PRE2019 3 Group15: Difference between revisions
TUe\20181913 (talk | contribs) |
|||
| (308 intermediate revisions by 5 users not shown) | |||
| Line 1: | Line 1: | ||
<div style="font-family: 'Helvetica'; font-size: 14px; line-height: 1.5; max-width: 1150px; word-wrap: break-word; color: #333; font-weight: 400; box-shadow: 0px 25px 35px -5px rgba(0,0,0,0.75); margin-left: auto; margin-right: auto; padding: 70px; background-color: white; padding-top: 25px;"> | |||
<font size = 6>Di-J: The Digital DJ</font> | |||
---- | |||
== Group Members == | == Group Members == | ||
| Line 17: | Line 24: | ||
|} | |} | ||
=Problem Statement | =Introduction= | ||
DJ-ing is a relatively new profession. It has only been around for less than a century but has become more and more widespread | ==Problem Statement== | ||
DJ-ing is a relatively new profession. It has only been around for less than a century but has become more and more widespread in the last few decades. This activity has for the most part been executed by human beings, since creating a nice flow from track to track requires a skilled professional. With the rise of artificial intelligence systems in recent years, however, it might be possible to delegate some tasks to a digital system. | |||
Current technology in the music industry has become better and better at generating playlists, or 'recommended songs' as, for example, Spotify does [[#References|(Pasick, 2015)]]. If this technology is integrated with the DJ world, would a ‘robot DJ’ be possible to create? Such a robot DJ would autonomously create playlists and mix songs, based on algorithms and real-life feedback in order to entertain an audience. | |||
This leads to the question: How to develop an autonomous system/robot DJ which enables the user to easily use it as a substitute for a human DJ? | |||
After exploring this question we will also discuss whether this robot DJ will be valued by the user so that it will actually be used. | |||
==Approach== | |||
The goal of this project is to create software that functions as a DJ and provides entertainment for an audience. In order to create this software, first, a literature study will be performed to find out about the current state of the art regarding the problem. After enough information has been collected, the goals and milestones can be determined, which will guide the group during this process. Then, the user and technical aspects of the problem will be researched. The needs of the user will be strongly taken into account when making the design choices. The technical knowledge can then be used to actually create the software. Sub-teams will work on different tasks that are essential for the product, which will later be integrated to create the working software. During the design process of the software, user-tests will be executed to validate the software is satisfying the users' needs. | |||
==Milestones== | |||
In order to complete the project and meet the objectives, milestones have been determined. These milestones include: | |||
* A clear problem and goal have been determined | |||
* The literature research is finished, this includes research about: | |||
** Users (attenders of music events, DJs, club owners) | |||
** The state of the art in the music (AI) industry | |||
* The research on how to create the DJ-software is finished, this includes research about: | |||
** How to predict which songs will fit in DJ set | |||
** The Spotify API | |||
** How to order the songs in a set to create the most excitement in a crowd | |||
** How to build a user interface | |||
* The DJ-software is created | |||
* User tests are performed to validate the satisfaction of the user needs | |||
* The wiki is finished and contains all information about the project | |||
* A presentation (video) about the project is made | |||
Other milestones, which probably are not attainable in the scope of 8 weeks, are | |||
* A test is executed in which the environment the software will be used in is simulated | |||
* A test in a larger environment is executed (bar, festival) | |||
* A full scale robot is constructed to improve the crowd’s experience | |||
* A light show is added in order to improve the crowd’s experience | |||
* Research on ways to obtain feedback from a crowd is conducted | |||
==Deliverables== | |||
The deliverables for this project are: | |||
* The DJ-software, which is able to use feed-forward and incorporate user feedback in order to create the most entertaining DJ-set | |||
* Depending on what type of user feedback is chosen, a prototype/sensor also needs to be delivered | |||
* The wiki-page containing all information on the project | |||
* The final presentation in week 8 | |||
=Users= | =Users= | ||
| Line 55: | Line 100: | ||
**The DJ-robot takes the audience reaction into account in track selection. | **The DJ-robot takes the audience reaction into account in track selection. | ||
= | ==The Effenaar== | ||
Since 1971 The Effenaar has developed into one of the biggest music venues of the Netherlands. Having one main hall made for 1300 people and a second hall with a capacity of 400 people. Besides their music halls and restaurant, a part of their group is working on their so called Effenaar Smart Venue. Their goal is to improve the music experience of their guests, and the artists, during their shows. In order to do this, the Smart Venue focuses on existing parts of technology. They ask themselves: what is available? And, what fits in certain shows? | |||
The | |||
= | For example, at a concert of Ruben Hein, they had 12 people wearing sensors measuring brainwaves, heartrates and sweat intensity on their fingertips. As seen in this [https://www.youtube.com/watch?v=_7us-kS0d3E video]. Afterwards, they were able to see which music tracks triggered their enthusiasm and which tracks didn’t. The difference between our project and theirs is that we want to have the user feedback at the same time of the music playback. However, retrieving information this way could still be valuable. It can be measured on real people how their body reacts to certain music tracks. | ||
The | |||
Besides only focusing on music, they had several other projects. During one show they had 4 control panels set up in the hall. With these panels the guests could change the visuals of the show. Moreover, they had a project where they would make a 3D scan of guests to be used by the artist as visuals or holograms. In another experiment, they introduced an app which would raise the awareness of the importance of wearing earplugs. They used team spirit as a tool to drive this behavior, since they see sense of community as a strong value. They had a project running on [[#Feedforward|feedforward]] based on a user database, but this was shut down due to it not being financially profitable. | |||
