithm. In "Pos.cpp" there are functions defined for updating the robot's positional information (x, y and alpha), as well as, a function to inform it on its starting position (if it is not equal to (0, 0, 0)). Lastly, the bulk of the code can be found in "VFH.cpp", where actions like forming the bins of the histogram, calculating the next angle of movement, and so forth are completed. Most importantly, the execution of the VFH algorithm can be done with the getClosestFreeAngle() function, which accepts the x and y coordinates of the goal/waypoint as an input. Thus, it would be straightforward to sequentially input the waypoints of the global planner for the local planner to follow.
Global Navigation
A* Path Planning
The A* algorithm is a highly regarded pathfinding and graph traversal method, renowned for its efficiency and accuracy. It utilizes the strengths of Dijkstra's Algorithm and Greedy Best-First Search to identify the shortest path between nodes in a weighted graph. While its computational demands are somewhat higher compared to the aforementioned algorithms, A* has the distinct advantage of guaranteeing the discovery of the shortest route, provided one exists.
The algorithm constructs a tree of paths that begin at the start node and progressively extends these paths one edge at a time until the goal node is reached. During each iteration, it evaluates which path to extend next by considering both the actual cost incurred to reach a node and the estimated cost to reach the target from that node, known as the heuristic cost. The heuristic cost, which can differ across various implementations, typically represents the straight-line distance between the current node and the goal. To guarantee the algorithm's optimality, it is essential that this heuristic cost is never overestimated.
By ensuring the heuristic cost remains a lower bound on the true cost to reach the target, the A* algorithm can efficiently prioritize paths that are more likely to lead to the goal. This balance between actual cost and heuristic estimation allows A* to navigate complex graphs effectively, making it a powerful tool in fields ranging from robotics to game development and beyond. The precision and adaptability of the heuristic function are key factors in the algorithm's performance, influencing both its speed and accuracy in finding the shortest path.
Implementation:
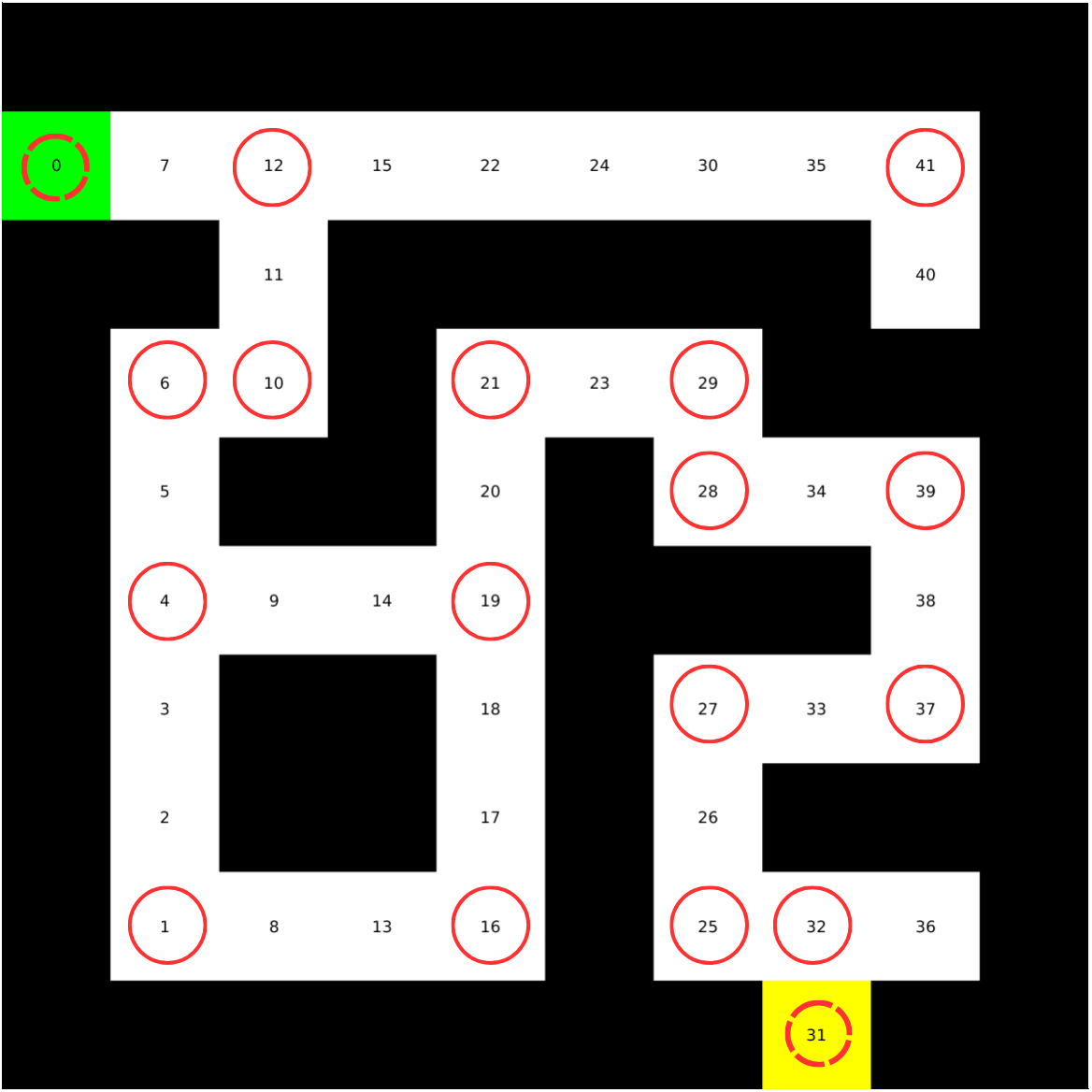
The A* algorithm was implemented to find the shortest path from the start to the exit of a maze where node lists and connections are provided.
