Embedded Motion Control 2014 Group 2: Difference between revisions
| Line 368: | Line 368: | ||
Unfortunately we were not able to complete the maze competition with our strategy. Because the network was too occupied at the moment of the maze competition, we were not able to send the created map as visual feedback to the computer screen. Therefore we can not say with full confidence what went wrong during the maze competition. Most likely, something went wrong in the Hector mapping node. This node does not perform as good in the real world as in the simulation environment. It is both slower and less accurate in the real world than in the simulation, this is mainly due to the fact that the sensors are just not perfect. This will probably have resulted in the detection of wrong lines/corner points, causing our algorithm to fail. In the simulation the mapping strategy worked flawlessly because here the maze is less prone to influences from the real world (such as lighting or inaccurate positioning of the walls). The mapping method shows not to be very robust, compared to other strategies such as following a wall. However if the mapping strategy is made more robust, it has a lot of advantages compared to the other strategies. A recommendation for our strategy is thus to make the mapping node more robust. | Unfortunately we were not able to complete the maze competition with our strategy. Because the network was too occupied at the moment of the maze competition, we were not able to send the created map as visual feedback to the computer screen. Therefore we can not say with full confidence what went wrong during the maze competition. Most likely, something went wrong in the Hector mapping node. This node does not perform as good in the real world as in the simulation environment. It is both slower and less accurate in the real world than in the simulation, this is mainly due to the fact that the sensors are just not perfect. This will probably have resulted in the detection of wrong lines/corner points, causing our algorithm to fail. In the simulation the mapping strategy worked flawlessly because here the maze is less prone to influences from the real world (such as lighting or inaccurate positioning of the walls). The mapping method shows not to be very robust, compared to other strategies such as following a wall. However if the mapping strategy is made more robust, it has a lot of advantages compared to the other strategies. A recommendation for our strategy is thus to make the mapping node more robust. | ||
The overall group cooperation was very good. Everyone | The overall group cooperation was very good. Everyone had certain tasks which he could work on. All members were willing to help eachother out when needed. No struggles between group members were encountered and the communication always went well. | ||
Although we spent a lot of time on creating the code, it is very unsatisfying that we did not solve the maze during the maze competition. Especially because we were able to fininsh the maze in simulation but also during testing (see movies). | Although we spent a lot of time on creating the code, it is very unsatisfying that we did not solve the maze during the maze competition. Especially because we were able to fininsh the maze in simulation but also during testing (see movies). | ||
Latest revision as of 10:34, 30 June 2014
Members of Group 2:
Michiel Francke
Sebastiaan van den Eijnden
Rick Graafmans
Bas van Aert
Lars Huijben
Planning:
Week1
- Lecture
Week2
- Understanding C++ and Ros
- Practicing with pico and the simulator
- Lecture
Week3
- Start with the corridor competition
- Start thinking about the hierarchy of the system (nodes, inputs/outputs etc.)
- Dividing the work
- Driving straight through a corridor
- Making a turn through a predefined exit
- Making a turn through a random exit (geometry unknown)
- Meeting with the tutor (Friday 9 May 10:45 am)
- Lecture
Week4
- Finishing corridor competition
- Start working on the maze challenge
- Think about hierarchy of the system
- Make a flowchart
- Divide work
- Corridor challenge
Week5
- Continue working on the maze challenge
- Set up Hector mapping node
- Development of map interpreter
- Start on arrow detection algorithm
Week6
- Continue working on the maze challenge
- Finish map interpreter
- Design of case creator node
- Development of arrow detection algorithm
Week7
- Continue working on the maze challenge
- Finish case creator node
- Start top level decision node (brain node)
- Finish arrow detection node
- Start trajectory node
Week8
- Continue working on the maze challenge
- Work on top level decision node (brain node)
- Finish trajectory node (fail safe design)
- Test complete system of nodes
- Presentation
- Make presentation
- Practice presentation
- Finish Wiki page
Week9
- Final tests with all nodes
- Final competition
Corridor Challenge
Ros-nodes and function structure
The system for the corridor challenge is made up from 2 nodes. The first one is a very big node which does everything needed for the challenge, driving straight, look for corners, turning, etc. The second one is some kind of fail-safe node which checks for (near) collisions with walls and if so, it will override the first node to prevent collisions. The figure next to the ros-node overview displays the internal functions in the drive-node.


Each time the LaserCallBack function gets called the CheckWalls function is called in it. This function looks at the laser range at -pi/2 and pi/2. If both the lasers are within a preset threshold it sets the switch that follows the CheckWalls function such that it will execute the Drive_Straight function. If either the left or the right laser exceed the threshold it will cause the switch to execute the Turn_Left or Turn_Right function respectively. If both lasers exceed the threshold pico must be at the exit of the corridor and the stop function is called. Each of these functions in the switch set the x,y and z velocities to appropriate levels in a velocity command which can then be transmitted to the velocity ros-node.
Corridor challenge procedure
The figures below display how all the different functions in the switch operate and it also shows the general procedure that pico will follow when it solves the corridor competition.

![]()

![]()

![]()

![]()

