Mobile Robot Control 2024 HAL-9000
Group members:
| Name | student ID |
|---|---|
| Salim Achaoui | 1502670 |
| Luis Ponce Pacheco | 2109417 |
| Nienke van Hemmen | 1459570 |
| Aniek Wigman | 1463535 |
| Max Hage | 1246704 |
| Max van der Donk | 1241769 |
Exercise 1: Non-crashing robot
For the first exercise, the goal was to ensure that the robot does not move through walls in the simulation and not crash into the walls in both the simulation and the real world. To solve this matter, there were multiple solutions. The first solution collects all of the data from the lasers and stops the robot when it reaches a wall. A second solution uses the data of the bumper to detect a collision. These solutions were then tested on the robot in real life. After testing, it became clear that, although stopping the robot was not an issue, the robot was not able to move along a wall in parallel. This issue occurred since the sensor data was taken uniformly. So on all sides, the robot would stop with the same threshold. Therefore, a third solution was made that took the orientation of the sensor data into account for the robot to move alongside a wall. The details of the solutions will now be covered in more detail.


Solution 1
For the first solution, we utilize the laser data that the robot has. This contains data as to how far a wall or object is to the robot at a certain angle. For each angle, we check whether the robot is too close to an obstacle, thus within range x. If it is, it stops moving. Else, it keeps on going forward.
Solution 2
For this solution, the robot utilizes bumper sensor data to detect collisions. When the bumper is pressed, indicating contact with an obstacle, the robot immediately halts and then reverses direction until the bumper is released. For the final challenge we will utilize both laser data and bumper data to avoid crashes.

Solution 3
This solution is an expansion of solution 1. In this expansion, the size of the robot is taken into account. This solution was created after testing the robot physically. We came to the realisation that the size of the robot is not taken into account. Therefore, in the script an offset was included such that the body of the robot does not bump into the wall. Using the line: scan.ranges[i] < minDist + robotWidth*abs(sin(currentAngle) we introduce an offset by adding the sinusoid of the current angle, which is approximately the circular body of the robot. Because the laser of the robot is approximately in the middle of its body, the sinusoid creates a proper offset to not bump into a wall anymore.
Questions:
- Compare the different methods to one another. What situations do these methods handle well? Is there one "Best" method?
- The best method was by far the 3rd solution. Once tested in real life you can see the caveats you can fall into when just using the simulation software. Therefore, by adding an accounting mechanism for the robots size, gives the best outcome. The best method is definitely the 3rd solution. However, there might even be improvements to it, yet since just stopping is so simple this is the best.
- On the robot-laptop open rviz. Observe the laser data. How much noise is there on the laser? What objects can be seen by the laser? Which objects cannot? How do your own legs look like to the robot.
- The amount of noise in the laser data, visually assessed, is present. In the gif below it can be seen, where the red lines, the laser data of the robot, are flashing. This means that it is changing each iteration, meaning there is noise in the data. However, the overall location of the laser data is accurate. The objects that can be seen by the laser are the walls, but also the doors. So solid, non transparent objects can be detected by the laser. There also is a blind spot behind the robot, where it cannot see anything. On top of that, transparent objects are harder for the robot to detect due to the laser going through the object. For the robot, your own legs are poles. Due to your feet being under the laser, they are not detected and thus can drive into your feet.
Video 4: Overview of the laser data's range and noise levels. The flashing of the red lines (laser data) shows noise in the sensors.
- The amount of noise in the laser data, visually assessed, is present. In the gif below it can be seen, where the red lines, the laser data of the robot, are flashing. This means that it is changing each iteration, meaning there is noise in the data. However, the overall location of the laser data is accurate. The objects that can be seen by the laser are the walls, but also the doors. So solid, non transparent objects can be detected by the laser. There also is a blind spot behind the robot, where it cannot see anything. On top of that, transparent objects are harder for the robot to detect due to the laser going through the object. For the robot, your own legs are poles. Due to your feet being under the laser, they are not detected and thus can drive into your feet.
- Take your example of don't crash and test it on the robot. Does it work like in simulation? Why? Why not? (choose the most promising version of don't crash that you have.)
- When testing don't crash, we came to know that the physical robot size is not taken into account in the simulation. In the simulation, the robot did stop as soon as it came close to a wall, but the physical does not always do this. It crashed into the walls as soon as it was not directly in front of the laser, due to the circular shape of the robot that is not taken into account. When editing the software (solution 3), it did not crash into the walls anymore.
- If necessary make changes to your code and test again. What changes did you have to make? Why? Was this something you could have found in simulation?
- We changed the code to incorporate the size of the robot using
robotWidth*abs(sin(currentAngle)and adding it to the minimal distance to the robot in solution 3. This adds a circle of the robots laser data such that the distances were approximately correct from the robots body.
- We changed the code to incorporate the size of the robot using
- Take a video of the working robot and post it on your wiki.
- see video 1.
- Testing of don't crash. As a second exercise, the don't crash algorithm has to be tested in the 2 maps provided. The videos are shown below. In the first video, we can see that the algorithm stops nicely in front of the wall. For the second algorithm, we see that the robot stops even though it can pass, the wall just came too close and it made the robot stop. This is something to work on in the future, because if it is not moving toward the wall, we should be able to just drive parallel to the wall cause we won't crash into it.

 |
 |
bugs and fixes
The bug that occurred is mainly not being able to drive closely to a wall in parallel. This problem can be fixed through looking at the direction we are driving to and as long as we are not driving towards the wall, it should just keep driving. However, we decided not to implement this, because local navigation will likely account for this.
For local navigation, 2 different solutions had to be introduced for the restaurant scenario. We have chosen for artificial potential fields and vector field histograms because these solutions seemed the most robust to us. In this paragraph the 2 solutions will be explained.
Artificial potential fields
Artificial potential fields are self-explanatory: they portray the potential fields around an object. A field can either be repulsive or attractive. The reason for being artificial is because these fields do not exist in the real world. In the real world, an object does not push the robot away or pull the robot towards it. In a simulation, however, artificial potential fields can be drawn such that a robot avoids certain objects and gravitates toward others. In this particular case, the robot is drawn towards the goal and repulsed by obstacles that are in its way. The distance between the robot and the goal or obstacle dictates the strength of the field around it. When an obstacle is close, for example, the repulsion force should be higher than the attraction force and high enough to repulse the robot away from the obstacle. This dependency on distance can be seen in the formulas for the two fields. For the implementation, the following source was used: [1]
The artificial attraction potential is dependent on an attraction constant and the distance between the robot and the goal.
[math]\displaystyle{ U_{\text{att}}(x) = \frac{1}{2} k_{\text{attr}} \rho^2 (X, X_g) }[/math]
With the following:
- [math]\displaystyle{ K }[/math]: positive scaling factor.
- [math]\displaystyle{ X }[/math]: position of the robot.
- [math]\displaystyle{ X_g }[/math]: goal of the robot.
- [math]\displaystyle{ \rho(X, X_g) = \| X_g - X \| }[/math]: distance from robot to goal.
This is used in superposition with the repulsion field created with the following formulas:
The repulsive potential field is described by:
[math]\displaystyle{ U_{\text{rep}}(X) = \begin{cases} \frac{1}{2} \eta \left( \frac{1}{\rho(X, X_0)} - \frac{1}{\rho_0} \right)^2 & \text{if } \rho(X, X_0) \leq \rho_0 \\ 0 & \text{if } \rho(X, X_0) \gt \rho_0 \end{cases} }[/math]
- [math]\displaystyle{ \eta \gt 0 }[/math]: positive scaling factor.
- [math]\displaystyle{ \rho(X, X_0) }[/math]: the minimum distance (robot and obstacles).
- [math]\displaystyle{ \rho_0 }[/math]: distance influence imposed by obstacles; its value depends on the condition of the obstacle and the goal point of the robot, and is usually less than half the distances between the obstacles or shortest length from the destination to the obstacles.
Using these formulas, the following artificial potential fields were created for all maps.