Initialization of Nodes and Cost Calculation: The algorithm begins by initializing the necessary data structures and setting up initial conditions. It iterates through the entire node list, setting the cost-to-come (g) to infinity for each node, indicating that the initial cost to reach any node is unknown. The heuristic cost-to-go (h) is calculated as the Euclidean distance from each node to the goal node using the calculate_distance function. The total cost (f) for each node is the sum of g and g. Each node's parent ID is initialized to NODE_ID_NOT_SET indicating that no parent has been assigned yet. Two lists, open_nodes and close_nodes, are maintained to keep track of nodes to be evaluated and nodes that have already been evaluated, respectively. The entrance node is added to the open list with a cost-to-come of 0, and its total cost is recalculated.
Finding the Node to Expand Next: The first exercise is to find, in every iteration, the node that should be expanded next. The algorithm selects the node in the open list with the lowest f value, representing the node that currently appears to be the most promising for reaching the goal efficiently. This selection process ensures that the node with the smallest estimated total cost to the goal is chosen for expansion. If the selected node is the goal node, the algorithm terminates, having successfully found the optimal path.
Exploring Neighbors and Updating Costs: The second exercise is to explore its neighbors and update them if necessary. For the selected node, the algorithm examines all its neighboring nodes (nodes connected by an edge). It checks if each neighbor has already been evaluated by looking for it in the closed list. If the neighbor is not in the closed list, the algorithm then checks if it is in the open list. If it is not in the open list, the neighbor is added to the open list. The cost-to-come (g) and total cost (f) for this neighbor are updated based on the cost to reach it from the current node. The current node is also set as the parent of this neighbor. If the neighbor is already in the open list, the algorithm checks if a lower cost path to it is found via the current node. If so, it updates the g, f, and parent node ID for this neighbor. After processing all neighbors, the current node is moved from the open list to the closed list.
Tracing Back the Optimal Path: The third exercise is to trace back the optimal path. Once the goal node is reached, the algorithm reconstructs the optimal path by backtracking from the goal node to the start node using the parent node IDs. Starting at the goal node, the algorithm moves to its parent node repeatedly until the start node is reached. The node IDs along this path are collected in a list, representing the sequence of nodes from the entrance to the goal. The algorithm then updates the planner's state to indicate that a path has been found and sets the list of node IDs that constitute the optimal path.
The A* algorithm is tested on the small and big map provided for testing, and presented below are the results from the test on small map. It is evidently visible that the A* algorithm finds an optimal path to reach the goal node.