The Effenaar can still benefit from an improvement of their crowd control. For example, their main hall has a bar right next to the entrance, which sometimes causes blockades. Here, technology could play a role. The crowd could be directed by the use of lighting or what songs are being played. | |||
Our robot could help the Effenaar in their needs when focusing on music being played before and after the shows. In their second hall, the lights are already automatically adapted on the music that is being played. However the music before and after shows is controlled by an employer of the Effenaar. Most of the time this results in just playing an ordinary Spotify playlist. It would be more convenient if this could be automated and have a music set which fits to the show. They don’t see much potential in replacing the artist of a show by a robot DJ. It would rather result in a collaboration between a DJ and the technology. As said, they emphasize on the social aspect of a night out, to create a memorable moment. | |||
=State of the Art= | =State of the Art= | ||
The dance industry is a booming business that is very receptive | The dance industry is a booming business that is very receptive to technological innovation. A lot of research has already been conducted on the interaction between DJ's and the audience and also in automating certain cognitively demanding tasks of the DJ. Therefore, it is necessary to give a clear description of the current technologies available in this domain. In this section, the state of the art on the topics of interest when designing a DJ-robot is described by means of recent literature. | ||
==Defining and influencing characteristics of the music== | ==Defining and influencing characteristics of the music== | ||
When the system receives feedback from the | When the system receives feedback from the audience it is necessary that it is also able to do something useful with that feedback and convert it into changes in the provided musical arrangement. The most important aspects of this arrangement are chaos, energy, tempo, danceability, and valence. | ||
Chaos is the opposite of order. Dance tracks with order can be assumed as having a repetitive rhythmic structure, contain only a few low-pitched vocals and display a pattern in arpeggiated lines and melodies. Chaos can be created by undermining these rules. Examples are playing random notes, changing the rhythmic elements at random time-points, or increasing the number of voices present and altering their pitch. Such procedures create tension in the audience. This is necessary because without differential tension, there is no sense of progression [[#References|(Feldmeier, 2003)]]. | Chaos is the opposite of order. Dance tracks with order can be assumed as having a repetitive rhythmic structure, contain only a few low-pitched vocals and display a pattern in arpeggiated lines and melodies. Chaos can be created by undermining these rules. Examples are playing random notes, changing the rhythmic elements at random time-points, or increasing the number of voices present and altering their pitch. Such procedures create tension in the audience. This is necessary because without differential tension, there is no sense of progression [[#References|(Feldmeier, 2003)]]. | ||
The factors energy and tempo are inherently linked to each other. When the tempo increases, so does the perceived energy level of the track. In general, the music's energy level can be intensified by introducing high-pitched, complex vocals and a strong | The factors energy and tempo are inherently linked to each other. When the tempo increases, so does the perceived energy level of the track. In general, the music's energy level can be intensified by introducing high-pitched, complex vocals and a strong occurrence of the beat. Related to that is the activity of the public. An increase in activity of the audience can signal that they are enjoying the current music, or that they desire to move on to the next energy level [[#References|(Feldmeier, 2003)]]. Because in general, people enjoy the procedure of tempo activation in which they dance to music that leads their current pace [[#References|(Feldmeier & Paradiso, 2004)]]. | ||
Danceability relates to the extent to which it is easy to dance on the music. This is a feature, described by [https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/ Spotify] as "to what extent can people dance on it based on tempo, rhythm stability, beat strength, and overall regularity". Valence relates to the positivity (or negativity) of the song - so either positive or negative emotions. | |||
==Algorithms for track selection== | ==Algorithms for track selection== | ||
One of the most important tasks of a DJ-robot - if not the most important - is track selection. In [[#References|(Cliff, 2006)]] a system is described that takes as input a set of selected tracks and a qualitative tempo trajectory (QTT). A QTT is a graph of the desired tempo of the music during the set with time on the x-axis and tempo on the y-axis. Based on these two inputs the presented algorithm basically finds the sequence of tracks that fit the QTT best and makes sure that the tracks construct a cohesive set of music. The following order is taken in this process: track mapping, trajectory specification, sequencing, overlapping, time-stretching and beat-mapping, crossfading. | One of the most important tasks of a DJ-robot - if not the most important - is track selection. In [[#References|(Cliff, 2006)]] a system is described that takes as input a set of selected tracks and a qualitative tempo trajectory (QTT). A QTT is a graph of the desired tempo of the music during the set with time on the x-axis and tempo on the y-axis. Based on these two inputs the presented algorithm basically finds the sequence of tracks that fit the QTT best and makes sure that the tracks construct a cohesive set of music. The following order is taken in this process: track mapping, trajectory specification, sequencing, overlapping, time-stretching and beat-mapping, crossfading. | ||
In this same article, | In this same article, genetic algorithms are used to determine the fitness of each song to a certain situation. This method presents a sketch of how to encode a multi-track specification of a song as the genes of the individuals in a genetic algorithm [[#References|(Cliff, 2006)]]. | ||