From this figure, the weakness of the artificial potential method becomes apparent: the 'local minimum' problem. This causes the robot to get stuck in places were the minimum potential does not result in a path towards the goal. There are methods to try and deal with them, but this is a fundamental problem with the technique.
For the implementation, not [math]\displaystyle{ U }[/math] is used but [math]\displaystyle{ F }[/math] to drive the robot into the direction of the potential: The attractive potential field function is described by:
[math]\displaystyle{ F_{\text{att}} = - \nabla [U_{\text{att}}(X)] = - k \rho (X, X_g) }[/math]
The repulsive force field is described by:
[math]\displaystyle{ F_{\text{rep}} = \nabla [U_{\text{rep}}(X)] }[/math]
[math]\displaystyle{ F_{\text{rep}}(X) = \begin{cases} \eta \left( \frac{1}{\rho(X, X_0)} - \frac{1}{\rho_0} \right) \frac{1}{\rho^2(X, X_0)} \hat{\rho}(X, X_0) & \text{if } \rho(X, X_0) \leq \rho_0 \\ 0 & \text{if } \rho(X, X_0) \gt \rho_0 \end{cases} }[/math]
The added problem is that the robot cannot drive in any direction at any time. Therefore we have programmed it such that it rotates towards the direction before driving it with the force amplitude calculated.
In the figures bellow it can be seen how the artificial potential field method performed on the given maps.
 |
 |
 |
 |
bugs and fixes
So the main bugs with the artificial potential field were the local minima. These local minima were too much of an issue to solve in time and therefore the decision was made to, instead of fixing the code, not use this algorithm anymore.
Answers to Questions Artificial Potential Field
- What are the advantages and disadvantages of your solutions?
Advantages:
- Simplicity in implementation and understanding.
- Effective for basic obstacle avoidance and goal seeking.
Disadvantages:
- Susceptible to local minima, where the robot can get stuck.
- Not effective in highly dynamic or complex environments.
- What are possible scenarios which can result in failures (crashes, movements in the wrong direction, ...) for each implementation?
- For example, set the target position in an obstacle and let the robot try to get to the target; what happens? The robot may get stuck or oscillate around the obstacle.
- Another example: Narrow passages can cause the robot to get stuck due to strong repulsive forces from both sides.
- How would you prevent these scenarios from happening?
Possible solutions include:
- Implementing a path planner that re-evaluates the route if the robot gets stuck.
- Using a combination of potential fields and other algorithms like A* or Dijkstra’s algorithm for global path planning.
- Introducing randomness or perturbations in the path to escape local minima.
- For the final challenge, you will have to link local and global navigation. The global planner will provide a list of (x, y) (or (x, y, θ) ) positions to visit. How could these two algorithms be combined?
The combination could be implemented as follows:
- The global planner (e.g., A* algorithm) calculates a rough path from the start to the goal.
- The local planner (artificial potential fields) is used to avoid obstacles and refine the path by guiding the robot between the waypoints provided by the global planner.
- This hybrid approach ensures that the robot follows an efficient path while dynamically avoiding unforeseen obstacles. A good thing to take into account is the balance between global and local navigation. By placing a lot of nodes in the graph of global navigation, the local planner does not have to do much. The other way around, with less nodes the local planner would dominate. In artificial potential fields, having a more influential global planner would be wise, to steer away from (quite literally) local minima.
Vector Field Histogram

 Figure 2: Visualization of the occupation map, created from the laser data. The values shown are based on the distance from the robot. The map below is what the occupancy map is based on.
Figure 2: Visualization of the occupation map, created from the laser data. The values shown are based on the distance from the robot. The map below is what the occupancy map is based on.Vector Field Histograms is a method to locally navigate through a space. It uses a map matrix and a polar histogram to determine where the robot can move to get to the goal. The map matrix stores cells which say that they are either occupied or not. The value in those squares then indicate the certainty that the cell is an obstacle. This map moves with the robot as an active window, where the cells in the map matrix are constantly updated just like the polar histogram which is based on the map matrix. Using the laser data of the robot, the height of the bins of the polar is determined and it is smoothed. Finally, a valley between the curves is chosen to move towards to.
Summarizing, for vector field histograms, 2 major components had to be created. Firstly, the translation from the laser data to a map that contains the coordinates of the obstacles together with a certainty value and a polar histogram, from which a minima should be chosen as direction to continue moving. These components will be explained now. Note that the x, y and angle of the robot are kept track of globally.
Obstacle map
The obstacle map is created by defining a matrix with the height and width of the active window. Since each run items more in the map, we clear the map at the beginning of the run. Then, we look at the laser data and compute the coordinates of the obstacle using the distance retrieved from the laser data and the angle we globally keep track of.
[math]\displaystyle{ x = \frac{\sin(\theta) \cdot laser\_data[i]}{CELL\_SIZE} }[/math]
[math]\displaystyle{ y = \frac{\cos(\theta) \cdot laser\_data[i]}{CELL\_SIZE} }[/math]
Using these coordinates, in the map, the distance of the robot to the wall is put to indicate the risk factor. This value is then normalized to be in range [1,10] . The robots size is kept into account in this distance aswell. This is done by dilating the walls in the sensor map to the robot width such that it cannot bump into the walls. The laser data map and the map its supposed to represent are depicted in figure 2 and 3.
Polar Histogram
In order to create the polar historam, the article 'IEEE Journal of Robotics and Automation Vol 7, No 3, June 1991, pp. 278-288' is used, further refered as [1]. The polar histrogram is made, using the histrogram grid from the previous paragraph. An active window is chosen, with a certain width [math]\displaystyle{ w_d }[/math]. We assume a rectangular grid, hence a [math]\displaystyle{ w_d }[/math] x [math]\displaystyle{ w_d }[/math] grid. Also, it is assumed that the robot is exactly in the middel of this active grid. In order to make the polar histogram, the follow parameters are used:
[math]\displaystyle{ a, b }[/math], which are positive normalizing constants;
[math]\displaystyle{ c_{i,j}^* }[/math], which is the certainty value of cell [math]\displaystyle{ i, j }[/math];
[math]\displaystyle{ d_{i,j} }[/math], which is the distance from the robot to cell [math]\displaystyle{ i, j }[/math];
[math]\displaystyle{ m_{i,j} = (c_{i,j}^*)^2(a-bd_{i,j}) }[/math], which is the magnitude of the obstacle vector at cell [math]\displaystyle{ i, j }[/math];
[math]\displaystyle{ x_0, y_0 }[/math], which are the coordinates of the robot;
[math]\displaystyle{ x_i, y_i }[/math], which are the coordinates of cell [math]\displaystyle{ i, j }[/math];
[math]\displaystyle{ \beta_{i,j} = atan(y_0 - y_i / x_0 - x_i) }[/math], which is the angle between the robot and cell [math]\displaystyle{ i, j }[/math];
Secondly, a vector is made which stores NUM_BINS amount of items. The value of NUM_BINS is determined by size of angles. In other words, if the entire 360 degrees is divides into increments of 5 degrees, NUM_BINS would be 72. In this vector, the first element corresponds to 0 to 5 degrees, the second element 5 to 10 degrees, and so on. The magnitude of each cell is added to the correct index of the vector. To determine the correct index, the relation
[math]\displaystyle{ k = int(\beta_{i,j}/\alpha) }[/math]
is used. This results in a vector with higher values at the indices corresponding to obstacles in that direction. Afterwards, a smoother function is used, since the angle segregation imply some false obstacle-free directions. At last, the vector is normalized to a value of 1. An example of a polar histogram in a small corridor with an obstacle in front of the robot is shown in the figure below.
Once the polar histogram is made, it is possible to determine the optimal steering angle. To do so, multiple steps need to be done. The algorithm does this in the following sequence:
- Determine the valleys which are bellow a certain threshold. This threshold is introduced in [1], in order to avoid steering towards small corridors. A valley is a 'range' between objects. By looking at the figure below, the possible valleys are (-80, -40), (40, 80) and (100, -100) (with wrapping). Note: in the application we used 0 to 360 degrees.
- Determine the valleys which is closest to the target goal. For example, is the target angle is -60, the valley (-80, -40) would be chosen, as the target lies in this valley. If the target is 30, the valley (40, 80) is chosen, as the border of 40 is closest to this target angle.
- From the chosen valley, determine the best angle. If the targer is within the valley, return the target. If the target is not within the valley, chose an angle which is as close as possible to the target without driving into a wall. Here, a distinct in made between wide and narrow valleys. A wide valley is has a certain width of s_max. If the optimal valley exceeds this width, and the target angle is not in the valley, the new steering angle will be determined as [math]\displaystyle{ \theta = (k_n + s_max) / 2 }[/math]. Here, k_n is the border which is closest to the target. This enables the robot to drive close to walls in a wide valley. If the valley is narrow, hence not wider than s_max, the exact middle is chosen as the new steering angle [math]\displaystyle{ \theta }[/math].