Probabilistic Road Maps (PRM)
The approach:
In the given code for the generation of the PRM, the three incomplete functions were coded using the following methods:
Inflating the walls of the map: The first step of the approach is to inflate the walls of the map to accommodate for the size of the robot. Thus, providing a path from A to B where it will not hit the walls. Inflating the walls is done by iterating through the pixels of the map. Due to the map having two distinct colors, black for the walls and white for the space accessible by the robot, they can be easily distinguished from one another. When a wall is detected (black pixel) in the original map, it sets the surrounding pixels in a copied map to black. By iterating through one map and making the changes in another the walls will only be inflated once.
Checking if the vertex is valid: First, an arbitrary distance of 0.8 m was set as the threshold for the distance that the new vertex had to be from existing vertices (this would be optimised later on). Then, by looping through the existing G.vertices given in the class Graph G, the provided distanceBetweenVertices function was used to check the Euclidean distance between each existing vertex and the newly generated one. If any of the distances fell below the set value, the acceptVert boolean was set to False.
Checking if the vertices are close: This function was completed in the same manner as the previous one. By using the same distanceBetweenVertices function, the two input vertices have their Euclidean distance calculated and compared with a set certain_distance. Should the calculated distance fall below the certain_distance then the boolean verticesAreClose is left as True, and otherwise it is set to False.
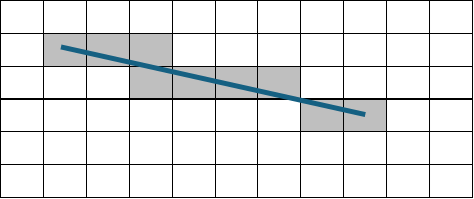
Check if edge crosses obstacleExample of pixel approximation of a line using Bresenham's algorithm.To complete this function, a pixel based approach was taken for checking the intersections between the line connecting two points and any existing obstacles/walls. The reason for doing so was so that we could implement the Bresenham line algorithm, and more importantly, avoid making the function computationally heavy with calculations such as storing the vectors connecting two points, calculating exact intersection points, and so forth (INSERT CITATION). Through Bresenham's algorithm, the code became more straightforward as loops over each existing pixel value would be sufficient for the check. To actually implement these ideas, the code was structured as follows:
First, the two vertices accepted as inputs have their coordinates converted from metres to pixels by dividing their x and y values by the resolution. For example, a vertex at (1,1) would be located on the pixel at row 20 and column 20. Note that in the code, the calculations for the y coordinates are mirrored, because without that the Bresenham line generation became flipped in the x axis.
Variables for iterating over each pixel, as per Bresenham's algorithm, variables are defined to determine the direction in which to iterate through the pixels. So, the algorithm will iterate left to right and up to down depending on the sign of the gradient values, dx and dy. Additionally, the error term, error = dx – dy, is defined which will keep track of whether the algorithm should stay on the same row/column or jump to the next one to keep following the line connecting the two vertices.
A while loop is initialized to continue running until one of the internal if statements become true. Starting with the x1 and y1 coordinates, an if statement checks that it is within the map boundaries and then checks the greyscale value of the pixel at that location. If the coordinate’s pixel has a greyscale value of less than 5 (essentially black), then EdgeCrossesObstacle is set to True and the code breaks out of the while loop.
If the starting coordinate does not contain a black/wall pixel, then the gradient and error terms inform the algorithm of which pixel to consider next. A new error term, e2, is declared by doubling the error term, err. If is larger than the negative of dy, then we know that the line connecting the two vertices continues on the next column and the x coordinate is shifted by one. If it is smaller than dx, then the line continues on the next row, so the y coordinate shifts by one. In both cases, err is updated by dx and/or -dy to ensure that the comparison with e2 is accurate.
Once the pixels on the line are iterated through, and the new pixel coordinate matches that of the final vertex (x2, y2), then the code breaks out of the while loop and EdgeCrossesObstacle remains False.
Results:
When the script is executed, the walls are initially inflated by the radius of the robot to ensure safe navigation. Following this, 28 vertices are randomly generated within the environment, and their placement is confirmed by terminal output and a PNG file depicting the inflated walls and vertices. Each vertex is then checked for validity to ensure it lies within navigable space and not within any inflated walls. The edges connecting these vertices are also validated to confirm they represent feasible, obstacle-free paths. Once the valid vertices and edges are established, the A* algorithm is used to determine the optimal route from the robot's starting position to the predefined target, ensuring the shortest and most efficient path is selected.