Multiple papers describe new methods of music transcription or MIR (Music Information Retrieval) through which a system can "read" music in order to match the next song to it. [[#References | (Choi & Cho, 2019)]][[#References | (Choi, Fazekas, Cho & Sandler, 2017)]][[#References | (Hamel & Eck, 2010)]]. Also, advances have been made in the field of genre-detection, as described by [[#References | De Léon & Inesta (2007)]], as well as instrument-detection, as described by [[#References | Humphrey, Durand & McFee, 2018)]]. Other methods are using Bayesian probability networks to analyze music based on rhythm, chords and source-separated musical notes [[#References | (Kashino, Nakadi, Kinoshita & Tanaka, 1995)]]. | |||
[[#References | Pasick (2015)]] describes the methods which Spotify uses to generate their "recommended songs" for users. They use their existing playlists and like songs as well as creating a 'personal taste profile' for each of its users. [[#References | Atherton et al. (2008)]] describe an alternative way in which users actively rate each song that is recommended to them by the system. That info is then used to improve the recommendations. | |||
The article of [[#References | Jannach, Kamehkhosh & Lerche (2017)]] focuses on next-track recommendation. While most systems base this recommendation only on the previously listened songs, this paper takes a multi-dimensional (for example long-term user preferences) approach in order to make a better recommendation for the next track to be played. | |||
Other papers about track selection are [[#References | (Yoshii, Nakadai, Torii, Hasegawa, Tsujino, Komatani, Ogata & Okuno, 2007)]][[#References | (Wen, Chen, Xu, Zhang & Wu, 2019)]][[#References |(Shmulevich, & Povel, 1998) ]][[#References | (Pérez-Marcos & Batista, 2017)]] | |||
==Receiving feedback from the audience via technology== | |||
Audiences of people attending musical events generally like the idea of being able to influence performance (Hödl et al., 2017). What is important is the way of interaction with the performers, what works well and what do users prefer? | |||
There are of course many natural ways of interacting such as clapping, cheering and dancing. These elements can be measured to a certain extent with, for example, a cheering meter which was used by Barkhuus & Jorgensen (2008) | |||
In the article of Hödl et al. (2017), multiple ways of interacting are described, namely, mobile devices, as can be seen in the article of McAllister et al. (2004), smartphones and other sensory mechanisms, such as the light sticks discussed in the paper of Freeman (2005). | |||
The system presented by Cliff [[#References|(Cliff, 2006)]] already proposes some technologies that enable the crowd to give feedback to a DJ-robot. They discuss under-floor pressure sensors that can sense how the audience is divided over the party area. They also discuss video surveillance that can read the crowd's activity and valence towards the music. Based on this information the system determines whether the assemblage of the music should be changed or not. In principle, the system tries to stick with the provided QTT, however, it reacts dynamically on the crowd's feedback and may deviate from the QTT if that is what the public wants. | |||
Another option for crowd feedback discussed by Cliff is a portable technology, more in the spirit of a wristband. One option is a wristband that is more quantitative in nature and transmits location, dancing movements, body temperature, perspiration rates and heart rate to the system. Another option is a much simpler and therefore cheaper solution. A simple wristband with two buttons on it; one "positive" button and one "negative" button. In that sense, the public lets the system know whether they like the current music or not, and the system can react upon it. | |||
[[#References | Hoffman & Weinberg (2010)]] describe a robot Shimon which plays the marimba. It can be influenced by other musicians as it used inputs like pitch, rhythm. POTPAL is another robot-DJ that uses top 40 lists, 'beat matching' and 'key matching' techniques and even monitoring of the crowd to improve music choices. [[#References | (Johnson, n.a.)]] | |||
Open Symphony is a web application that enables audience members to influence musical performances. They can indicate a preference for different elements of the musical composition in order to influence the performers. Users were generally satisfied and interested in this way of enjoying the musical performance and indicated a higher degree of engagement[[#References | (Zhang, Wu & Barthet, te perse)]]. | |||
=A first model= | |||
Based on the state of the art and the user needs a first model of our automated DJ system is made. We chose to depict it in a block diagram with separate blocks for the feedforward, the feedback and the algorithm itself. | |||
[[File:first_model.jpg|none|600px|First model of the automated DJ system]] | |||
==Feedforward== | |||
The feedforward part of our system is completely based on the user input. The user has a lot of knowledge about the desired DJ set to be played beforehand. This information is fed to the system to control it. Because this feedforward block is based on user input, it has to answer to the user needs. Below, a scheme is presented to show how the user needs relate to the feedforward parameters. | |||
[[File:feedforward.jpg|none|800px|Feedforward parameters in relation to the user needs]] | |||
The first part of the feedforward is the desired QTT of the set. What a QTT is, is described in the [[#Algorithms for track selection|state of the art]] section. The ability for the user to input a QTT answers to the primary user need of an easy user interface. Providing a QTT to the system also makes it easy for the system to play a structured and progressive set of music, which is a secondary user need. This is in line with the secondary user need that dancers are taken on a cohesive and dynamical music journey. This structure in the music will also keep the audience engaged. | |||