Action 1: In the first picture we see pico in the drive straight mode. The lasers at -pi/2 and pi/2 are being monitered (indicated in black) and compared with the laser points that are closest to pico on the left and right side (indicated with red arrows). The y-error can now be interpreted as the difference in distance between the two red arrows divided by 2. The error in rotation can be seen as the angle difference between the black and red arrows. In order to stay on track pico magnifies the y and theta errors by a negative gain and sends the resulting values as the velocity commands for the y and theta velocity commands respectively. This way pico is always centered and aligned with the walls. The x-velocity is always just a fixed value.
Action 2: As soon as pico encounters an exit, one of its lasers located on the sides will exceed the threshold causing the switch to go to one of the turn cases.
Action 3: Once in the turn case, pico must first determine the distance to the first corner. This is being done by looking at all the points in a set field of view (the grey field) and then determining which laser is the closest to pico. The accompanying distance is stored as the turning radius and the accompanying integer that represents the number of the laser point is stored as well. For the second corner we do something similar but look in a different area of the lasers (the green field), again the distance and integer that represent the closest laser point are stored.
After this initial iteration, each following iteration will relocate the two corner points by looking in a field around the two stored laser points that used to be the closest to the two corners. The integers of the laser points that are now closest to pico and thus indicate the corners, are stored again such that the corner points can be determined again in the following iteration.
The distance towards the closest point is now being compared with the initial stored turning radius, the difference is the y-error and is again magnified with a negative gain to form the y-speed command. The z-error is determined from the angle that the closest laser has with respect to pico, this angle should be perpendicular to the x-axis of pico. Again the error is magnified with a negative gain and returned as the rotational velocity command. This way the x-axis of pico will always be perpendicular to the turning radius and through the y correction we also ensure that the radius stays the same (unless the opposing wall gets to close). The speed in x-direction is set to a fixed value again, but it only moves in x-direction if the y and z errors are within certain bounds. Furthermore, also the y-speed isn't enforced if the z error is too large. This in this order we first make sure that the angle of pico is correct, than we compensate for any radius deviations and finally pico is allowed to move forward along the turning radius.
Action 4: If pico is in the turning case, the checkwalls function is disabled and the routine will always skip to the turn command, thus an exit condition within the turning function is required. This is where the tracking of the second corner comes in. The angle [math]\displaystyle{ \varphi }[/math] that represents the angle between the second corner and one of the sides of pico is constantly being updated. If the angle becomes zero, pico is considered to be done turning and should be located in the exit lane. The turning case is now aborted and pico should aromatically go back into the drive straight function because the checkwalls function is reactivated.
Action 5: Both the left and right laser exceed the threshold and thus pico must be outside of the corridor's exit. The checkwalls function will call the stop command and the corridor routine is finished.
Note: If the opposing wall would be closed (an L-shaped corner instead of the depicted T-shape) the turning algorithm will still work correctly.
Corridor competition evaluation
We achieved the second fastest time of 18.8 seconds in the corridor competition. Our scripts functioned exactly the way they should have. However our entire group was unaware of the speed limitation of 0.2 m/s (and yes we all attended the lectures). Therefore, we unintentionally went faster than we were allowed (0.3 m/s). Nevertheless, we are very proud on our result and hopefully the instructions for the maze competition will be made more clear and complete.
Maze Competition
Flowchart
Our strategy for solving the maze is shown schematicallly in the figure below. The strategy used here differs from the strategy used in the corridor competition. Now we create a map of the surroundings with pico's laser data. This map gets updated and new information will be added when pico drives through the world resulting in a detailed overview of the complete area. The advantages of using a map are:
- It enables us to remember the places pico has visited.
- It enables us to make smart choices while solving the maze.
- It is possible to handle loops in the maze
- Less dependent on the latest sensory data. In other words, it is more robust.
- It enables us to anticipate on upcoming crossings, deadends and plan relatively simple trajectories.
- It is possible to share map information with other robots, which makes it possible to have multiple robots working efficiently together to solve the maze.
- It is possible to remember the route taken, so the next time pico runs through the maze it can follow a better route.
Many of these advantages are not necessary for the maze competition. However, it allows us to easily extend the program for more sophisticated mazes.
-
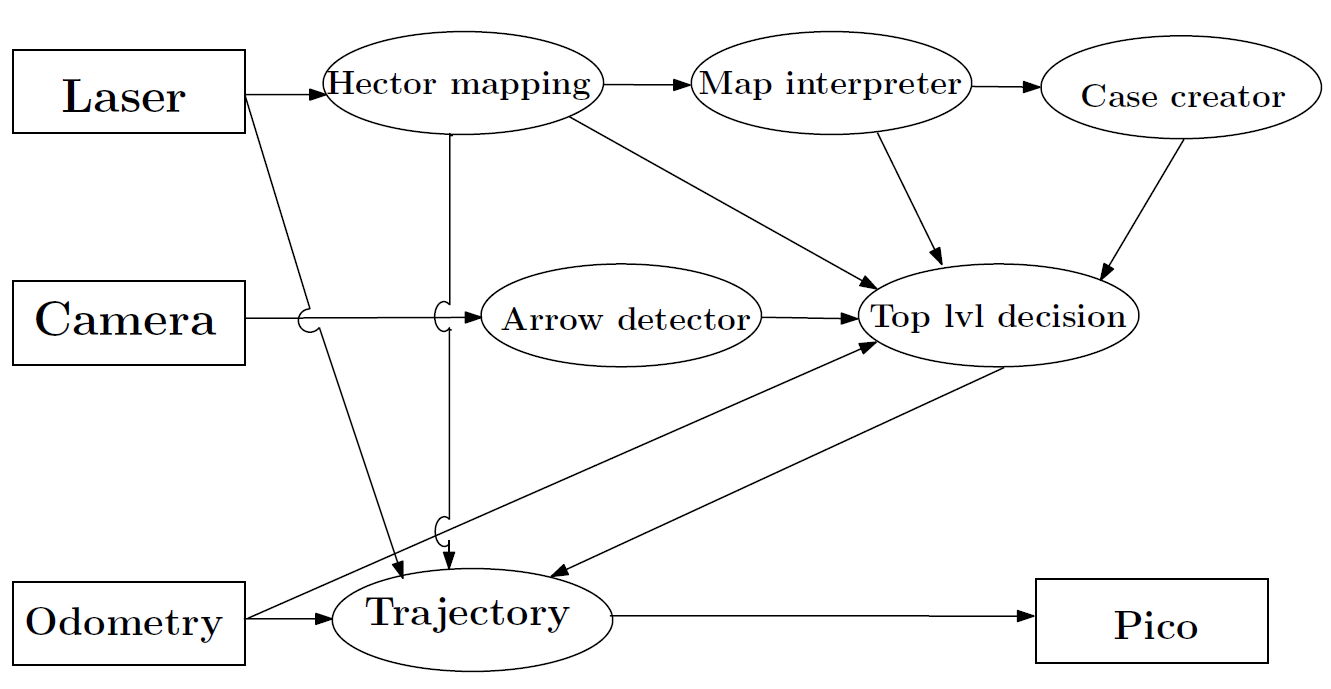 Figure 1.1: Flowchart
Figure 1.1: Flowchart

Six nodes ( Arrow detector, Hector mapping, Map interpreter, case creator, top level decision and trajectory) have been developed and communicate with each other through several topics. The nodes are subscribed on topics to receive sensory data coming from the laser, camera and odometry modules. All nodes are launched in one launch file. The function of the individual nodes will be discussed below.
Hector mapping / Map interpreter
Hector Slam is a standard ROS stack with multiple packages, one of these packages is Hector mapping. Hector mapping is a simultaneous localization and mapping (SLAM) algorithm which creates a map based on laserscan data published by a laser scanner. It works by matching each new frame with the current map and expand the map with this new information. This matching is also the way to localize pico with respect to the map. The map that is created is an occupancy grid which represents the world discretized in elements. Each element has a length and width of 0.02 meter. To all these elements there is assigned a value based on the fact if this field is occupied. It can have three different values: occupied, non occupied or unknown. VIsualization of the map in Rviz can be seen in figure 1.2.
-
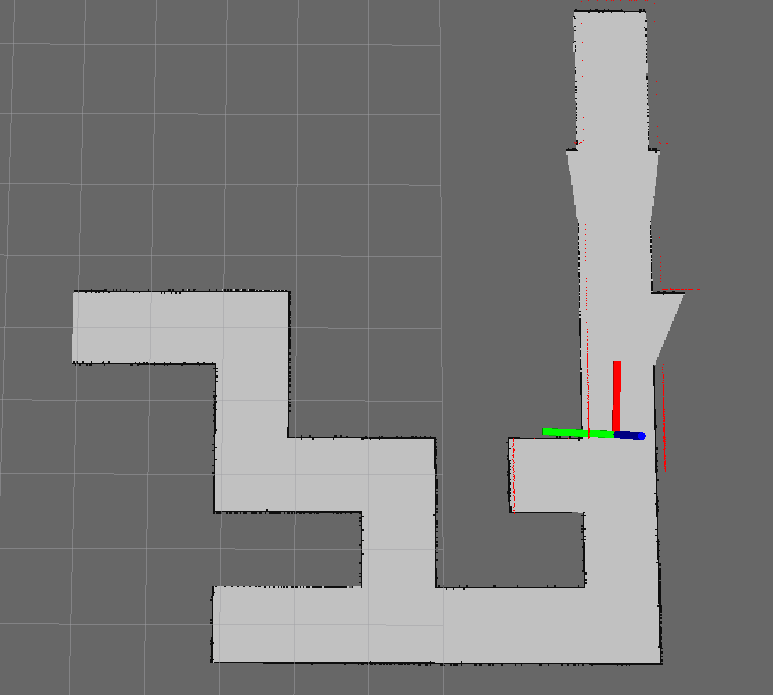 Figure 1.2: Hector Mapping
Figure 1.2: Hector Mapping