With the roadmap generated, the robot's route is visualized in blue on the r-viz tool and the robot follows this route to navigate towards its destination. During navigation, an object is simulated in the environment to demonstrate the integration of local and global navigation strategies. Upon detecting the object, the robot dynamically adjusts its path to maintain a safe distance, using the next checkpoint as an interim target. After successfully maneuvering around the obstacle, the robot resumes following the global navigation path until it reaches its final destination. This sequence highlights the robustness of the navigation system, combining global and local strategies for efficient and safe travel through the environment.
Shown below is a screen recording of such simulations. Evidently, the use of the local planner means that the robot does not always stay exaclty in line with the blue path, which is not always a disadvantage since it needs to avoid obstacles, but it does mean that the error margin for reaching a checkpoint had to be relaxed. This is especially clear at the end of the simulation when the robot "reaches" the end goal, but stops short of the actual end point of the blue line. Although it is sufficient for this exercise, for the final restaurant challenge it would be important to optimize this so that the robot actually makes it to the final coordinate since it will need to position itself next to tables. A possible method for resolving this issue would be to have an if statement checking to see if the next waypoint is actually the final destination or a table, and in the case that it is then the error margin for reaching that point could be made stricter.
Test on map_compare for global and local planner with an added obstacle.
Questions
How could finding the shortest path through the maze using the A* algorithm be made more efficient by placing the nodes differently? Sketch the small maze with the proposed nodes and the connections between them. Why would this be more efficient?
Finding the shortest path through the maze using the A* algorithm can be made more efficient by placing the nodes at the locations in the map where the robot has to take the decision of taking a turn or maintain a straight line. So, the new proposed nodes should be placed at key points such as corners and intersections where paths branch, rather than at every possible point along the path. This reduces the number of nodes the algorithm must evaluate, speeding up the computation while maintaining accurate path representation. By placing nodes at strategic locations, navigation between nodes becomes straightforward, and the algorithm can focus on critical decision points, thereby enhancing overall path planning efficiency.
Would implementing PRM in a map like the maze be efficient?
Implementing PRM in a maze would not be efficient. The maze includes a lot of small corridors and very little open space, causing PRM difficulty when adding valid edges. To make it a viable option the amount of vertices should be increased substantially and/or the random distribution of vertices should be changed to an uniform distribution.
What would change if the map suddenly changes (e.g. the map gets updated)?
In the case where an avoidable obstacle, like a small block, suddenly appears the local navigation makes sure to that the robot goes around it. In the case where an unavoidable obstacle, like a road block, appears the robot should first stop moving then update the map and last plan a new path with the global navigator.
How did you connect the local and global planner?
To integrate the VFH local planner into the global planner, the method described in the VFH section was used (using the waypoints as goal coordinates for the getClosestFreeAngle() function). The "main.cpp" file already had the creation of the planner set up, and so, the simple local planner was replaced with the code from the "Local_Nav.cpp" file with minor edits such as directory paths and setting the robot's starting coordinates to specific x and y coordinates.
Test the combination of your local and global planner for a longer period of time on the real robot. What do you see that happens in terms of the calculated position of the robot? What is a way to solve this?Global and local navigation test on Hero.
During the testing session with Hero, the combination of the global and local planner worked well enough for the robot to avoid getting too close to the walls. However, there were some points where the calculated position of the robot lost its accuracy and the code eventually failed to update its waypoint to the final coordinate. As a result, although Hero made it to the end of the map it turned around to get back to the previous waypoint which was still set as the goal position for the local planner. This could also be due to the set error margins for how close the robot needs to be to a waypoint for the global planner to progress to the next one in the path. Such issues were also sometimes present when running the simulations with an obstacle placed right before a waypoint, and would prevent the robot from ever progressing to the next waypoint. One fix would be to implement a trigger that tracks the behaviour of the robot and if it notices that the robot is stuck (either not moving or moving in circles) close to the waypoint then it will just tell it to progress to the one after.
Run the A* algorithm using the gridmap (with the provided nodelist) and using the PRM. What do you observe? Comment on the advantage of using PRM in an open space.