To fulfill the desired QTT certain tracks are delivered to the system to pick from as feedforward. These tracks are delivered via an enormous database with all kinds of music in it, such that the system has enough options to pick from in order to form the best set. In that sense, the system can pick from the audience favourite tracks that are popular and valued by the audience, which are some of our secondary user needs. Since people come to certain music events with certain expectations, the tracks to pick from should be appropriate regarding genre. That way, the audience background is taken into account and it keeps them engaged. This is also an opportunity to limit the algorithm's options for track selection, making the system more stable. Because the database the system can choose from is very large and diverse, the user need of wanting to hear rare, new music is answered. Also, this contributes to an unpredictable set of music that is not boring. | |||
The most important Spotify features that we will use in our technology are "tempo", "danceability", "energy" and "valence". Tempo is just the BPM of the song as defined by existing DSP algorithms. It is a floating point number that has no limit. [https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/ Spotify] describes danceability as "to what extent can people dance on it based on tempo, rhythm stability, beat strength, and overall regularity." This is a floating point number with a range from 0 (not danceable) to 1 (very danceable). Energy is described by Spotify as the "perceptual measure of intensity and activity based on dynamic range, perceived loudness, timbre, onset rate, and general entropy." It is a floating point number with a range from 0 (no energy) to 1 (high energy). Valence represents the degree of positiveness of a song. It is a floating point number that ranges from 0 (very negative) to 1 (very positive). | |||
Furthermore, the system also includes the ability to filter by "song popularity" and "artist popularity". These parameters are a part of Spotify's database, and they both describe the ''current'' popularity of a song and artist respectively. Since these parameters change over time they are not included in the regression model. They are included in the filtering system however, to allow for users to decide how obscure they want their generated music to be | |||
In order to satisfy the audience we have to feedforward background information of the audience members to the system. In that way the system has knowledge about what the current audience is into. What someone is into could include their preferences regarding audience features based on their Spotify profile and their favourite or most hated tracks. This answers to the primary user needs of making the system something extraordinary and more valued than a human DJ because a human DJ can never know this information of every audience member. This also makes that the system is better than a human DJ at gathering information regarding audience appreciation, which is also a primary user need. It also answers to the secondary user needs of keeping balance between familiar and new music (because the system knows which tracks are familiar) and audience members wanting to express themselves - be it by providing information to a computer. It also values the DJ's desire to play similar tracks to what the audience is into and the desire to create a collective experience by means of a music set. This collective is generated because every audience member contributes a part to the feedforward of the system. | |||
This | |||
==Feedback== | |||
This | The feedback of the system consists of sensor output. This is the part where the audience takes more control. The feedback sensor system detects how many people are present on the dance floor, relative to the rest of the event area. This can be done by means of pressure sensors in the floor. This information cues whether the current music is appreciated or not. Another cue for appreciation of the music can be generated via active feedback of the crowd. For example, valence can be assessed by the public by means of technologies described in the [[#State of the Art|state of the art]] section. Because audience feedback is not commonly used at music events, the primary user need of providing something special and extraordinary is answered. The ability for the crowd to give feedback answers the primary user need that the system should be better at gathering information regarding audience appreciation than a human DJ. This ability also lets the public as a whole have influence on the music, which creates a collective experience. Additionally, it answers the secondary user need of having control over the music being played. In that sense, the track selection procedure takes the audience reaction into account such that it comes up with tracks that are valued by the audience members. This also lets the public control whether the music is predictable or not, which should keep them engaged. | ||
The other part of sensory feedback is the audience energy level. This energy level may include the activity or movement of the audience members. This can be measured passively by means of a wristband with different options for sensing activity or energy by means of heart rate, accelerometer data, sweat response or other options described in the [[#State of the Art|state of the art]] section and in the [[#The Effenaar|conversation with the Effenaar]]. The incorporation of audience energy level feedback answers to the primary user need of gathering information about the audience appreciation in a better way than a human DJ can. It also answers to the secondary user need of making the musical presentation reflect the audience energy level. | |||
This | |||
Below, a scheme is presented with all the user needs that call for feedback sensors. | |||
[[File:feedback_sensors.jpg|none|800px|User needs in relation to feedback sensors]] | |||
==The algorithm== | |||
Based on the feedforward and feedback of the crowd, the tracks to be played and their sequence are selected as described [[#Excitement matching with QET|here]]. | |||
The next step in the algorithm is overlapping the tracks in the right way. Properly working algorithms that handle this task already exist. For example, the algorithm described in [[#References|(Cliff, 2006)]]. We will describe the working principles of that algorithm in this section. The overlap section is meant to seamlessly go from one track to the other. In the described technology the time set for overlap is proportional to the specified duration of the set and the number of tracks, making it a static time interval. Alterations to the duration of this interval are made when the tempo maps of the overlapping tracks produce a beat breakdown or when the overlap interval leads to an exceedance of the set duration. | |||