Speed Control
Once the steering angle is determined, the robot should take a certain action. To do so, it looks at its own angle and the steering angle resulting from the vector field histogram algorithm. If the angle is small (less than 23 degrees), the robot can still drive forwards and also turn simultaneously. However, if the steering angle is larger than 23 degrees, the robot stops and first makes the turn. This is done in order to enable the robot to make large turns in narrow sections. The 23 degrees can be tuned to a preferred behaviour. If the robot has arrived at the goal within a certain distance (for example 0.2 meters), the robot has arrived and the robot goes to either the next goal of stays if it has no further goals.
Bugs and fixes
One bug in this algorithm, is that the robot starts choosing between two angles rapidly. One of the causes for this, was that the robot could not detect anything in de blind laser spot (the range in which the laser does not detect an object). Therefore, the robot could sometimes steer towards the blank spot, see that there is an obstacle, steer back, and this goes on repeatedly. To fix this issue, a virtual obstacle is placed in the blind spot of the robot. For this reason, the robot will never choose to search for a steering angle in its blind spot. If it wants to steer in its blind spot, it first needs to turn and scan that spot. This solution worked well for most of the situations where the bug occurred, but not all of them. There are still situations where two angles are chosen rapidly after each other. This mainly happens when the steering goal is far away and the robot very close to an object. We hope to solve this with the global planner.
Another solution for getting stuck, is shortening the horizon of the active grid. The laser-finders have a very large range. The map which is made from the laser finders is 4 x 4 meters. However, if the entire map is chosen, the algorithm sometimes can get stuck, i.e. it sees no valleys. To solve this, we can tune the size of the active grid. The video which are shown are with an active grid of 1 x 1 meters. This enables less interference of walls/obstacles which are far away.
Videos




These videos (7-9) are tests of the vector field histogram implementation in the different maps provided. It seems to behave properly, but there are still some minor bugs to be solved. In video 10, we see the real life testing of the robot. We see that it nicely avoids the obstacles and that it goes towards the goal we set. However, when testing the robot in other cases, it sometimes gets stuck in between 2 choices where it jitters between these 2 options. We have tried implementing a hysteresis, but this only worked for small angles and not really for bigger angles, which were also occurring. Other than that, we tried implementing a cost function that also takes in the previous angle, the goal angle and the closest angle. This also did not work.
The following link (https://youtu.be/VTsmuJFkQ40) shows the video on the simulation of the local navigation, as well as some real life testing. The previous explained bug happens at map 3. It shows that the robot starts shacking between two steering actions. Note that this not always happens, as in an example shown in the top videos with the additional printed map. It is very sensitive to starting positions and active fields. This is hopefully solved when the global navigation is used. In map 4, this bug does not occur. This is due to the fact that there is an extra box, which disables the option to choose between two angles. The real testing shows that the robot can navigate around a corner with some obstacles.
Answers to Questions Vector Field Histogram
- What are the advantages and disadvantages of your solutions?
- Advantages: Our solution is relatively robust and can usually find the route that it should take in an environment. It is intuitive as well, the polar histogram is a logical way to think of obstacles getting in a robots way.
- Disadvantages: Vector Field Histogram has a problem with narrow corridors. This is because the polar histogram can sketch it as if there is no passageway (depending on the bin size of the polar histogram). Another problem we encountered was that the robot could not choose between two valleys and kept switching between those two options.
- What are possible scenarios which can result in failures (crashes, movements in the wrong direction, ...) for each implementation?
- Narrow corridors.
- 2 paths that are equally as good will result in the robot not being able to decide between one of the passages.
- How would you prevent these scenarios from happening?
- For narrow corridors, we could introduce more bins for the polar histogram such that the map is more refined and thus can spot smaller corridors.
- Hysteresis could be introduced to fix the 2nd problem. Another implementation could be to introduce a cost function that not only takes the goal position into account but also the closest angle and the previous angle we have chosen. This way, there is another factor that can influence the choice, meaning that the chance to have an equal cost in 2 angles is smaller.
- Another (and best) option, is to solve these problems with the global planner. If the nodes are close to each other, the local planner will hopefully not get stuck. In addition, we will try to implement a debugger, which detects of the robot gets stuck. If this happens, the robot will indicate it is stuck and an action has to be taken (which action is explained in the global planner).
- For the final challenge, you will have to link local and global navigation. The global planner will provide a list of (x, y) (or (x, y, θ) ) positions to visit. How could these two algorithms be combined?
- For our current implementation, we can give the robot a goal position towards which it will drive. These points for the robot to drive to are the nodes provided by the A* algorithm. These coordinates will serially driven towards. Once the robot cannot find a path for an amount of time or it discovers no path towards the node, it should consult the global planner again. The global planner should remove the node from the graph and find another path with the A* algorithm again, for the robot to follow. So the local planner will drive from node to node, in order to get to the goal. As mentioned, if the local planner gets stuck on a node, a possibility is to remove that node and move to the next node, which the robot hopefully can reach. There is also a balance here to be decided on, as talked about in artificial potential fields. For this implementation, it seems that the global planner and local planner can work together with each getting 50% of the job. So, this means we can space the random nodes more in global navigation and thus rely more on the local planner. However, the local planner still needs sufficient instructions from the global planner in order to not get stuck.
The goal of the global navigation exercise consists of three parts. First of all, apply the A* algorithm to find the shortest path in a map which has nodes and edges. Secondly, to create a Probabilistic Road Map to generate the node list and connections for a given map. Finally, the global planner should be connected to the local planner. A framework for the implementation has been provided, in which several parts of code have to be added or adjusted. These added or adjusted parts of code will be elaborated on in the following sections.
A* implementation
For the A* star implementation, code has to be written such that a sequence of node IDs can be found that form the shortest path through the given map from start to the goal. To test the algorithm the map of a maze will be used. In the given code the initialization step and the codes main structure have already been provided. The exercises/parts to be completed are as indicated below.
1. Find in every iteration, the node that should be expanded next.
The node that should be expanded next, should be the node with the minimum f value, which takes into account the cost-to-come and the cost-to-go. Starting from the start node, while the goal is not reached yet, a while loop iterates through the open_nodes list and determines the f value. A parameter min_f_value and set to infinity, in the loop the f value of the current node is compared with this parameter min_f_value. If the f value of the current node is less than the min_f_value, the parameter is updated to the newly found minimal f value and the node ID is stored in nodeID_min_f. This node with the minimal f value is the node which should be expanded next.
2. Explore its Neighbors and update if necessary.
To explore the Neighbors of the current node, a for loop iterates through each neighbour node ID and checks whether this node is in the closed_nodes list. If it is closed this node is skipped. For the open neighbour nodes the new cost-to-come, the g value, is calculated as the cost to come to the current node plus the distance to the neighbour node which is done with the calculate_distance function. Next it is checked whether the neighbour node is open or if the new g value is lower than the current g value of the neighbour node. If this is the case neighbour node should be updated with the new g value and f value accordingly. Next the parent node is updated to the current node ID which will help in determining the path. In the end if the neighbour is not already in the open_nodes list, it is added to the list for evaluation.
3. Trace back the optimal path

Once the goal is reached, the optimal path can be determined. In order to trace back the optimal path, the path is reconstructed by starting at the goal node and tracing back to the start node using the parent nodes. So current_nodeID is initially set to goal_nodeID and in each iteration of the loop the node IDs are added to the front of path_node_IDs. This loop continues until the start node is reached. In the end the node IDs of the determined optimal path are printed in sequence.
For the provided small maze the optimal path is then determined to be as followed. Optimal path from start to goal: 0 -> 7 -> 12 -> 11 -> 10 -> 6 -> 5 -> 4 -> 9 -> 14 -> 19 -> 20 -> 21 -> 23 -> 29 -> 28 -> 34 -> 39 -> 38 -> 37 -> 33 -> 27 -> 26 -> 25 -> 32 -> 31 -> Goal
When comparing this path to the figure of the small maze, it can be concluded that the algorithm works properly to find the shortest path through the maze.
Probabilistic Road Map
The goal of this assignment is to generate a graph that represents a Probabilistic Road Map (PRM) for a given map. This graph consists of vertices and edges and can be used by the A* algorithm to create an optimal path of vertices from a start to a goal position. The exercises to be completed are elaborated below.
1. Inflate the occupied areas of the map (i.e., the walls) in order to account for the size of the robot.
In order to account for the size of the robot, a parameter robot_radius is defined in meters. This radius is then converted to pixels by dividing the radius by the resolution of provided the map. After this a kernel is created for the dilation operation. An ellipse is chosen which will be twice the radius of the robot in pixels to ensure the kernel is large enough. Since the default dilation operation expands white regions and we want to inflate the walls which are black, the colours of the map are first inverted. Then, the dilation operation is applied to the map with the use of the created kernel such that the now white walls are inflated. After this the colours in the map are inverted again. In the end this returns the original map with the inflated walls.
2. Write code that checks whether a new randomly placed vertex is a certain distance away from the existing vertices in the graph.
In order to write code that checks the minimum distance between vertices, first a parameter min_distance is determined. A for loop iterates over each vertex in the graph G and for each vertex the distance between that vertex and new_vertex is calculated with the use of the function distanceBetweenVertices. If the calculated distance is less than min_distance, the boolean acceptVert is set to false. This indicates that the new vertex is too close and thus should not be accepted.
3. Determine whether an edge between two vertices is valid
Whether an edge is valid is determined by two aspects. The first one is that the vertices are within a certain distance of each other. This is done with the function checkIfVerticesAreClose. For this a parameter max_distance is defined and similarly as before, the distance between vertices is calculated with the function distanceBetweenVertices. This distance is than checked with max_distance. If the distance is less than or equal to max_distance, the function returns true. Otherwise it returns false. This function is used further in the script to determine if an edge is valid.