As shown in the screen recordings below, the movement of the gridmap is very inefficient and staggered. This would be due to the rigid structure of the points set in the grid map. On the other hand, the PRM's random generation of vertices in combination with settings like minimum distance between points ensure that paths can be more direct and spread out. As a result, the robot is able to traverse and complete an open space map in less time.
A* algorithm using the gridmap.
A* algorithm using PRM.
Localisation
Assignment 0.1
How is the code is structured?The main is of course the starting point of the software. It makes use of the resampler and the particlefilter. The resampler resamples the particlefilter. the particle filter runs the tasks of containing the particles and calculating the probability of them being right using the given robot data and world data.
What is the difference between the ParticleFilter and ParticleFilterBase classes, and how are they related to each other?ParticleFilterBase is the basic platform of the filter. the functions for populating and changing the filter are written here. ParticleFilter.h then inherits the functionality of particlefilterbase so different paramters of the base can be tested when they get added upon and changed in ParticleFilter
How are the ParticleFilter and Particle class related to eachother?Particle class holds all of the information of 1 particle. the ParticleFilters generates allot of particles where it can individually track the properties of each particle
Both the ParticleFilterBase and Particle classes implement a propagation method. What is the difference between the methods?the particle filter propagates the samples by running the propagation method of particle for each particle individually.
Assignment 1.1
Explain in a few concise sentences per item:
What are the advantages/disadvantages of using the first constructor, what are the advantages/disadvantages of the second one?uniform distribution covers particles over the whole map. the pro's are that the uniform distribution is a more simple algorithm. also when the location of the robot is unknown is scan's the whole map instead of a more defined area around the robot. this way it can find its probable location from over the whole map. the con is then that this is more computationally efficient because you spread over a larger area. Also the robot can find locations similar over the whole map where it would be in the wrong place like corners. with gaussian distributed the particles are spread with a higher likelihood of being around the last known location. the pro's are that the the filter then looks around its last known location, where it is more likely to find the robot than the other side of the map. this makes the filter more efficient because the particles are already more likely to be right. the con's are that if the initial location is unknown the robot has a hard time to find the actual location. no particles from the filter have a high likelihood of being the actual position. also when the location is lost it has a hard time recovering.
In which cases would we use either of them?when we don't know where we are it is better to use the uniform constuctor. this way we can find a initial position. when we then have a location we can better use a Gaussian constructor to more efficiently find the next locations of the robot.
Add a screenshot of rviz to show that the code is working
working distribution
Assignment 1.2
Explain in a few concise sentences per item:
Interpret the resulting filter average. What does it resemble? Is the estimated robot pose correct? Why?
the result is an arrow in the middle of all distributed particles. it is the average of all the particles x,y position and theta rotation. The robot pose is not correct because this is just the first initial guess. the working filter should look at particles near the actual robot and give those particles highers likelihoods of being true.
Imagine a case in which the filter average is inadequate for determining the robot position.
in this case the filter won't be adequate to find the actual robot position. no particles have a high likelihood to be the robot so the filter doesn't make a good guess. if its close particles closer to the robot would have a higher likelihood and then the filter would eventually find a position. but when it is completely wrong we can temporarily switch to a uniform filter over the whole map.
the green summing arrow is also visible in the image from 1.1 because the assignment were done simultaneously.
Assignment 1.3
Explain in a few concise sentences per item:
Why do we need to inject noise into the propagation when the received odometry infromation already has an unkown
noise component?
Due to the error in the odometry data because of wheel slip or error in the encoders it’s possible that the estimated robot position drifts away from actual position. What’s why we add a little noise to the estimated position so there is always a particle that matches the actual robot position.
What happens when we stop here, and do not incorporate a correction step?
The filter will follow the position of the robot just like normal odometry would but way more computationally inefficienct. it would even be worse because of the chance that the randomness and noise in samples let the average drift. Also the particles will distribute more over the map after a while with Gaussian.
working propogation of filter
Assignment 2.1
Explain in a few concise sentences per item:
What does each of the component of the measurement model represent, and why is each necessary.
there are 4 parts of the measurement model
hit probability (probability if it is the laser reading the wall that is found)
short probability (probability that laser finds reading that is not in the map)
max probability (probability that laser beam is just maxed out like when the laser points at a transparent or black surface)
rand probability (probability that measurement is completely unexpected)
all these probabilities are not only possible but necessary. this is because if you make the assumption that the laser beam is within only the hit probability you will get a low likelihood because more things can go wrong. if you also filter max,short and rand measurements more error is accounted for so the likelihood is more probable.