If the system wants to play a next track in a smooth transition but there is a difference between the tempo (BPM) of the current track and the next track, time-stretching and beat-mapping need to be applied. Time-stretching will slow down or bring up the tempo such that the tempo of the current and next track are nearly identical in order to produce a smooth transition to the next track. Technically speaking time-stretching is a (de)compression of time or changing the playback speed of the samples and applying proper interpolation in order to maintain sound quality. Once the tempos match, the beats of the two songs need to be aligned in order to acquire zero phase difference to avoid beat breakdown. | |||
[[ | The last step is proper cross-fading. Although ramping down the volume of the current track while ramping up the volume of the next track is often sufficient for a good cross-fade, the algorithm described uses more sophisticated techniques to achieve proper cross-fading. The algorithm analyses the audio frequency-time spectograms of the two tracks to be cross-faded. This can be used to selectively suppress certain frequency components in the tracks such that current melodies seem to disappear and the next melody becomes more prominent. It can also filter out components of tracks that clash with each other, allowing for a smooth cross-fade [[#References|(Cliff, 2006)]]. | ||
== | =The final product: Di-J= | ||
==System overview== | |||
[[ | Below a graphic overview of the system is given. Important to note is that the grey area is the scope of our project; to design the rest is not feasible within our time budget. Besides, a lot of research is already done on the modules outside the grey region. Mixing tracks together seamlessly is a desirable skill for all DJs and therefore a skill for which a lot of DJs seek help in the form of technology. Due to this high demand, a lot of properly working mixing algorithms already exist, for example [[#Algorithms for track selection|(Cliff, 2006)]]. Certain feedback sensors that measure the excitement of the audience also already exist. A lot of wearable devices that measure all sorts of things like heart rate or motion already exist and have been used. One can look at one of the [[#Receiving feedback from the audience via technology|prior]] sections to gain information on this. Another real-life example is [[#The Effenaar|the Effenaar]] that has used technology to measure brain activity and excitement among attendees of a music event. This lets us make the assumption that the mixing and the feedback part will work. | ||
The | Globally, the system works as follows. The system has a large database to pick music from. This database contains for every song an "excitement" value that is based on a [[#Excitement prediction with multiple regression|multiple regression]] output of the Spotify audio features "valence" and "energy". The database is freely available to the user. The music of this database is let through the [[#Pre-filter|pre-filter]]. The pre-filter filters the songs in the database on genre and Spotify features "tempo", "danceability", "energy", "valence", "song popularity" and "artist popularity". This input is made possible by the [[#User interface|user interface]]. In that sense, the pre-filter puts out an array of tracks that is already filtered according to the user's desire. Next, the filtered tracks will be matched according to the desired [[#Algorithms for track selection|QET]] (we will use an excitement graph instead of a tempo graph but the principle is the same). The result of this matching is a sequence of tracks that creates the playlist to be played for that evening (or morning?). This playlist is also freely available to the user. The playlist is then fed to the [[#The algorithm|mixing algorithm]] to make sure that the system outputs a nicely mixed set of music to enjoy. This music is rated on excitement by means of [[#Receiving feedback from the audience via technology|feedback sensors]]. This feedback is used to update the playlist via the excitement matching module. Thus, if the audience is not happy with the currently playing music the system can act upon that. | ||
[[File:system_overview_graphic.JPG|none|800px|System overview]] | |||
==User interface== | |||
<br/> | |||
<b> User Interface of Web-Application</b> | |||
<br/> | |||
When the user browses to the webpage, he/she first encounters a window where they can input their Spotify account. This way, the generated playlist is automatically added to the user's Spotify account. When the Spotify account has been entered, the user lands on the main page. On this page, the user can enter all the different settings he/she wants. He/she can make adjustments to the <i>Filters</i>, where a specific range of values can be selected for multiple variables. The user can then choose the trajectory for the excitement over time in the <i>Excitement Graph section</i>. There are three different options: <i>wave</i>, in which the excitement goes up and down a few times, <i>ramp</i>, in which the excitement gradually builds up over time, and <i>plateau</i>, in which the excitement starts low, gets up to a certain level and stays there to eventually build down. Then the user can select specific genres in <i>Genres</i> from a list of 15 different genres. Once the user is happy with the settings he/she chose, the <i>Generate Playlist</i> button at the bottom of the page can be clicked and a playlist will be developed and automatically added to the user's Spotify account. | |||
<br/> | |||
<br/> | |||
Why we chose for this particular layout and design of the Webpage can be found in the section [[#Validation of the user needs|Validation of the user needs]] under User test 1: The user-interface. | |||
<br/> | |||
<gallery mode="nolines" widths=500px heights=400px> | |||
File:spotify.PNG|The Spotify Page | |||
File:pagina.PNG|The Full Page | |||
</gallery> | |||
<gallery mode="nolines" widths=500px heights=400px> | |||
File:filters_2.PNG|The Filters section with specific settings | |||
File:excitement.PNG|The Graph displaying the different excitement trajectories | |||
</gallery> | |||
== | <gallery mode="nolines" widths=500px heights=400px> | ||
File:genres.PNG|The Genres section with some selected | |||
File:button.PNG|The button you press to generate the playlist | |||
</gallery> | |||
The | ==Pre-filter== | ||
The goal of the pre-filtering is to give users the ability to discard several tracks and make sure that said tracks do not end up in their final playlist. There are two categories in the pre-filter. The 'filter' section provides the ability to set an upper and lower bound for certain parameters. the 'genre' section provides the ability to either include or exclude certain genres. | |||