Secondly, an edge is valid if it does not go through walls. This is checked with the function checkIfEdgeCrossesObstacle. The boolean EdgeCrossesObstacle is set to false and will be set to true if an edge crosses an obstacle. The Bresenham's algorithm is used to iterate over the pixels along the line segment between two vertices. It checks if any pixel along the line is an obstacle, the function returns true otherwise, it returns false. This function is used further in the script to determine if an edge is valid.
In the end a PRM is created as can be seen in the figure on the right. The PRM has inflated walls, randomly placed vertices which are in a range of distance from each other and edges which do not cross obstacles. Also numbers are printed next to the vertices which is convenient for visualization. The parameters robot_radius, min_distance and max_distance, together with the amount of vertices N, can be tuned to satisfaction.
- How could finding the shortest path through the maze using the A* algorithm be made more efficient by placing the nodes differently? Sketch the small maze with the proposed nodes and the connections between them. Why would this be more efficient?

Figure 6: Maze with efficiently placed nodes - Finding the shortest path through the maze could be made more efficient by placing nodes only on the points where the path changes directions or splits into multiple sections. In the figure to the right, the positions where nodes should be placed are indicated with red circles. It can be seen that way less nodes are used than before. The optimal path now consists of less nodes because straight parts are no longer divided by different nodes and edges.
- Would implementing PRM in a map like the maze be efficient?
- Implementing PRM on a maze would not be efficient. This is due to the fact that the PRM places random vertices on the map and draws edges between them. In the exercises a minimum distance was determined to make the placement of nodes more efficient, as well as a function that would check of the edges would be valid. Since the maze has a lot of occupied spaces by walls, the algorithm would struggle to place all the nodes. The parameters robot_radius, min_distance and max_distance, together with the amount of vertices N, can be tuned such that it would be possible for the algorithm to place vertices in the maze such that eventually, it could be used by the A* algorithm to find a path through the maze. However this would take a lot of trial and error and would definitely not be efficient.
- What would change if the map suddenly changes (e.g. the map gets updated)?
- The global planner is used to determine the optimal path for a map with a specified start and goal position. When the PRM is created and the A* algorithm is used to determine this path, the robot uses this path to drive towards the goal. If the map would suddenly change, so a road would be blocked with an obstacle for example, the global planner does not take this into account and the robot could possible crash into the obstacle. In order to prevent this the global planner should be connected to the local planner. This way if the map changes, this could be sensed by the global navigation and a new path could be determined in order to reach the goal.
- How did you connect the local and global planner?
- In order to combine the local planner and the global planner, the local planner needed to be updated. The first update is that it can update the next goal. It does this by driving towards a goal. If the goal is reached, the node counter increases, and the robot goes to the next node. If the robot cannot reach a node, a debugger should recognize it and delete the note. The local navigation should then be able to drive towards the next node, which hopefully it can reach. It is important to note that the robot does not reach the node exact, but it approximates the node within a certain reach. This enables the robot to use the global planner more a guide and let the local navigator really drives through the map.
- The second thing which needed to be done, was to write the vector field histogram into header files. This way, it can easily be included in the global planner. Currently, the vector field histogram is a header file which is included in the include map from the global planner.
- Test the combination of your local and global planner for a longer period of time on the real robot. What do you see that happens in terms of the calculated position of the robot? What is a way to solve this?
- The last time we tested, we used BOBO for the first time. It showed that the odom data and real position is pretty far off, especially when you turn and drive. Therefore, it crashed pretty early, since the real position in the world and the position in the script did not align anymore. To solve this, localization has to be used in order to approximate the robots location, based on the sensor data.
- Run the A* algorithm using the grid map (with the provided nodelist) and using the PRM. What do you observe? Comment on the advantage of using PRM in an open space.