To do something with this occupancy grid, the map needs to be interpreted, this is done by the map interpreter. The map interpreter first detects lines on the map with the use of a hough transform (http://www.keymolen.com/2013/05/hough-transformation-c-implementation.html). This hough transform provides lines which span the entire map. To find the real lines these lines needs to be cut-off at the right position. This is done by comparing the lines with the values on the occupancy grid and see where the actual lines are. To make sure that a hole in the line does not disturb the process, the values of the occupancy grid are modified. For every occupied element the direct neighborhood is also set to be occupied. To avoid double lines, the line will only be acknowledged if there is not already a line which is similar to the detected line. With the detected lines also the corners can be detected. This is done by comparing any two lines and see if they intersect. This intersection function will be explained later. The next step is to add corner points to the ends of lines which do not intersect, this is usefull for the case creator node. These lines and corners can also be visualized in rviz and the end result is shown below. The final step is to publish the lines and corners on a topic to which other nodes can subscribe.
-
 Figure 1.3: Map Interpreter
Figure 1.3: Map Interpreter

Case creator
In this section the case creator node will be discussed. As can be seen below seven cases can be encountered.
-
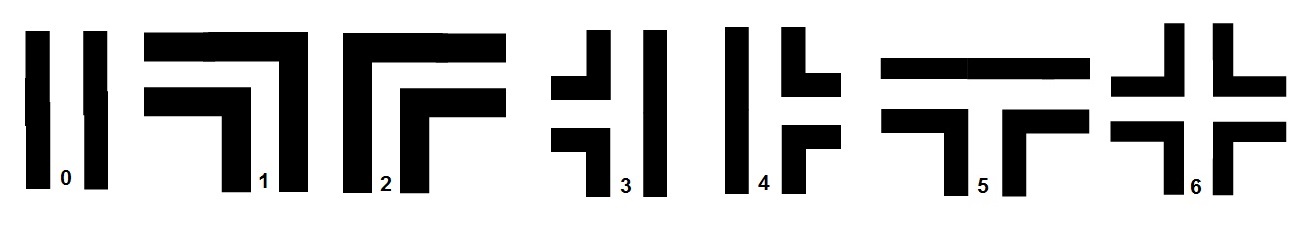 Figure 1.4: Cases
Figure 1.4: Cases

An overview of the case creator node is given in the figure below.
-
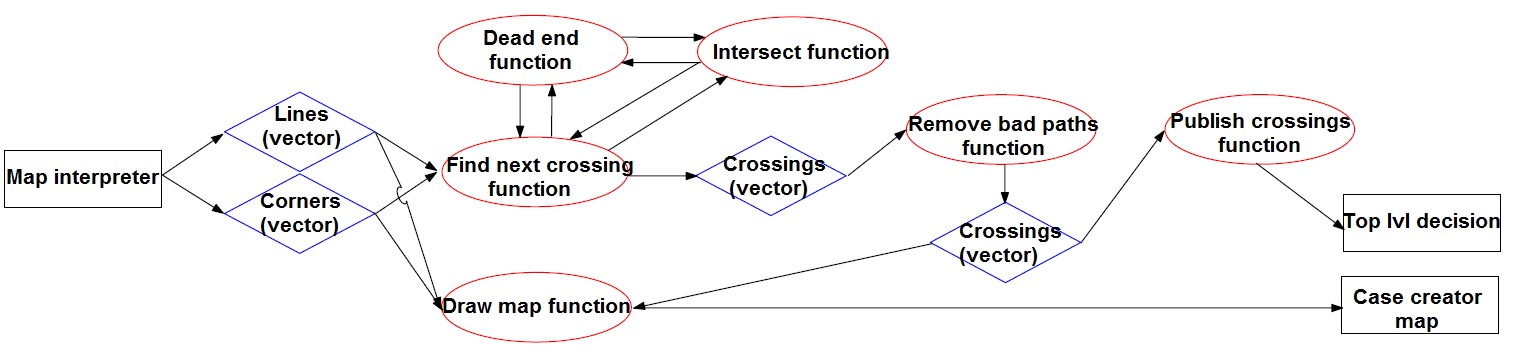 Figure 1.5: Case creator node
Figure 1.5: Case creator node

Find next crossing
In the starting position, pico searches for two points that represent the entry of the maze (see the case creator map below for a visualization). The find next crossing function uses these two points to search in a perpendicular direction for a new crossing. However, first the dead end function is called which verifies whether the open end is really open. If a new crossing is found, the type of crossing can be determined from the corner points that are found. This results in maximally three new sets of points that represent uninvestigated open edges of the crossing. These new sets of two points can again be used in the find next crossing function such that new crossings that are attached to the current crossing are found. This searching algorithm continues until no more crossings can be found. The next paragraph contains a detailed description of the find next crossing function.
The find next crossing function gets two corner positions as its input. For all the corners that are already found in pico's map, it will determine a vector with respect to both the input points. These vectors can be projected onto the origin. After projection, the corresponding x and y differences are calculated, and from this information the perpendicularity can easily be determined. For all the corner points that are perpendicular within a certain range with respect to the input points, pico will find the two closest points for each input point, if they exist. From the existence of these points and the approximate distance towards the input points, the type of crossing can be determined. Hereafter, some extra points are calculated (if necessary) such that each crossing has four corner points and a center point. Finally, this information is stored in a vector called crossings, together with any information about dead ends, the crossing type and information about the connectivity of the crossings.
Dead end detection
During Pico's route through the maze dead ends will be encountered. Obviously, driving into a dead end should be avoided to keep the journey time to a minimum. If Pico is arrived on the center of a crossing a clear overview of situation will become visible in the map. This situation is depicted in the figure below.
-
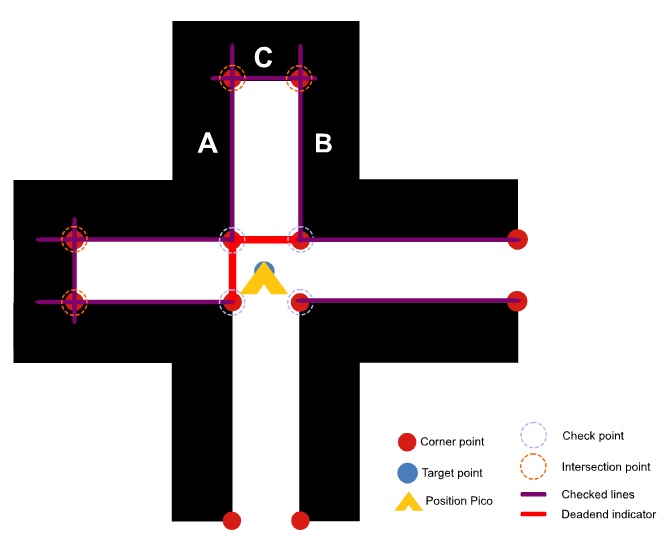 Figure 1.6: Deadend
Figure 1.6: Deadend