The database is then filtered according to the user's desire. The algorithm excludes all songs that do not have their parameters within the set thresholds. From this, a new, filtered, list is created, which then gets sorted in order of excitement. The song with the lowest excitement score gets stored since this will be the 'floor' on which the QET will begin. The same is done with the song that has the highest energy score since this allows the QET matching algorithm to specify the excitement value of the global maximum within the graph. It can then subsequently calculate the desired excitement level at any point in time during the set. | |||
[[File:Prefilter.png |800px]] | |||
==Excitement prediction with multiple regression== | |||
In order to come up with a useable product, we need to narrow down the scope of this project. We decided to focus on engineering a proper pre-filter and feedforward system for track selection, based on the Spotify audio features. We mainly focus on the features "energy" and "valence". Even after extensive research, no formal definition or equation was found for the Spotify feature "energy". [https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/ Spotify] itself describes it as a perceptual measure of intensity and activity based on dynamic range, perceived loudness, timbre, onset rate, and general entropy. It is a floating-point number with a range between 0 and 1. The same holds for the "valence" feature; no equation can be found but Spotify describes it as a representation of the positivity or negativity of a track. It is a floating-point number with a range of 0 to 1 where values close to 1 represent positive songs, whereas values close to 0 represent sad songs. | |||
The word excitement is very much linked to a highly energized state of positive feelings. As it is given a definition by the [https://www.oxfordlearnersdictionaries.com/definition/english/excitement Oxford dictionary]: "the state of feeling or showing happiness and enthusiasm." That is why we chose the features "energy" and "valence" to predict this variable. | |||
Continuing, we rated 152 songs on "excitement" and then performed a multiple regression analysis with the Spotify features "energy" and "valence" to come up with a prediction | Continuing, we rated 152 songs on "excitement" and then performed a multiple regression analysis with the Spotify features "energy" and "valence" to come up with a prediction equation for "excitement" based on these features. We rated "excitement" such that it represents how enthusiastic the song is, how excited one gets by listening to it. It is a floating-point number ranging from 0 to 1. Values close to 0 represent songs that will not get people enthusiastic, whereas values close to 1 represent songs that are very exciting and fosters enthusiasm among listeners. Please note that for now the feature "excitement" is completely made up by ourselves and inherently subjective in nature. However, we deemed "excitement" as it is defined now a good parameter for track selection that makes the audience happy. We picked songs from three different genres of dance music: Techno, Hardstyle, and Disco. We wanted to stick to dance music, but to diversify our research we considered three distinct genres. The results of the regression analyses are presented in the proceeding sections. | ||
==Multiple regression per genre== | ===Multiple regression per genre=== | ||
The first step in our analysis was to do a multiple regression for every distinct genre in our database - being either Techno, Hardstyle or Disco - to see whether the | The first step in our analysis was to do a multiple regression for every distinct genre in our database - being either Techno, Hardstyle or Disco - to see whether the equation for "excitement" differs between genres and whether it gives any significant results to start with. | ||
===Multiple regression techno=== | ====Multiple regression techno==== | ||
The multiple regression model considering techno only turned out significant, | The multiple regression model considering techno is the only one which turned out significant, R² = 0.1, F(2, 60) = 3.39, p = 0.04. Here, "excitement" was based on the Spotify features "energy" and "valence". It means that for techno the appropriate equation for excitement is the following: ex = 0.39 + 0.183*en + 0.208*v. Where "ex" is excitement, "en" is energy and "v" is valence. The exact results are presented in the table. | ||
{| class="wikitable", border="1" style="border-collapse:collapse" | {| class="wikitable", border="1" style="border-collapse:collapse" | ||
| Line 584: | Line 273: | ||
|} | |} | ||
===Multiple regression hardstyle=== | ====Multiple regression hardstyle==== | ||
The model for hardstyle turned out non-significant, | The model for hardstyle turned out non-significant, R² = 0.05, F(2, 37) = 0.91, p = 0.41. It means that with this sample of hardstyle songs and their excitement ratings, no fitting equation is found by linear regression. The exact results are presented in the table. | ||
{| class="wikitable", border="1" style="border-collapse:collapse" | {| class="wikitable", border="1" style="border-collapse:collapse" | ||
| Line 615: | Line 304: | ||
|} | |} | ||
===Multiple regression disco=== | ====Multiple regression disco==== | ||
The model for disco turned out non-significant, | The model for disco turned out non-significant, R² = 0.1, F(2, 46) = 2.55, p = 0.09. It means that with this sample of disco songs and their excitement ratings, no fitting equation is found by linear regression. The exact results are presented in the table. | ||
{| class="wikitable", border="1" style="border-collapse:collapse" | {| class="wikitable", border="1" style="border-collapse:collapse" | ||
| Line 646: | Line 335: | ||
|} | |} | ||
==Multiple regression across genres== | ===Multiple regression across genres=== | ||
In the next step, we took all genres together and performed the same multiple | In the next step, we took all genres together and performed the same multiple regression analysis on that dataset. This regression turned out significant, R² = 0.06, F(2, 149) = 4.99, p = 0.008. It means that there is a linear equation to predict "excitement" of a track based on the audio features "energy" and "valence" if you consider the three dance genres together. This equation is as follows: ex = 0.45 + 0.16*en + 0.07*v. If we generated this new predicted value from the equation, took the absolute difference between this predicted value and the "real" value for "excitement", the mean difference was 0.07 with a standard deviation of 0.06. All exact results can be found in the table below. | ||