Submission

- Upload screen recordings of the simulation results and comment on the behaviour of the robot. If the robot does not make it to the end, describe what is going wrong and how you would solve it (if time would allow), and
- In the video above a recording of the simulation results is shown. It can be seen that once the script follow_astar is started, first a PRM is created with vertices and edges. After this the A* algorithm determines the optimal path from the start to the end position and this is visualized in the simulation by the blue line. After this the robot will follow the path and reaches the end goal. It should be noted that this is with the provided path follower that was already in the script.
- In the video below, the same procedure is shown as above but this time with our own path follower implemented. It can be observed that the robot follows the given path but also cuts some corners. This is due to the fact that the path follower does not have to reach the nodes very closely, but in a given range. When the node is reached within the range, the robot will continue to the next node until the goal is reached.
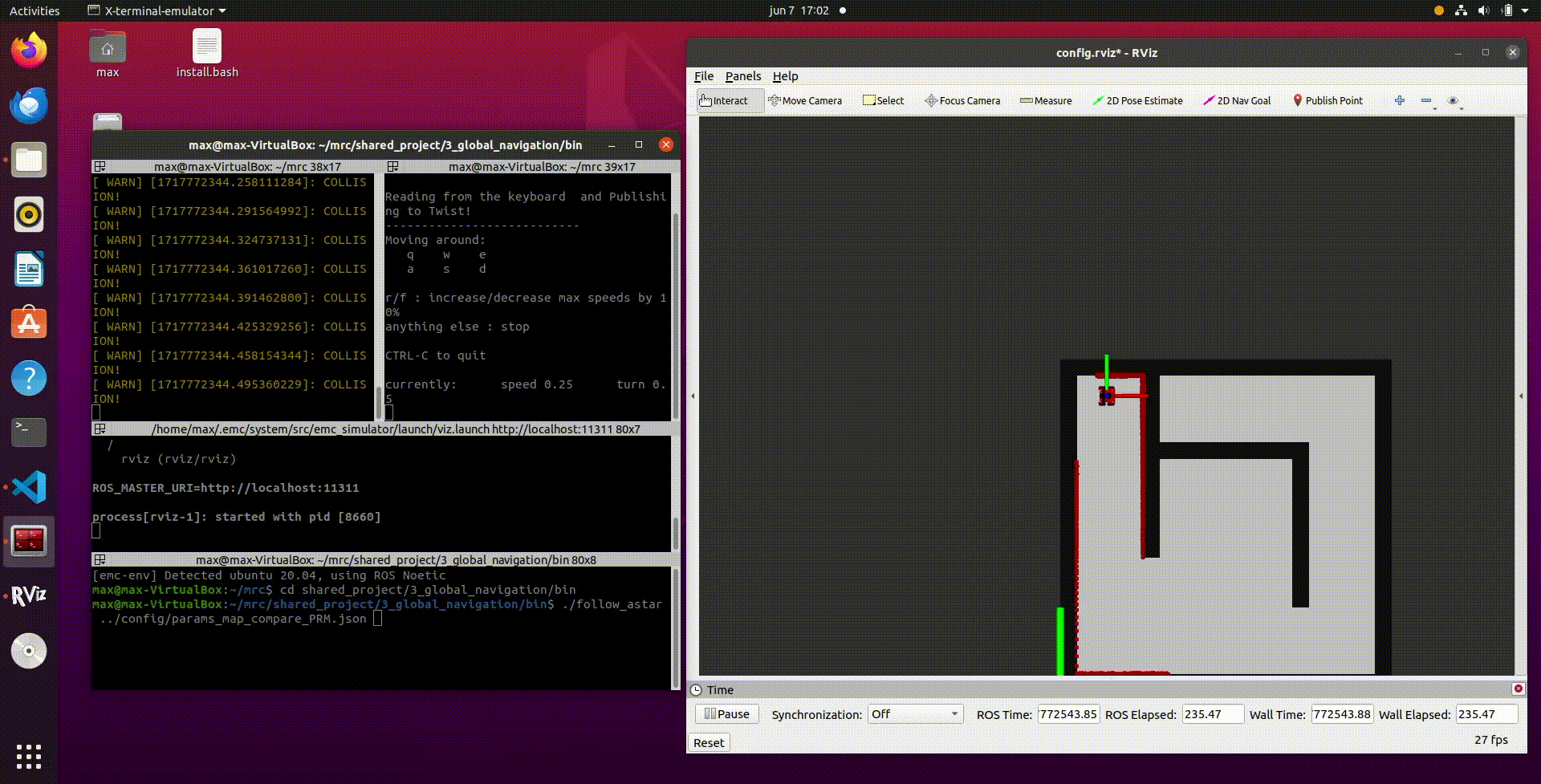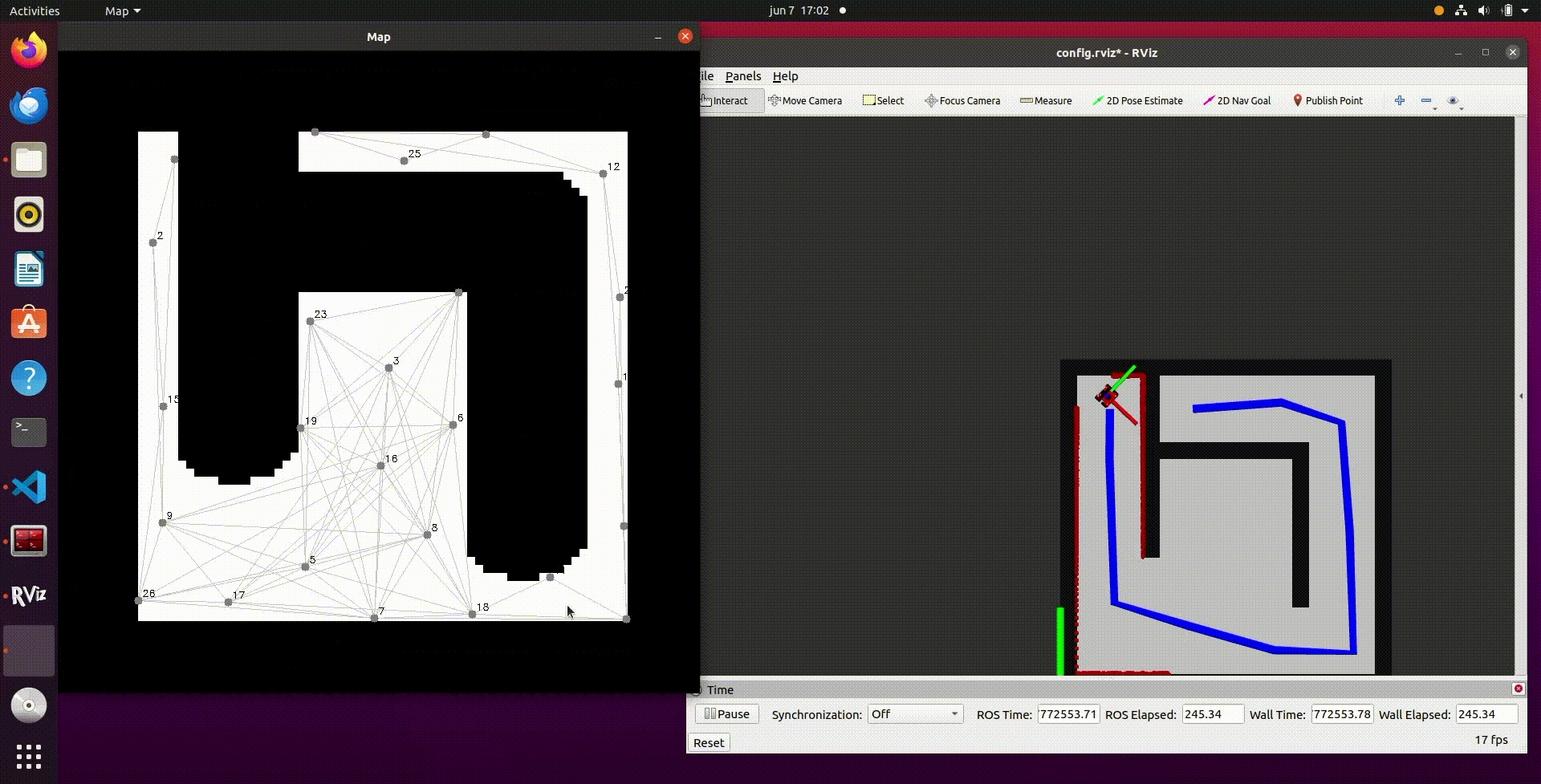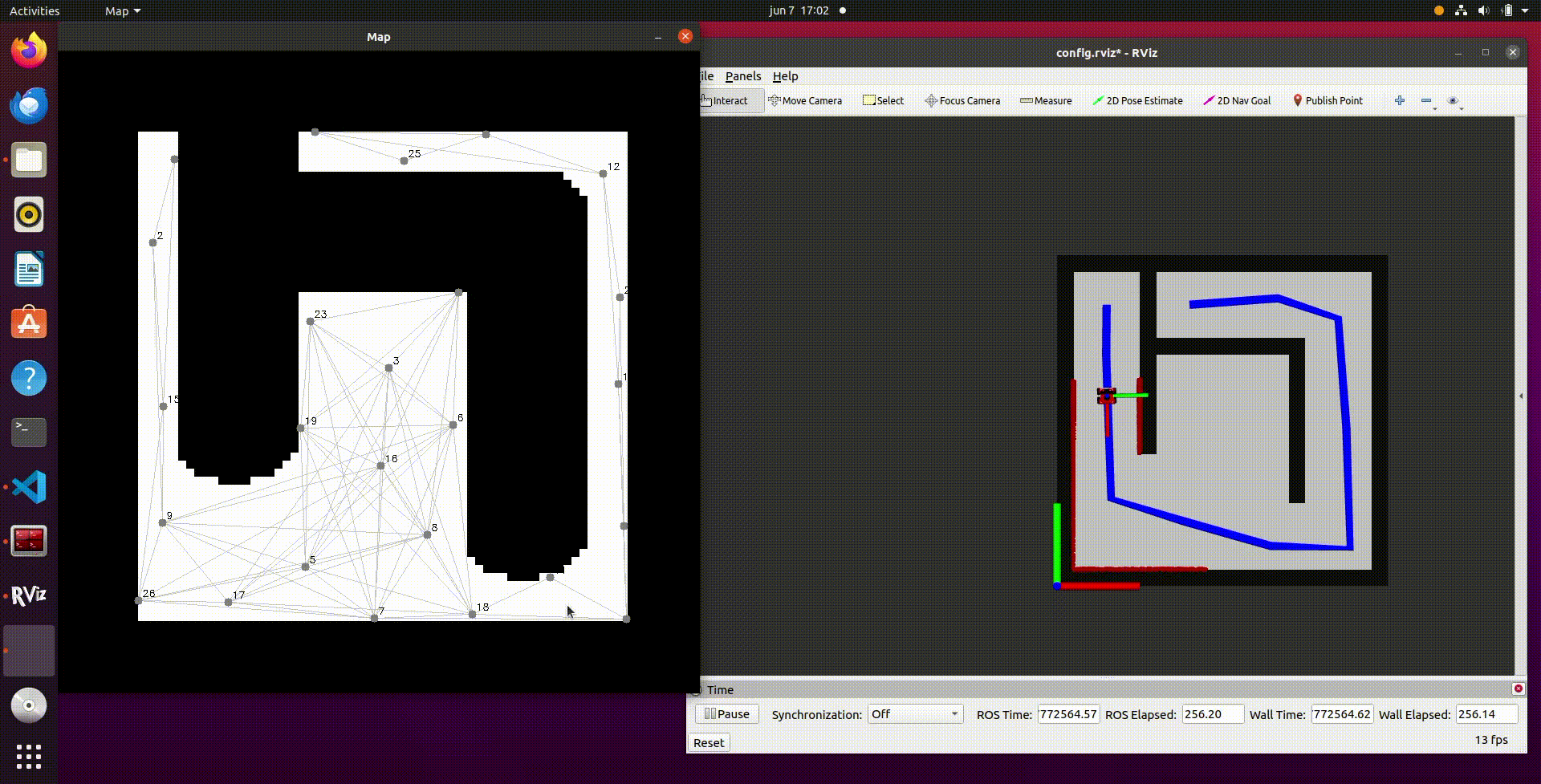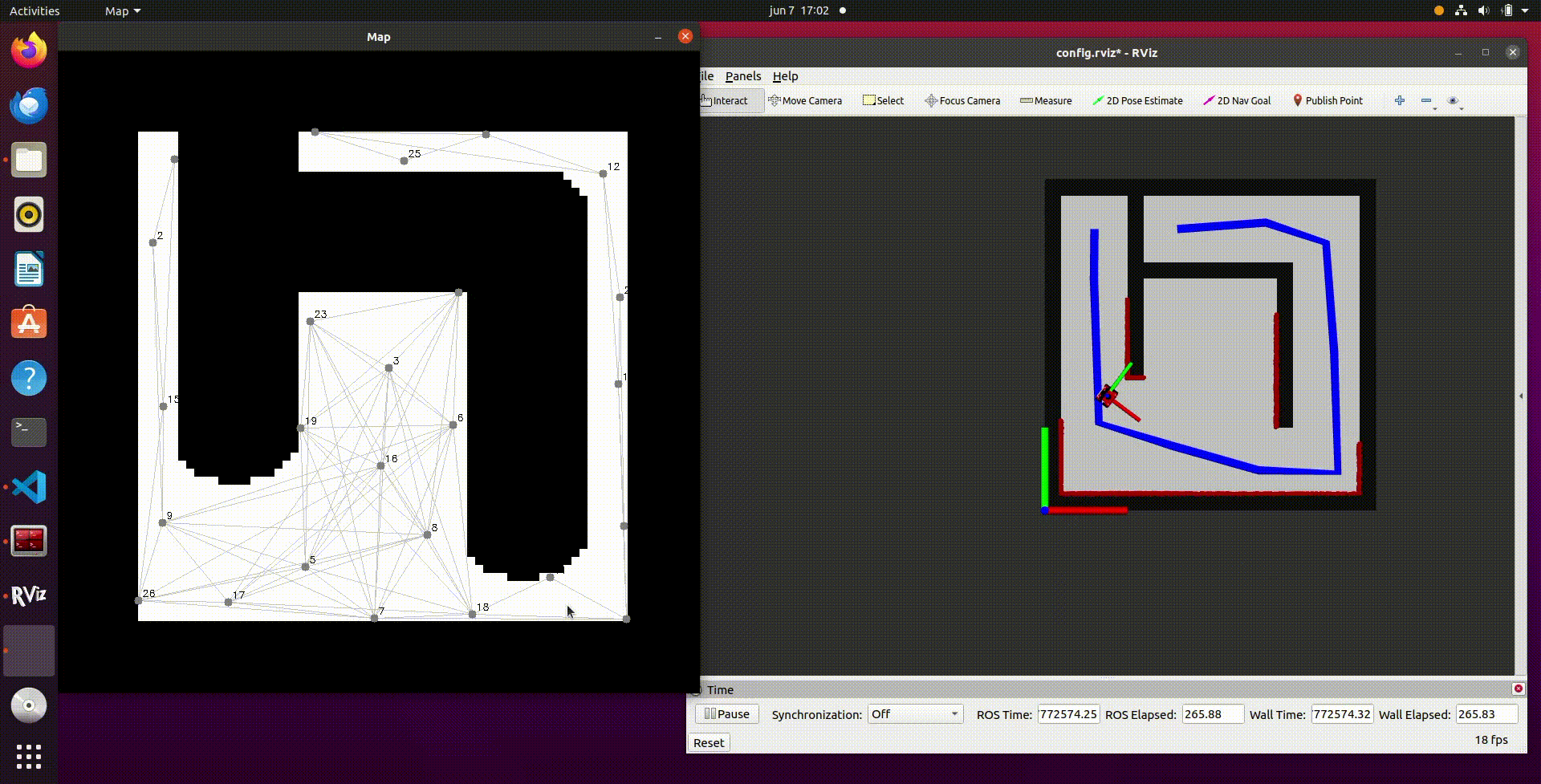
Video 16
- Upload video's of the robot's performance in real life (same as simulation videos), and comment the seen behavior (similar to the previous question).
- Sadly, we were not able to test the robot's performance in real life before the deadline of the assignments.