For a maximum of three crossingexits (depending on crossing type) will be checked if the corresponding corridor results in a dead end. From the map interpreter which interprets the hector mapping node, the walls (lines) are known in absolute coordinates (indicated with a start and end point). In the dead end function first all lines that lay on the four check points of the current crossing will be searched for in the array where all lines are stored. So for the figure above, first for the lower left (LLT) corner point and upper left (ULT) corner point, then for ULT corner point and upper right (URT) corner point and finally for URT corner point and lower right (LRT) corner point the dead end will be checked. For example, for the exit above will be checked if line C gets intersected twice. This is the case (lines A and B). For all crossing options this will be checked and a red (dead-end) wall will be drawn accordingly to reduce the number of options for pico to drive to. The line intersection algorithm that is used will now be briefly explained.
-Intersection algorithm (function): The intersection algorithm computes if and where two lines intersect. The input of this algorithm are the two start and two end points of the two lines in absolute x and y coordinates. First the x coordinates of the start point and end point are compared for both lines to determine if the lines are vertical. Four cases can be distinquished:
-1) both lines are vertical no intersection,
-2/3) one of the lines is vertical, possibly one intersection
-4) no vertical lines, possibly one intersection.
These cases are there to prevent dividing by zero to calculate the gradient of the lines. The gradients are simply calculated according to the formula:
[math]\displaystyle{ a = \frac{y_{2}-y_{1}}{x_{2}-x_{1}} }[/math]
For case 4 the gradients are calculated to compose two line equations: [math]\displaystyle{ y = a_{1}x+b }[/math] and [math]\displaystyle{ y = a_{2}x+b }[/math]. The corresponding intersection point follows from equating these two lines which results in the intersection point (x,y) and a boolean is set to true if they intersect. For case 1 this boolean will be set equal to false, no intersection is found. In case 2 and 3 for the non-vertical a gradient will be computed according to the formula above. The other line has constant x coordinates and now the intersection point can be computed again.
-Line length (function): Another function which has been used frequently in for example case node, top level decision and trajectory is a linelength computation. The input of this function are the two coordinates of the start and end point of a line. These are used to calculate the distance (radius) from one point to another. The used formula is given below:
[math]\displaystyle{ r = \sqrt{(x_{2}-x_{1})^{2}+(y_{2}-y_{1})^{2}} }[/math]
Case creator map
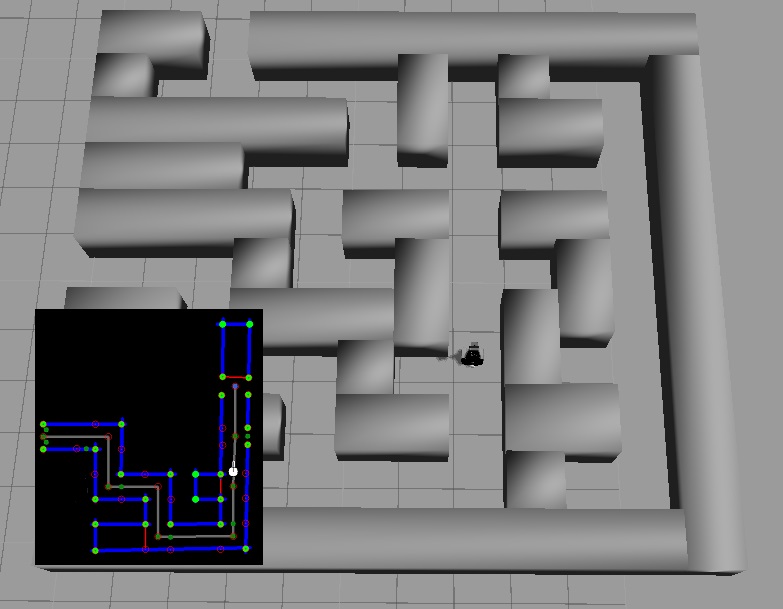
Visual feedback (a map) results from the case creator node which is shown below. The walls are indicated with blue lines, the corners are depicted with green points and five red points per crossing are shown. The previously discussed red dead end walls are visible in this map. This map updates every 2 seconds due to Hector mapping node and increases in size when Pico progresses through the maze.
-
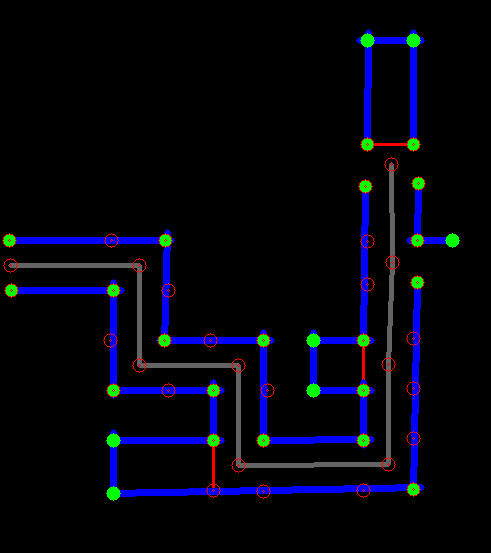 Figure 1.7: Case creator map
Figure 1.7: Case creator map