{| class="wikitable", border="1" style="border-collapse:collapse" | {| class="wikitable", border="1" style="border-collapse:collapse" | ||
| Line 677: | Line 366: | ||
|} | |} | ||
==Discussion of the regression results== | ===Discussion of the regression results=== | ||
When we took each genre separately to come up with a prediction | When we took each genre separately to come up with a prediction equation for "excitement", the results were not always promising. Only the regression for techno turned out significant. We think that this was mainly due to the small sample size (only 40, 49 and 63 songs used in every list) and the inherent subjective nature of the feature "excitement". Only one person rated this feature for every song making it a very subjective, personal variable. However, we should look beyond the results of this regression analysis only. In the future when our system will be used at large music events, the variable "excitement" can be deduced in a much better way than by quantifying the subjective opinion of one person. One option could be to let every attendee of a music festival rate about 10 relevant songs before attending the event. If 10,000 people do this the system can create 100,000 data points to base the regression on, instead of 152. One can imagine that this would give much better results than the provided analysis. Besides, when considering the regression analysis across genres we already came up with a model that has an average error of only 7%. One can imagine how small the error would become if 100,000 data points are used. | ||
Another option could be to generate the "excitement" information in a more physical sense. For example based on information gathered from heart rate monitors and/or brain activity sensors as used by | Another option could be to generate the "excitement" information in a more physical sense. For example, based on information gathered from heart rate monitors and/or brain activity sensors as used by [[#The Effenaar|the Effenaar]]. This information is more quantitative in nature than people's subjective opinion on "excitement" level of a track. So, maybe this could function as input that generates a more robust equation for "excitement". | ||
Concluding, how the information on "excitement" is gathered is a point of discussion as well as an opportunity for improvement. What is most important is that a multiple regression model might be a good way to incorporate feedforward for track selection in our system. In that sense, the value of this particular research is not in the results of these regressions but in the method behind it. | Concluding, how the information on "excitement" is gathered is a point of discussion as well as an opportunity for improvement. What is most important is that a multiple regression model might be a good way to incorporate feedforward for track selection in our system. In that sense, the value of this particular research is not in the results of these regressions but in the method behind it. | ||
= | ==Excitement matching with QET== | ||
One module of the system is the excitement matching algorithm. What we mean by this is a system that takes in a graph (which can be a set of points) from the user with the desired course of "excitement" of the music set. This is called a Qualitative Excitement Trajectory (QET). Thus, we want a module that takes in a QET from the user and transforms it into a mathematical equation, because a graph is what humans can work with, while an equation is what computers can work with. With this mathematical equation, the module can output different values of "excitement" for every point in time in the music set and thus also outputs "excitement" values at points where a new music track should start. These latter points can then be matched with existing music tracks with an "excitement" value close to this desired value by a Spotify filter. Because we want to answer the user need of keeping the system simple and easy to use, we decided to let the user input the QET by means of "key points of excitement" in the music set. This is easier than drawing a whole graph. Thus, the user can specify at what points in time it desires certain values of excitement and the system does the rest. We created a MATLAB script to simulate such software and prove its working. | |||
===A script for QET matching algorithm=== | |||
As an example, we chose as user input a 30 minutes long music set, divided in 1-minute intervals. In the example case the user inputs the following desires: start the set at an excitement of 0.7, after 5 minutes drop to 0.6 within 5 minutes, continuing climb to 0.8 within 10 minutes, then drop to 0.7 again within the next 5 minutes and finish of the set by climbing to the maximum excitement of 1.00 in the last 5 minutes. This input from the user is read from a ".txt" file. This file is transformed into data points and depicted below. | |||
[[File:key_data_points.jpg|400px|Key data points from the user]] | |||
The next step is to interpolate for values between these key excitement points (in order to get a value for every minute of the set). We chose to use simple linear interpolation which gave decent results, however other sorts of interpolation are also possible and easily implemented using MATLAB. After interpolation, a polynomial fit is applied in order to come up with a mathematical equation for the QET. In this example, a 7th order polynomial was created to describe the QET. The result is depicted below. | |||
[[File:interpolation_QET_including_bars.jpg|400px|Interpolation result QET]] | |||
One can see that the result is quite promising. The polynomial curve follows the desired QET without an undesirable large error. The coefficients of the polynomial curve are also outputted by this script and can thus be used to construct a mathematical equation for the QET. This equation can then again be sampled (with a sampling period depending on the desired song length) to obtain the distinct excitement values the songs should have in time. In that way, the system can construct and output an ordering of the provided tracks based on this sampled equation for QET and the algorithm works. These tracks are depicted as the orange bars in the graph. In this example case a duration of 2 minutes is chosen for every song such that a lot of music can be played while there is time enough for every song to play its core part. The output of the system is a ".txt" file that contains the excitement ratings of the tracks in the generated set from the user input. The MATLAB script that does all these calculations is provided below. | |||