With each particle having N >> 1 rays, and each likelihood being ∈ [0, 1] , where could you see an issue given our
current implementation of the likelihood computation.
because the measurements are between 0 and 1 and there are allot of them almost all likelihoods will go to 0. this because with each iteration the likelihood is decreasing. this leads to skewed results.
Assignment 2.2
Explain in a few concise sentences per item:
Localization in simulation
What are the benefits and disadvantages of both the multinomial resampling and the stratified resampling?
Multinomial Resampling is simple and widely used but can lead to high variance.
Stratified Resampling offers reduced variance but is slightly more complex and computationally expensive.
With each particle having N >> 1 rays, and each likelihood being ∈ [0, 1], where could you see an issue given our current implementation of the likelihood computation?
Because the measurements are between 0 and 1 and there are allot of them almost all likelihoods will go to 0. this because with each iteration the likelihood is decreasing. this leads to skewed results.
Assignment 2.3
Explain in a few concise sentences per item:
How you tuned the parameters.
in params.json there were tunable parameters. in the beginning the results were quit slow. changing the number of particles greatly improved the speed of the filter.
in the beginning the filter looks confused about where the robot could actually be. we think this is due to certain particles being in positions where the vision. changing parameters like
standard deviation should resolve these issues because the particles are closer to the robot.
How accurate your localization is, and whether this will be sufficient for the final challenge.
the robot seems to know it's position very well in simulation. the real life test also shows promising results. here the angle of the robot is still not accurate enough for the final challenge.
an exact measurement is not available because there was no testing with the optitrack system. If the robot is navigated with only the mrc-teleop and the computer, the robot doesn't crash in real life. here the x,y position is surely accurate enough for the challenge.
How your algorithm responds to unmodeled obstacles.
the filter is working very well with the different probabilities. the map resembles the real life map but there are big differences. due to the time limit an unmodeled obstacle wasn't properly tested but shifting around some panels of the map don't seem to disturb the position.
Whether your algorithm is sufficiently fast and accurate for the final challenge.
the position updates itself well to the position in the map. it does this with about 5Hz. the algorithm shows sufficient speeds to deliver food at tables.
live testing localisation
System Architecture
Diagram of the system requirements for the final challenge.Diagram of the data flow.State flow diagram.
Final Restaurant Challenge
A main point of interest for the final evaluation will be: the justification behind your design choices and a reflection on them. why did you choose the techniques that you did, what test did you perform to validate them, were the results as expected, and did you change anything on the basis of these results?
Introduction and Challenge Analysis
Almost like a recap of our presentation (what challenges were the most important for us to tackle)
How we approached the challenge as a group (what was left to do after completing the exercises)
Approach/System Integration
Implementation of stateflow/dataflow logic (pseudo code) with clear explanation of how choices are motivated by the final challenge
Structuring of the files and directories in the main branch
Creation of final main.cpp file which runs everything
Simulation/experimental videos of results from final testing sessions
Local Navigation
Final selection of VFH over DWA
Improvements made to meet the requirements of the final challenge
Explanation of the algorithms (refer to the previous descriptions or explain any new algorithm changes)
Simulation/experimental videos of results
Global Navigation
Reasoning for choosing PRM and A* algorithms
Improvements made for the final challenge (directional penalty, readjustment of PRM knobs to find possible paths, replanning/Marc's function)
Explanation of the algorithms (refer to the previous descriptions or explain any new algorithm changes)
Simulation/experimental videos of results
Localization
Reasoning for choosing particle filter
Improvements to fix strange behaviour of particle filter (usage of different maps, which maps worked and which didn't, testing of different numbers of particles)
Results & Discussion
Final results from demo day
Behaviour of robot (what was expected, what was unexpected, explanations for what went well/badly)
Possible improvements (path replanning, table orientation, etc.)
































.gif)