Exercise 4: Localization
0. Assignment introduction
0.1 Explore the code framework
- How is the code structured?
The code is divided into different files in order to have definitions and implementations separate from each other. Objects such as particles are used as seperate entities to keep track of the properties of each particle such as positions and weight.

- What is the difference between the ParticleFilter and ParticleFilterBase classes, and how are they related to each other?
The particleFilter is a higher level of abstraction compared to the ParticleFilterBase. The ParticleFilter derives functionality from the ParticleFilterBase class. This was implemented as such to be able to switch the employed method more easily.
- How are the ParticleFilter and Particle class related to each other?
The ParticleFilter uses the class particles to represent the particles as individual objects with their respective properties such as position and weight.
- Both the ParticleFilterBase and Particle classes implement a propagation method. What is the difference between the methods?
One is on the level of a single particle and the other one propagates the complete particle set by employing the class function propagate sample.
1. Assignments for the first week
1.1 Initialize the Particle Filter
- What are the advantages/disadvantages of using the first constructor, what are the advantages/disadvantages of the second one?
One initializes the particles uniformly distributed over the map and the other normally distributed over an expected position with a certain confidence. The second one makes better use of the particles but is only possible if the initial position of the robot is known. If this is not known the particle filter would benefit from the uniformly distributed method where the particles (position hypothesis) are dispersed over the space to eventually find its position within the map.
- In which cases would we use either of them?
The Gaussian method when an initial position is known. The uniformly distributed method when this is completely unknown.
- Add a screenshot of rviz to show that the code is working

1.2 Calculate the pose estimate
- Interpret the resulting filter average. What does it resemble?
By implementing the weighted mean we get the weighted average of all the particles
- Is the estimated robot pose correct? Why?
It is not yet correct since we consider all particles to be as likely not implementing the update step yet.
- Imagine a case in which the filter average is inadequate for determining the robot position.
The case where your initial position is far away from the actual robot initial position. Or when you have outliers in the case where you have a small amount of particles.
- Add a screenshot of rviz to show that the code is working

1.3 Propagate the particles with odometry
- Why do we need to inject noise into the propagation when the received odometry information already has an unknown noise component?
Introducing different noise values to each particle in a particle filter ensures diversity and prevents degeneracy.
- What happens when we stop here, and do not incorporate a correction step?
This results in increasing error and uncertainty in the estimated state, as the particles fail to adjust based on new data, leading to less accurate predictions over time.
- Add a screen recording of rviz while driving to show that the code is working

2. Assignment for the second week
2.1 Correct the particles with LiDAR
- What does each of the component of the measurement model represent, and why is each necessary?
- Local Measurement Noise: Represents inherent inaccuracies in sensor readings due to factors like sensor noise. It is necessary for modelling the probability of an observation based on the prediction and assigning the probability. The following formulas found in the slides were employed to assign this probability.
The probability p_hit for a given measurement given the prediction is defined by: ; [math]\displaystyle{ p_{hit}(z_t^k | x_t, m) = \begin{cases} \eta \mathcal{N}(z_t^k; z_t^{k*}, \sigma_{hit}^2) & \text{if } 0 \leq z_t^k \leq z_{max} \ 0 & \text{otherwise} \end{cases} }[/math]
- Unexpected Obstacles: Accounts for objects not present in the map, such as temporary items or new obstructions. This is modelled via exponential distribution.
The probability p_short for a short measurement is given by: ;[math]\displaystyle{ p_{\text{short}}(z_t^k \mid x_t, m) = \begin{cases} \eta \lambda_{\text{short}} e^{-\lambda_{\text{short}} z_t^k} & \text{if } 0 \leq z_t^k \leq z_t^{k*} \\ 0 & \text{otherwise} \end{cases} }[/math] The normalizing constant \eta is calculated as: ;[math]\displaystyle{ \eta = \frac{1}{1 - e^{-\lambda_{\text{short}} z_t^{k*}}} }[/math]
- Failures (Glass, Black Obstacles): Handles the inability of sensors to detect certain materials that don't reflect signals well, like glass or dark colored objects. Which will result in the maximum reading even though this is not representing the true distance.
The probability p_max for the maximum range measurement is defined as: ;[math]\displaystyle{ p_{\text{max}}(z_t^k \mid x_t, m) = \begin{cases} 1 & \text{if } z_t^k = z_{\text{max}} \\ 0 & \text{otherwise} \end{cases} }[/math]
- Random Measurements: Captures spurious data and anomalies that don't correspond to actual obstacles, likely due to sensor malfunctions or external interferences.
The probability p_rand for a random measurement is defined as: ;[math]\displaystyle{ p_{\text{rand}}(z_t^k \mid x_t, m) = \begin{cases} \frac{1}{z_{\text{max}}} & \text{if } 0 \leq z_t^k \leq z_{\text{max}} \\ 0 & \text{otherwise} \end{cases} }[/math]
All of them combined make a measurement model that models the events that could have occurred for a particular ray (laser measurement), resulting in the following formula: Taking the weighted average of these distributions yields the overall model: ;[math]\displaystyle{ p(z_t^k \mid x_t, m) = z_{\text{hit}} p_{\text{hit}}(z_t^k \mid x_t, m) + z_{\text{short}} p_{\text{short}}(z_t^k \mid x_t, m) + z_{\text{max}} p_{\text{max}}(z_t^k \mid x_t, m) + z_{\text{rand}} p_{\text{rand}}(z_t^k \mid x_t, m) }[/math]
- With each particle having N >> 1 rays, and each likelihood being ∈ [0,1] , where could you see an issue given our current implementation of the likelihood computation?
Since we assume independence we calculate the overall likelihood of the complete measurement (all combined rays) to be their product since these are values between 0 and 1 this can result in computational errors. Related to underflow, when using floating-point arithmetic, the precision of very small numbers can become unreliable.
2.2 Re-sample the particles
- What are the benefits and disadvantages of both the multinomial resampling and the stratified resampling?
The benefit of multinomial resampling is that it is easier to implement because it randomly selects the particles based on their weights, therefore the chance of picking a particle with a higher weight is higher. Stratified resampling assures that samples with a lower weight are also considered and resampled. This is a benefit because you can then easily update your stance if the first prediction was not correct and it preservers particle diversity. A disadvantage of multinomial is that it does not take these lower weighted particles into account and that it performs less efficient. Implementing this in the stratified resampling means that it harder to implement.