The grey lines connect the crossings and partly overlaps the path of Pico as generated by the trajectory node. All information to build the map results from the vectors: lines, corners and crossings and is drawn with OpenCV.
Top level decision
The top level decision node decides in which direction a trajectory should be planned. It finds a new set point which becomes a target point for the trajectory node. The top level decision node is subscribed to five topics and forms the brain of interconnected nodes. First of all it is connected to the odometry module and secondly to the Hector mapping node to receive information to determine the current position of pico. Furthermore, it is subscribed on a topic which is connected to the arrow detector node. The arrow detector node as will be described in the next paragraph sends an integer message 1 for a left arrow and a 2 for a right arrow to help pico find the correct direction. Besides, the top level decision node is connected to case creator and map interpreter nodes to draw a high level map and to obtain the available crossing information. An overview of the functions inside this node are schematically shown in the figure below.
-
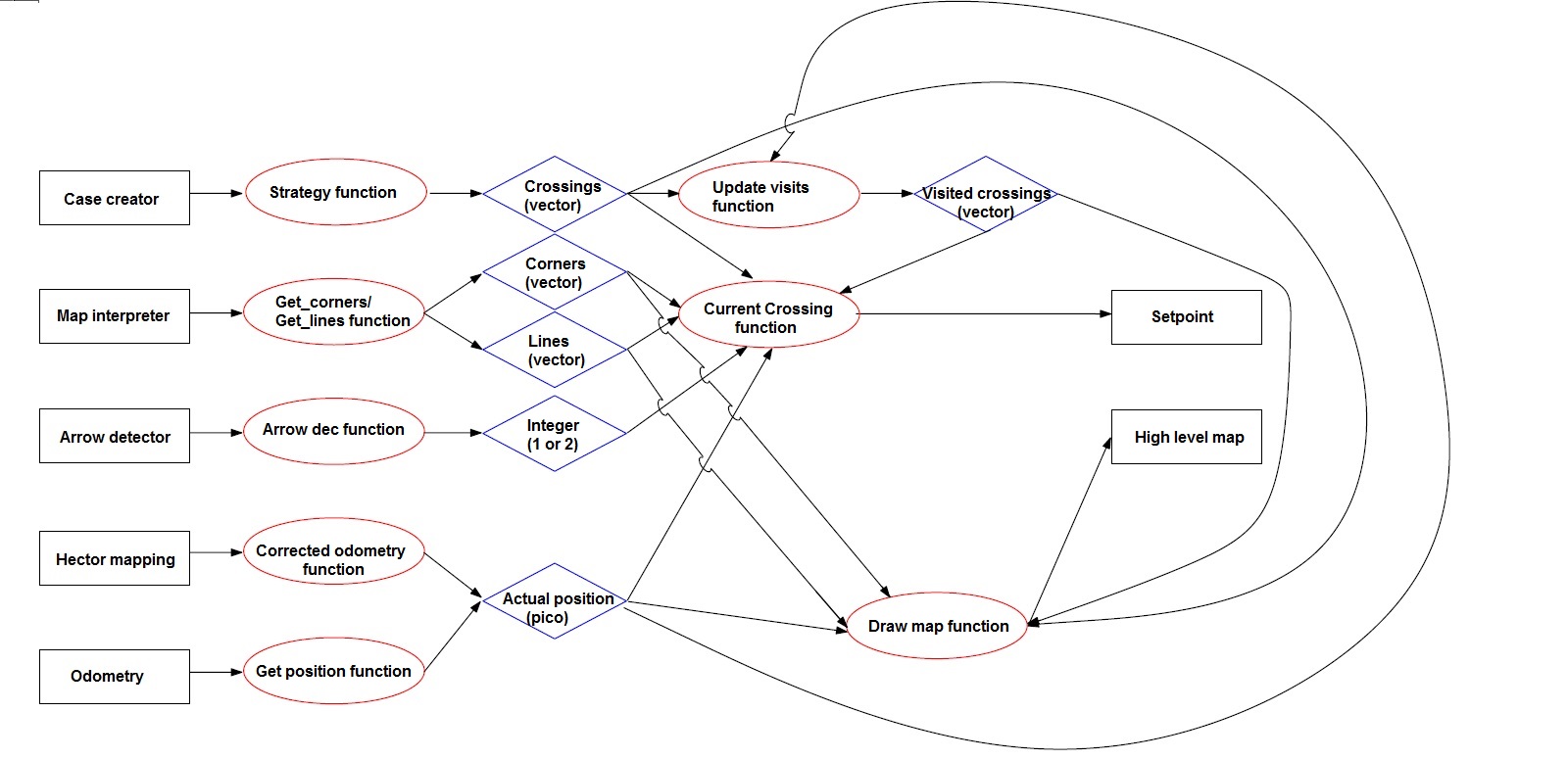 Figure 1.8: Flowchart high_level_dec
Figure 1.8: Flowchart high_level_dec

In the figure the transfered information (vectors and integers) are depicted in the blue shapes. These vectors are updated and their dimension increases while pico progresses through the maze. Corners and lines follow from the map interpreter node these are used to determine the case and used to draw the maps. Subsequently, the crossings are created in case creator and each visited crossing is saved in the visited crossings vector. An important function (current crossing) will be explained in more detail.
Current crossing function: The current crossings function has to determine the next setpoint for pico. In order to do so it searches for the closest crossing to pico in the visited crossings vector that is not the crossing that pico left from (because that would lead to a deadlock). The visited crossings function is used for this purpose because it is guaranteed that the position of a crossing in the current crossings list will not change if a new crossing is added. Thus the visited crossings list can be used to store whether pico has already chosen a direction, and thus another direction would be prefered if multiple directions are possible.
After finding a new crossing that pico is close enough to (if any are found), it will determine what its options are. First it checks the type of crossing it has encountered, this already reduces the amount of options pico has. Thereafter, for the remaining directions, pico checks whether any of them lead to a dead end. Now, pico will verify if it has already been to any of the directions, which will eliminate some more options accordingly. Finally, if the crossing type is a T-junction, it will also check whether an arrow is detected. This information will always trump the previously found options.
Now that pico knows its options, it has to determine a new setpoint. If only one option is available, than pico knows it can make a fast turn to the left or to the right. If multiple options are available, it will choose the upward direction if possible. If left and right are both available, a random function will determine the new direction. If no options are available, pico will drive back to the previous crossing. This behaviour results in a depth first type of search algorithm.
Two types of setpoint situations can be distinguished in the current crossing function, they are depicted below in the figures:
1. A turn can be initiated before the crossing [type 1 or type 2]
From the case creator node follows that a simple corner (of type 1 or 2) is nearby. A starting point and endpoint are placed (green points in figure) so pico does not have to reach the center of the crossing first. Then a curved trajectory can be planned in the next node. Besides the x- and y coordinates of these two points also the type of corner (left or right) and coordinates of the turning point (here lower left corner) are send in a float32mulitArray message to the trajectory node.
2. Go to center of crossing for overview of situation [ type 3, type 4, type 5 or 6]
For all the other types of crossings all the sides have to be checked if going that direction will result in a deadend. In a type 5 situation (T-crossing) with arrow information, the choice will be based on the direction of the arrow. If no arrow is present (or detected) a random function will be called to decide whether to go left or right. If it is possible to go foward that will always be the preferred direction.
-
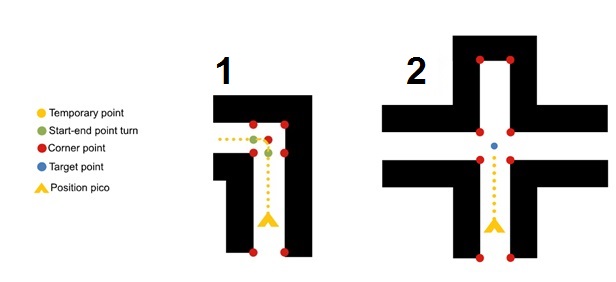 Figure 1.9: turn
Figure 1.9: turn

The top level decision nodes keeps track of the crossings pico has visited (crossing ID), the actual position of pico and available next crossings nearby. Furthermore, the current departure and arrival points are temporarily saved as well as the chosen option in a previous crossing.
- High level map:
The high level map is created with standard circles and lines from the openCV package and is more detailed than the case creator map. An example is given in the figure below, due to the frequency of hector mapping this map updates every 2 seconds.
-
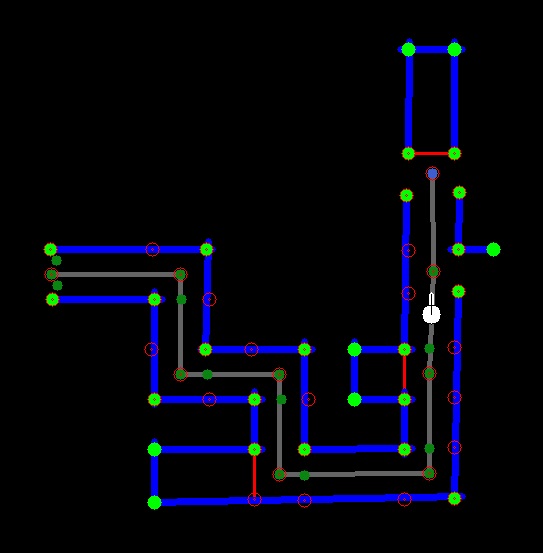 Figure 1.10: High level decision
Figure 1.10: High level decision

In addition to the case creator map, Pico's position (white point) is also depicted here as well as the next setpoint (blue point). Furthermore, the small green points indicate the crossings that have been visited and the directions on a crossing that were taken. A video of the high level map while pico drives through the maze can be found on the bottom of the page.
Trajectory
For letting Pico drive in the right directions through the maze, a trajectory node is made. With means of Hector Mapping, Pico’s laserdata is converted to a virtual map of the maze. In general, it is possible to determine Pico’s location from the (interpreted) map, however the update frequency of Hector Mapping is only a 0.5 Hz. Therefore, pico’s location is besides hector mapping also determined by the data from the odometry topic. This topic sends the actual orientation of Pico with respect to a base frame which has its origin at the initial starting point of Pico. It could be possible however that this base frame does not coincide with the base frame of the map made by Hector Mapping. Therefore the odometry data has to be corrected every time a new map is published. This way the coordinate frames of the map and the Odometry data will coincide.
Now that Pico knows its orientation within the map, it can orient its way to a new desired location. This location is specified by the high level decision node. Depending on the geometry of the maze, the trajectory from Pico’s actual position to the newly specified location could either be a straight line, a curve to the left or a curve to the right. The type of trajectory is specified in the message published by the high level decision node with means of an integer (0,1 or 2). Next, depending on the type of trajectory, the trajectory will be discretized in a number of points and pico will move in a straight line between these discretized points, as is also shown by the yellow temporary points in the figures above.
Straight line
With means of Pythagoras’ theorem the absolute distance between the start and end point is calculated. This distance is divided into a certain number of points with equal spacing L. The angle between the two points [math]\displaystyle{ (\theta) }[/math] is calculated relative to the Hector Mapping frame. Now the set of coordinates between the two points can be calculated in a for loop by adding (or subtracting) [math]\displaystyle{ iLsin(\theta) }[/math] to the x coordinate and [math]\displaystyle{ iLcos(\theta) }[/math] to the y coordinate of the starting point.
Curve

It is possible that the corridors in the maze do not all have the same width. Therefore, it is not suitable to make a perfect circular arc for making the turn. Otherwise pico will not end up in the middle of the new corridor. Actually, this is not a big problem because pico will automatically correct itself. But for a more robust routeplanning and to have a better flow through the maze it is better to make an ellipsoid-like turn. This is shown in the figure to the right. This will particularly be useful if corridor widths will differ substantially.
The discretization of the trajectory will be done in theta, as defined in the figure. To convert theta to the useful coordinates x and y, the radius is computed for each point and subsequently the x and y coordinates are computed using basic goniometry. The radius for an ellipse is given by,
[math]\displaystyle{ r(\theta)=\frac{ab}{\sqrt{(b \cos{\theta})^2+(a \sin{\theta})^2}} }[/math]
Thresholds
Now that the vector of points is constructed, Pico can drive from a point to an upfollowing point in that vector to eventually reach the desired end point. For smooth and correct driving, it is necessary that Pico’s orientation is always parallel to the trajectory. This means that Pico must always ‘look’ towards the next point in the vector. To achieve this the angle between the two points (target_angle) with respect to the Hector Mapping base frame is calculated. An angular velocity is send to Pico to let it turn in the right direction. The target_angle is constantly compared to the actual orientation of pico (actual_angle). If it now holds that: abs(target_angle – actual_angle) < threshold, the angular velocity is set to 0.0.
Similarly, pico will never reach the exact target position. Analogously to the target angle a threshold system for the position is made to define when pico has reached a new point. This system looks something like:
abs(target_pos.x-actual_pos.x)<threshold && abs(target_pos.y-actual_pos.y)<threshold.
When no new message is received for more than 5 seconds, pico will start rotating about its axes to create the possibility to see more from the actual maze. This way the high_level_decision node can obtain more information and create a new message with a new setpoint.
Structure
The trajectory node uses the following structure shown in the figure below. Circles represent functions, squares represent topics.
-
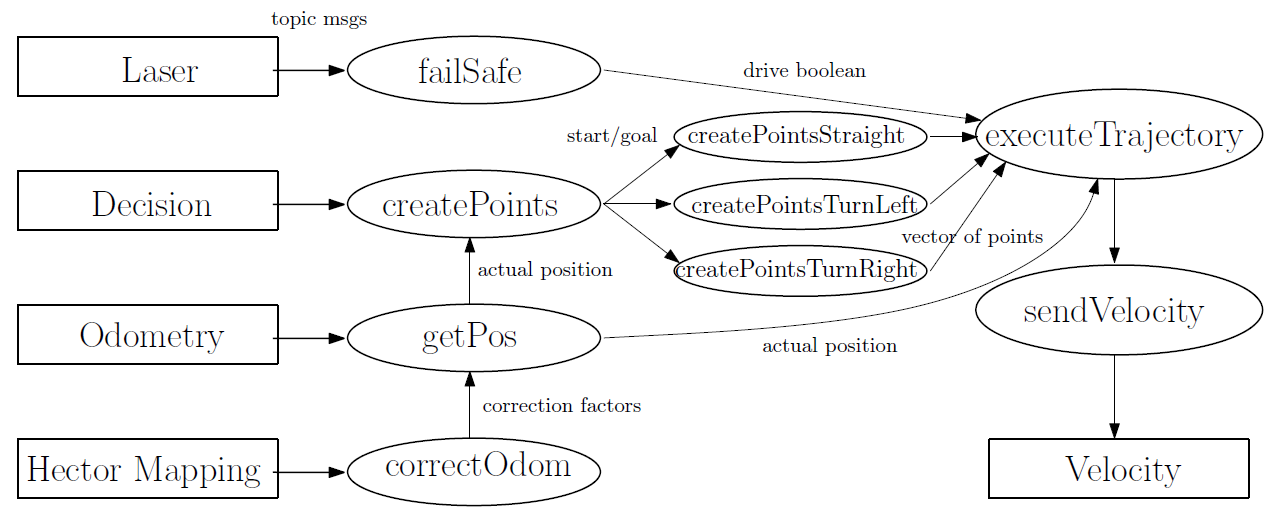 Figure: 1.12: Trajectory flowchart
Figure: 1.12: Trajectory flowchart