2.3 Test on the physical setup
- How you tuned the parameters.
- Tested on simulation - Since the test was done in simulation, and the map was completely known in advance, a bigger weight was given to the hit_prob. Whereas, the other probabilities were reduced. It is because, for instance, it is not expected to find unforeseen obstacles in the simulation, therefore short_prob was reduced. Similarly, it was not expected to find glass walls, so max_prob was also decreased. rand_prob was also reduced since the random error is less in the simulation than in the real setup. After implementing this it was noticed that the particles were lagging behind the robot. It was due to the time taken to resample the particles. So, the resampling time was changed from "Always" to "everyNtimesteps". That way the particles had enough time to be resampled.
- How accurate your localization is, and whether this will be sufficient for the final challenge.
As the video above shows, the particle filter is already quite accurate in the simulation. In the real setup it might behave differently. We have not been able to test this however. So for the final assignment the algorithm still needs to be tested on the real robot. The simulation does already show that some improvements can be made on the resampling time to make the cloud of particles follow the robot even faster.
- How your algorithm responds to unmodeled obstacles.
Since we were unable to test this with the real robot, we do not yet know how it will respond to unmodelled obstacles. We hope that by tuning some of the probability factors, the localization algorithm is still able to perform well with the addition of random obstacles. Also, by using the Stratified resampling method, we hope that by keeping some of the lower probable particles, the robot is able to handle these unmodeled obstacles.
- Include a video that shows your algorithm working on the real robot
Unfortunately were did not finish the particle filter on time to also test the localization on the real robot. We are, however, confident that with the particle filter performing the way it does now that it will also perform well on the actual robot (with some changes in the parameters of course).
Final Challenge (nienke)

Requirements
For the final challenge, all the different components listed above had to be combined. Next to that, some more requirements had to be met. These requirements come from the different stakeholders that are involved in the restaurant robot. These stakeholders include the owners of the restaurant, the staff of the restaurant, and the customers. In the image to the right, the requirements for each of the stakeholders can be found.
For the customers safety is, of course, important. They want to be sure that they are save while in the restaurant. Next to that, they want the serving to go well. So the robot should go up to the table, orient towards the table, and move close to the table such that the customers can easily take the order from the robot. The robot should also find an empty spot at the table where it can do this. So when a spot is occupied it will try at a different side of a table. The third requirement for customers is that the robot needs to be polite. Servers in a restaurant also always need to be polite towards customers, so the robot should as well. An implementation of this could be to have the robot speak. While serving the table the robot can indicate to the customers that it has arrived with their order and that they can take the order from the tray once it has docked successfully. But also small pronunciations such as "enjoy your meal" are part of polite customer service.
The second stakeholder is the staff of the restaurant. It could be that there is still crew delivering orders themselves. Otherwise the employees making the drinks and food can be accounted here. For them it will also be important to be save while working. So having obstacle avoidance implemented in the robot is very important for them. They want to be able to roam around freely, without a robot crashing into them. Next to that, they might be the people who have to fix the mistakes the robot might be making. Therefore, having a robust robot is very important to them. The robustness of the robot should be in all the stages of the robot, so in localization and in local and global planning. The robot should also be easy to use by the staff. This can be implemented by using a simple user interface. The personnel only need to give the order of table numbers to the robot.
The last stakeholder is the owner of the restaurant. Next to safety, simplicity, and robustness, they want the robot to be as fast as possible. Having the robot speedily deliver the orders will increase customer service and might also increase sales. An implementation of this could be that the robot should find the shortest path towards a table using the global planner.
Implementation of the components
To meet the requirements, the components of global planning, local navigation, don't crash, and localization need to be combined. Next to that, other implementations such as serving a table need to be added as well. To visualize the data flow of these components the following data flow diagram has been made:

In the flow diagram four components can be identified. First, the sensory data, that is used as input to the system, can be identified. Laser data is used in Local Navigation. Local Navigation, in turn, gives information to Global Navigation. It outputs a boolean that tells Global Navigation whether a goal has been found or not. Additionally, Local Navigation communicates its speed and turning rate to the Control Integration. Control Integration is used for collision avoidance and speed control. Control Integration also uses the infromation from the bumper data and outputs the final controls to the Excute Command. The second input component that can be identified is the map data. This is data constructed from the .png, .yaml, and .json files of the restaurant map. This information in given to the Global Planner, which uses it to create a path of nodes. The third component is the odometry data. This, together with the laser data, is used for the Localization. This function communicates the predicted location of the robot to Global and Local Navigation. The big challenge for the final challenge is to have all these components working together in harmony while taking the requirements into consideration.
Possible situations (adapted components to this)
While designing the code for the final challenge, more actions need to be taken into account. Not only do the components listed above in the data flow diagram need to work effectively together, they also need to give room for more implementations. These extra implementations include table docking, node skipping, speed control, and door opening.

Testing (nienke)
Testing of components (testing conditions for the components and conclusions)
To have all of the components work together harmoniously, all the individual states need to be robust and free of (major) errors. To ensure this, a couple of tests have been performed. This section includes the tests of the localization, which was not tested before the interim deadline to show that this component is working and is robust. Since the global and local navigation were already tested individually, they were now tested when they are combined. After this tests were performed with localization included in the system and lastly all the restaurant challenges were added to the overall system and these needed to be tested as well.


First, for the testing of localization. The test for this individual component on the real robot was not performed before the deadline and therefore will be included here. Since localization already worked in the simulation, the test mostly consisted of changing a few parameters in the .json file. These parameters included the probability parameters discussed in the localization chapter for the exercises. In order to see which components needed change or in other words, which component had a higher or lower probability of happening, some changes were made to the map. The map that was used was the same one as for global planning. One of these changes was to have a human walking in the map, to account for unexpected obstacles. Another element that was tested was the probability of the maximum range. This was done by taking away a random wall and to see if the robot will keep its original prediction of its location. A third test that was performed was to remove a wall that changed the map in such a way that the robot could be standing on a different location. This test in particular was difficult for the robot and it lead to changing the function slightly. The function was changed to behave slightly 'poorer'. It might be odd to make a system behave less well than it did before but for the particle filter this did gave an advantage. The reason for making this change was because the function was working a bit too good. The robot would quickly update its initial position and the cloud of particles immediately becomes a dense pack around the robot pose. This seems nice but the following experiment showed that it was more a curse than a blessing. In this experiment, the robot was rotated 180 degrees from its predicted initial pose. After starting up the machine, the robot was not able to localize itself, causing a constant error in its position. It was not able to update its belief because the particles were too tightly packed and unable to change their belief. To account for wrong estimations we did already use the stratified resampling model such that particles are not always discarded. But even with using this method, the particles are very conservative. Thus, the particle filter was made to be a bit slower and less dense to have a more robust intitialization and localization in the map.
<video of localization >
<video of robust initial position>
Second, the combination of global and local navigation was tested. During the experiment it was important that the robot would not drive against walls, which is a problem often occuring with the local navigation, and that the global planner does not put nodes into walls.
The combination of the three components was tested as well. Here it was discovered that localization was performing appropiately. The robot did, however, occasionally drive into walls. For this reason a robust obstacle avoidance was added to the local navigation state. The implementation of this will be discussed in the section on local navigation below. It also became apparant that global navigation should not place any nodes in either the walls nor the tables.
During the combination of the three components, some additional functions were added to the system as well. These functions were node skipping and docking. To test node skipping the two maps on the side were used.
System architecture (luis)
Architecture Layout (motivation component decisions (for final challenge)).
State Transitions.
Multi-Threading.
World objects. (robot.cpp and world.cpp)
Localization State (Salim)
Cloud expansion
Wrong Orientation Handling
Other Improvements
Initialization State (aniek)