'Hector mapping' will send the maps orientation to 'correctOdom' which computes correction factors used by 'getPos'. 'getPos' Receives the position according to the odometry and corrects it with the correction factors, such that the corrected (actual) position has the same basis as the map. The 'createPoints' function uses the actual postion and the information received by the decision node to compute a trajectory. This trajectory can be either a straight line, a turn left or a turn right as explained earlier. Additional functions are made to actually do the discretization and compute the trajectory (vector of points) for each of these cases. These are 'createPointsStraight', 'createPointsTurnLeft' and 'createPointsTurnRight'. The discretized trajectory will be used by the executeTrajectory function which actually computes the velocities required to follow the trajectory. These velocities are computed by comparing the trajectory to the actual position.
Fail safe
To be absolutely sure pico will never drive into a wall, a fail safe function is implemented in the trajectory node. It uses the laserdata to detect whether pico is too close to the wall. When this is the case, probably more than one laserdata point is within the thresholds. Therefore, the closest one is used and pico will drive in exactly the opposite direction until it is in the free space again. This is achieved by computing the angle from the laserdata point which is closest to the wall and compute (and scale) the required x and y velocities in the opposite direction. This method is invariant to pico's orientation towards the maze.
Arrow detector
Although the arrow detection is not crucial for finding the exit of the maze, it will potentially save a lot of time by avoiding dead ends. That is why we considered the arrow detection as an important part of the problem, instead of just something extra. The cpp file provided in the demo_opencv package is used as a basis to tackle the problem. The idea is to receive ros rgb images, convert them to opencv images (.mat), convert them to hsv images, find 'red' pixels using predefined thresholds, apply some filters and detect the arrow. The conversions are applied using the file provided in demo_opencv, but finding 'red' pixels is done differently.
Thresholded image
Opencv has a function called InRange to find pixels within the specified thresholds for h, s and v. To determine the thresholds, one should know something about hsv images. An hsv image stands for hue, saturation and value. In opencv the hue ranges from 0 to 179. However the color red wraps around these values, see figure a.1. In other words, the color red can be defined as hue 0 to 10 and 169 to 179. The opencv function InRange is not capable of dealing with this wrapping property and therefore it is not suitable to detect 'red' pixels. To tackle this problem, we made our own InRange function, with the appropriate name 'InRange2'. This function accepts negative minimum thresholds for hue. For example:
min_vals=(-10, 200, 200); max_vals=(10, 255, 255); inRange2(img_hsv, min_vals, max_vals, img_binary);
Makes every pixel in img_binary for which the corresponding pixel in img_hsv lies within the range [H(169:179 and 0:10) S(200:255) V(200:255)] white and otherwise black. This results in a binary image (Thresholded image), see for example figure a.3 which is a thresholded image of figure a.2.
Filter
The first filter applied to the binary (thresholded) image is a filter which computes the number of 'red' pixels. When this number is below 2000 it said there is no (detectable) arrow present in the current image and the arrow detection stops to save on processor power. When the number is greater than 2000, the second filter is applied.
The second filter is used to filter out the noise in the binary (thresholded) image, because the thresholded image likely contains other 'red' clusters besides the arrow. The filter computes the average x and y of all the white pixels in the thresholded images. Subsequently it deletes all the pixels outside a certain square from this average. The length and width of this square have a constant ratio (the x/y ratio of the arrow ~ 2.1) and the size is a function of how many pixels are present in the thresholded image. This way the square becomes proportionally with the distance of the arrow. This approach is very prone to noise and therefore an additional safety is applied. The detection only starts if the number of pixels present in the filtered image lies between 2000 and 5000. These numbers are optimized for an arrow +- 0.3 to 1.0 meter away from pico. An example of the applied filter is shown in figure a.3. The red lines are the averages and everything outside the square is deleted.
detection
To detect whether the resulting image contains an arrow to the left or an arrow to the right, the following algorithm is used:
determine new means compute standard deviations in terms of y for both halves of the picture. That is left and right of the average x (Sl and Sr) If Sl-Sr>threshold ---> arrow left If Sl-Sr<threshold ---> arrow right else ---> no arrow detected
Of course, this method is not very robust and prone to noise. However, it is very efficient and it is able to detect arrows in the maze consistently.
The last seven processed frames are stored in an array of integers. This array is constantly updating when new frames are send over the camera topic. The integers inside the array can either take the value 0 when no array is detected, a 1 for an arrow to the left or a 2 for a right arrow. Next, it is decided to only send a message over the topic when the last seven frames contain at least five arrows to the left or five arrows to the right. This is another safety, to avoid false messages. The message consists of an integer which is either 1 or 2 (1 for a left arrow and 2 for a right arrow).
A video of the arrow detection algorithm working is placed at the bottom of the wiki.
-
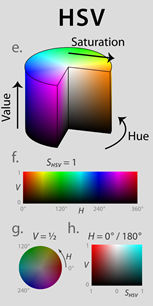 Figure 1.13a: HSV
Figure 1.13a: HSV -
 Figure 1.13b: Original image
Figure 1.13b: Original image


-
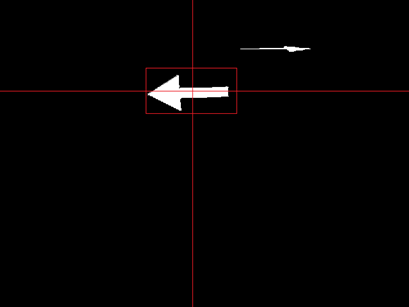 Figure 1.13c: Filtering
Figure 1.13c: Filtering -
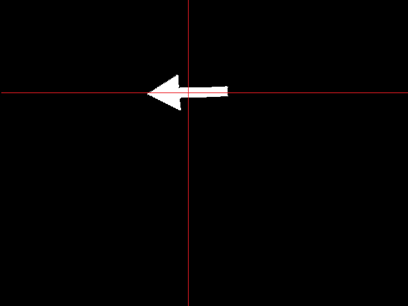 Figure 1.13d: Filtered image
Figure 1.13d: Filtered image


Map creation (for simulation in gazebo)
Besides the default maze we developed new mazes to test with. To make new mazes you can follow the following steps:
Make your own maps: 1. Download GIMP (ubuntu software center) 2. Open maze.pgm in GiMP in: (/home/yourusername/ros/emc/general/gazebo_map_spawner/maps) 3. Modify maze (lower-left box set brushes to 5x5 2nd last line) 4. Set Pencil tool to hard brush (upper left box) 5. Save map different name, e.g. 'yourmap.pgm in (/home/yourusername/ros/emc/general/gazebo_map_spawner/maps) 6. Open in gedit: /home/yourusername/ros/emc/general/gazebo_map_spawner/scripts/spawn_maze 7. Add the following line at the end: rosrun gazebo_map_spawner map_spawner `rospack find gazebo_map_spawner`/maps/yourmap.pgm 8. Save spawn_maze (don't change folder names and script names) 9. In terminal: rosrun gazebo_map_spawner spawn_maze
Besides all seven crossing types three new mazes (1 complex maze, 1 simple maze and a maze with a loop) are developed which can be found below.
-
 Figure 1.14: Different Mazes
Figure 1.14: Different Mazes

Maze competition evaluation
Unfortunately we were not able to complete the maze competition with our strategy. Because the network was too occupied at the moment of the maze competition, we were not able to send the created map as visual feedback to the computer screen. Therefore we can not say with full confidence what went wrong during the maze competition. Most likely, something went wrong in the Hector mapping node. This node does not perform as good in the real world as in the simulation environment. It is both slower and less accurate in the real world than in the simulation, this is mainly due to the fact that the sensors are just not perfect. This will probably have resulted in the detection of wrong lines/corner points, causing our algorithm to fail. In the simulation the mapping strategy worked flawlessly because here the maze is less prone to influences from the real world (such as lighting or inaccurate positioning of the walls). The mapping method shows not to be very robust, compared to other strategies such as following a wall. However if the mapping strategy is made more robust, it has a lot of advantages compared to the other strategies. A recommendation for our strategy is thus to make the mapping node more robust.
The overall group cooperation was very good. Everyone had certain tasks which he could work on. All members were willing to help eachother out when needed. No struggles between group members were encountered and the communication always went well.
Although we spent a lot of time on creating the code, it is very unsatisfying that we did not solve the maze during the maze competition. Especially because we were able to fininsh the maze in simulation but also during testing (see movies).
Videos
Solving a maze with Pico (New)
Arrow detection

Pico's final test

Time Survey Table 4K450
| Members | Lectures [hr] | Group meetings [hr] | Mastering ROS and C++ [hr] | Preparing midterm assignment [hr] | Preparing final assignment [hr] | Wiki progress report [hr] | Other activities [hr] |
|---|---|---|---|---|---|---|---|
| Week 1 | |||||||
| Lars | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Sebastiaan | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Michiel | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Bas | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Rick | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Week 2 | |||||||
| Lars | 2 | 0 | 16 | 0 | 0 | 0 | 0 |
| Sebastiaan | 2 | 0 | 10 | 0 | 0 | 0 | 0 |
| Michiel | 2 | 0 | 10 | 0 | 0 | 0 | 0 |
| Bas | 2 | 0 | 12 | 0 | 0 | 0.5 | 0 |
| Rick | 2 | 0 | 14 | 0 | 0 | 0 | 0 |
| Week 3 | |||||||
| Lars | 2 | 0.25 | 4 | 13 | 0 | 0 | 0 |
| Sebastiaan | 2 | 0.25 | 6 | 10 | 0 | 0 | 0 |
| Michiel | 2 | 0.25 | 6 | 10 | 0 | 0 | 0 |
| Bas | 2 | 0.25 | 4 | 10 | 0 | 0 | 0 |
| Rick | 2 | 0.25 | 6 | 6 | 6 | 0 | 0 |
| Week 4 | |||||||
| Lars | 0 | 0 | 0 | 12 | 0 | 6 | 0 |
| Sebastiaan | 0 | 0 | 1 | 10 | 0 | 0 | 2 |
| Michiel | 0 | 0 | 0 | 2 | 10 | 2 | 0 |
| Bas | 0 | 0 | 0 | 13 | 0 | 0 | 0 |
| Rick | 0 | 0 | 0 | 4 | 8 | 0 | 0 |
| Week 5 | |||||||
| Lars | 2 | 0 | 0 | 0 | 22 | 0 | 0 |
| Sebastiaan | 2 | 0 | 0 | 0 | 20 | 0 | 0 |
| Michiel | 0 | 0 | 0 | 0 | 18 | 0 | 0 |
| Bas | 2 | 0 | 0 | 0 | 14 | 0 | 0 |
| Rick | 2 | 0 | 0 | 0 | 20 | 0 | 0 |
| Week 6 | |||||||
| Lars | 0 | 0 | 0 | 0 | 20 | 0.25 | 0 |
| Sebastiaan | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Michiel | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Bas | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Rick | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Week 7 | |||||||
| Lars | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Sebastiaan | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Michiel | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Bas | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Rick | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Week 8 | |||||||
| Lars | 0 | 0 | 0 | 0 | 24 | 0 | 0 |
| Sebastiaan | 0 | 0 | 0 | 0 | 18 | 4 | 0 |
| Michiel | 0 | 0 | 0 | 0 | 19 | 5 | 0 |
| Bas | 0 | 0 | 0 | 0 | 18 | 5 | 0 |
| Rick | 0 | 0 | 0 | 0 | 24 | 0 | 0 |
| Week 9 | |||||||
| Lars | 0 | 0 | 0 | 0 | 25 | 0 | 0 |
| Sebastiaan | 0 | 0 | 0 | 0 | 15 | 2 | 2 |
| Michiel | 0 | 0 | 0 | 0 | 15 | 2 | 0 |
| Bas | 0 | 0 | 0 | 0 | 15 | 5 | 0 |
| Rick | 0 | 0 | 0 | 0 | 20 | 0 | 0 |
| Week 10 | |||||||
| Lars | 0 | 0 | 0 | 0 | 15 | 5 | 0 |
| Sebastiaan | 0 | 0 | 0 | 0 | 5 | 10 | 0 |
| Michiel | 0 | 0 | 0 | 0 | 8 | 10 | 2 |
| Bas | 0 | 0 | 0 | 0 | 10 | 10 | 0 |
| Rick | 0 | 0 | 0 | 0 | 15 | 5 | 0 |