In the initialization state, the tables to serve are converted to coordinates on the map that the robot needs to serve. Through the command line, one can give the order of tables to be served. This is read and converted to a vector which is used in the initialization state to get the table coordinates for serving. In order to get these coordinates, the map data needs to be used to associate certain points with the tables. For this, we use the JSON file that is available containing table coordinates and wall coordinates which are end- and starting points of the lines in a wall or table. Using these, it can be inferred where the tables are and thus it's serving points can be extracted. These coordinates are then the middles of each table side, such that we have multiple serving points if one side of the table is occupied for instance. To get the correct coordinates, a few things have to be assessed. Firstly, tables can be against walls, and therefore some points might not be reachable. Once these sides have been removed, coordinates can be selected. Now, these steps will be explained in more detail
Serving coordinate computation.
To compute the coordinates, we start with associating each table and wall with its designated coordinates. When we have the coordinates sorted to every table and wall we can compute the centroid of that table by summing all x coordinates and y coordinates and then dividing by the count. This is used to determine the correct direction, which is used to offset the middle points in a table side. Next, we compute the middle points of the table sides and offset them with 0.5m in the correct direction (away from the centroid). Now, for all table sides, a docking point is made. We move on to the overlap of walls and table sides.
Overlap Walls.
Because tables can be against walls, some serving points have to be removed as they cannot be accessed. For this the overlap of walls and tables are assessed. First, outside points are matched to table sides such that, when a table side overlaps, the corresponding serving point can be removed. Once this is achieved, the wall and table side segments are compared against each other by first checking if they are both horizontal or vertical. If this is the case, the maxima and minima are taken from the segments and if the difference between the minimal maxima and maximal minima is bigger than the threshold 0.21, a point is removed. Now we can move on to coordinate selection.
Coordinate selection.
The final step is to select the coordinates. This is a simple operation of looking at the table numbers supplied from the command line and ordering the serving coordinates in this manner, as well as removing the instances that are not in the command line. This vector is then relayed to the shared data struct which can be accessed by the other states. An event is raised aswell, stating that initialization is finished.
Improvements.
Sadly there was no time to check for other obstructions that were close to the serving points. For instance, if there is a wall close to the table such that the robot cannot enter there, but the space is sufficiently big enough to accomodate the serving point, we have a problem. Therefore, a possible suggestion is to check a radius of the robot around the serving point, and if this is big enough then we keep the point, but if an obstruction is found we throw away the serving point.
Globally Planning State (maxH)
Path Recomputation.
Path-Not-Found Handling
The global path generated as path with way-points, which is provided to the locally navigating state. The objective of the locally navigating state, is to safely drive from waypoint to waypoint to its final goal. For the locally navigating state, we used the VFH from exercise 2. The basic principle is not explained again. However, some addaptions have been made, which are discussed in this part.
Collision Control
From exercise 1, a dont_crash code is created. During local navigation, it is possible to get in a collision (really close to an object). The robot should be capable of handeling collision. It starts by detecting collisions. This is done by using solution 3 of exercise 1. It considers each laser distance and looks if an object is too close. In determining this, the correct distance from the laserfinder to the robot is determined, in addition with a minimal distance. For our challenge, we chose a distance of 5 centimeters. this is done, since the local navigator is very good at avoiding obstacles. Hence, the collision should only be triggered if the object is really close. the 5 distance is also enough in comparison to the maximum velocity used in the speed control. This is validated by extensive testing (the robot never touched a single object). The youtube link at the bottom shows different don't crash senario's.
Once the robot is in collision, is thould handle the collision. The first step is to wait for a certain amount of seconds. For our purpose, we chose 2 seconds. If the collision is removed within 2 seconds, the robot can continue its normal path. However, if the collision is still there after 2 seconds, it takes action to avoid the collisions. First, it searches for the laser angle which is the closest to an obstacle, as this triggered the collision. Then, it steers 10 degree away from that angle. So, if the robot is rotated 0 degrees, and the obstacle is detected at 40 degrees (clockwise positive), it starts rotating 10 degrees counter-clockwise. After rotation for 10 degrees, it scans an area in front of the robot. If this area is free, the robot drives in this area. The area consists of 20 centimeters forward and the corresponding robot area that comes with this 20 centimeters forward motion (so multiple lasers are used for this). If this area is not available, it rotates another 10 degrees. It keeps rotating until it finds a possible area to drive in. After driving into this area, the local navigator continues driving towards the next waypoint.
The result of the collision control is really good. It never crashed into objects. Also, is works very well with chairs. The local navigator can have some difficulties with chairs. The crash collision prevents it from crashing into chairs and enables the robot to drive around it.
ADD YOUTUBE LINK
Steering away from obstacles
The previous VFH method had some steering difficulties. The main problem, was that it could steer really close to walls, due to the way it detected valleys. If the goal is within a possible valley, the robot takes the goal as new steering angle. However, one can imagine that if the goal-angle if really close to a wall, the robot tends to steer close to walls. This is fixed by implemented an additional value to the valley borders. If it is a wide valleys, and the goal is close to the valley border, the robot steers towards the border with a certain safety margin. If the valley is narrow, the robot always steers to the middle, as the borders are too close to the robot. By implementing this, the new behavior was improved a lot, in comparison the the previous steering behavior. The videos in the youtube link below show some results of the new steering (simulation and real time implementation).
(ADD YOUTUBE LINK)
Wall Inflation
If the robot is in small corridors or narrow corners, the VFH can still have some problem with steering away from the walls. Therefor, the walls in the constructed OccupancyGridMap (exercise 2) are thickened, in order to have a little more safety margins between the robot and the walls.
Speed Control Updated
The speed control tuned a little bit in comparison to the previous example. If the robot has to steer more than 18 degrees, it stops as rotates first at our own defined maximum rotation speed. If the rotation in smaller, it can drived forward and rotate during driving. It constantly adapts its angle, even if it is above 1 degree.
Node Skipping.
Important behaviour for the robot is node skipping. After a certain time, the robot should move on to its next objective because the previous cannot be reached. Also, when a table side cannot be reached it should move on to another side it has not checked yet. Therefore, a time limit should be put on going to nodes. In this implementation, a timer is started at the beginning of local navigation (and resets as soon as local navigation is called again). This timer is then reset with each even happening which can be getting to a node or table or collision control. This way, it is prevented that the timer runs out when a lot of collisions happened for instance. This time should not be the accounted time for localizing a node or table, as the collision control should be performed. Next, when a node is reached it should reset the timer as well, since we want to allocate the same amount of time for each node that we try to reach.
|-- Timer: Start, Reset on node/table reach, collision
| |-- If Timer expires -> Move to next objective
|-- On Node Reach: Reset Timer
|-- Node Skipped: Count skips
| |-- If 2 skips -> Skip entire table
|-- Table Side Skipped: Go to another side, then skip table if all sides skipped
|-- End
Moving on, when 2 nodes are skipped by the algorithm, it will skip the entire table as well. Skipping 2 nodes in a row indicated that something more is wrong with the route than just an object in the way. Therefore it should skip the whole table to account for waiting time for customers. If for instance early in the route the robot starts skipping nodes and its entire passage is blocked, it will take a long time before it will move on to the next table. Therefore it is important to keep this in mind. What's more, If a table side is skipped we go to another table side that is provided by the initialization state. This way, when one side is not reachable, we can still serve the table on another side. If the last side is also not reachable, we simply skip the table.
Improvements.
For the node skipping implementation, a caveat is that when a table is still reachable but for instance a lot of people are in the way of the robot and the timer runs out, it should not skip a node. Therefore, a better implementation would be to utlize laser data to see if there are obstacles in the path it wants to take that cover the entire corridor. If it then places the obstacle (temporarily) in a map and make it act as a wall, one can see that no path is possible anymore. This would work as a faster implementation and also account for temporary obstacles.
Table Serving State (Nienke & Luis)
Orienting to table.
After the robot has reached the table, the robot will move to its serving state. In this state, the robot will first orient towards the table. It will do so by turning towards the centroid of the table, defined in the initialization state.
Serving.
After the robot has oriented itself towards the table, the robot will move forward slowly towards the table. Once the robot deems itself in contact with the table, it will stop moving. The customers can now take their order from the robot. After serving its order, the robot will move back again, stop, and signal to the main that the serving state has ended. While the customer takes the oder from the robot, the robot says: "Enjoy," and when the robot has ended the serving, the robot will say: "Bye." An improment in this state would be to make the speech items of the robot more customer friendly. An imrpovement would be to have the robot say more while serving. Sentences such as: "Hello, here is your order. Please take it off the tray," could improve the service. The customer now knows that it is safe to take off the food or drinks. Saying "enjoy" and "goodbye" can still be used afterwards.
Ending State (Aniek)
Final Challenge Results (Aniek)
Explanation behaviour.
What went wrong (link back to system design).
Future directions
Improvements (for design or components).
Things to take into account
Component selection Restaurant challenge
- Is the choice of components motivated by the challenge? x
- Are the components adapted to the requirements of final challenge? x
- Does the wiki show an understanding of the algorithms in the component? x
Experimental validation of the components
- Are the components tested individually? x
- Are the experiments performed a suitable approximation of the conditions of the final challenge? x
- Are the conclusions drawn supported by the results of the experiments? x
System design for the final challenge
- Is the design presented complete? x
- Is the design communicated clearly? x
- Are design choices motivated by the final challenge? x
Experimental validation of system design
- Are the experiments performed a suitable approximation of the final challenge? x
- Are the conclusions drawn supported by the results of the experiments? x
Evaluation Restaurant challenge
- Is the behaviour during the final challenge explained? x
- Is this behaviour linked back to the designed system? x
- If applicable, is an adjustment to the design proposed? x
References
- ↑ Matoui, F., Naceur, A. M., & Boussaid, B. (2015). Local minimum solution for the potential field method in multiple robot motion planning task. Conference Paper presented at the 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS). doi:10.1109/STA.2015.7505223. Retrieved from [ResearchGate](https://www.researchgate.net/publication/307799899).