<!-- invisible text [[File:code_interpolation.jpg|MATLAB code]] --> | |||
<nowiki>%Input the key data points (degree of polynomial should be < data points) | |||
QET_matrix = readmatrix('sample_input.txt'); %First row is time, Second row is excitement | |||
x_keydata = QET_matrix(1,:); %The time points from the user input file | |||
y_keydata = QET_matrix(2,:); %The corresponding excitement ratings | |||
p_keydata = polyfit(x_keydata,y_keydata,3); %Get polynomial coefficients for the key data points | |||
f_keydata = polyval(p_keydata,x_keydata); %Generate a fucntion from coefficients | |||
figure; | |||
plot(x_keydata,y_keydata,'o',x_keydata,f_keydata,'-'); %Not a desirable outcome -> use interpolation | |||
title("Input of key data points and polynomial fit"); | |||
xlabel("Time [m]"); | |||
ylabel("Excitement rating [0,1]"); | |||
%Interpolation for the key data points | |||
samples = max(x_keydata); %#samples to interpolate | |||
x_interpolation = 1:samples; | |||
for i = 1:samples | |||
y_interpolation(i) = interp1(x_keydata,y_keydata,i); %Linear interpolation between input points | |||
end | |||
%Get a formula for the graph | |||
n = 7; %Degree of the polynomial | |||
p_polynomial = polyfit(x_interpolation,y_interpolation,n); %Get polynomial coefficients for the interpolated data | |||
f_polynomial = polyval(p_polynomial,x_interpolation); %Make a function from these coefficients | |||
%Create discrete bars (the songs) | |||
songlength = 2; %In minutes | |||
for i = 1:songlength:length(f_polynomial) | |||
track_histogram(i) = f_polynomial(i); %Generate the discrete tracks | |||
end | |||
figure; | |||
hold on; | |||
plot(x_interpolation,y_interpolation,'o',x_interpolation,f_polynomial,'-'); %Plot graphs | |||
alpha(bar(track_histogram,songlength),0.1); %Plot bars | |||
ylim([0.6 1.05]); | |||
title("Interpolation result and polynomial fit"); | |||
xlabel("Time [m]"); | |||
ylabel("Excitement rating [0,1]"); | |||
legend("Interpolated values", "Polynomial curve", "Tracks on the set"); | |||
%Output the formula coefficients | |||
fprintf("Fitted formula coefficients (a1*x^n + a2*x^(n-1) + ...): \n"); | |||
for i = 1:n+1 | |||
fprintf("%d \n",p_polynomial(i)); %Prints the coefficients | |||
end | |||
%Output the tracks' excitement rating to a text-file | |||
fileID = fopen('sample_output.txt','w'); | |||
fprintf(fileID,"%1.3f\r\n",track_histogram); | |||
fclose(fileID);</nowiki> | |||
===A GUI for QET matching=== | |||
Given the time budget, it was unfeasible to integrate the QET matching algorithm in the Java-based website. Therefore, we decided to let it function as a standalone application that comes as an extra to our system. Because the algorithm is of value to the project as a whole we worked further on it and created an executable GUI for it. The working principles are exactly the same as described in the prior sections, but now it is easier for the user to put in his or her desired QET via a visual tool. A screenshot of the tool is provided below. | |||
[[File:GUI_QET.jpg|600px|A graphical interface for QET matching]] | |||
If the user follows through the numbered steps it can totally control the desired QET of his or her music set. In the first step, the user defines the duration of the music set in minutes. In the next step, the user defines the number of time points he or she wants to control - the depth of control so to speak. In the third step, the user makes use of a slider to set the desired excitement values of all the time points. If the user makes any mistakes in this, it is possible to go back to previous points. In the last step, the user defines the length that he or she wants to hear all songs and then presses "Generate matching values". When this button is pushed the user gets to see the graph with the interpolation result, polynomial fit and bar graph of the tracks - as described and displayed in the prior section. Also, this bar graph of the tracks and their excitement values is transformed into data (an array) and outputted to a ".txt" file so the rest of the system could work with it. | |||
By providing the user with a visual tool for deciding on a QET, the system answers to the primary user need of an easy to understand user interface for which no experts are needed to operate it. Besides, it answers to the secondary user needs of a structured and progressive music set and that dancers are taken on a cohesive and dynamic music journey. | |||
=Validation of the user needs= | |||
In order to make sure the product satisfies the user needs, the product needs to be validated. For each user need a method of validation is presented. However, due to limited time and/or resources, not all user needs were able to be verified. The primary user need [[#User test 1: The user-interface|"The system's user interface is easy to understand, no experts needed"]] and the secondary user need [[#User test 2: The track-selection | "Track selection should fit the audience background"]] were possible to validate. The results of these tests are also discussed in this section | |||
==User test 1: The user-interface== | |||
In order to validate the satisfaction of the user need: "The system's user interface is easy to understand, no experts needed.", a user test has been executed. This user-test consisted of a survey, which asked the users question about different user-interfaces. This test has been executed with 14 people. | |||
===The test set-up=== | |||
The people that were part of this user test were shown three different user-interfaces, which are displayed below: | |||
<gallery mode="nolines" widths=500px heights=400px> | |||
File:UI1-15.PNG|UI1 | |||
File:UI2-15.PNG|UI2 | |||
</gallery> | |||
<gallery mode="nolines" widths=500px heights=400px> | |||
File:UI3-15.PNG|UI3 | |||
</gallery> | |||
UI1 and UI2 differ in style: UI1 has a neumorphic design, where UI2 has a very simplistic and "flat" style. UI2 and UI3 are shown to demonstrate the difference in layout: UI2 has all panels on one page, where UI3 consists of three separate pages. Then, the people that were apart of this test were asked to fill in a survey about these user-interfaces. The survey that was executed consists of three questions: | |||
* Which do you prefer: All panels on one page, or on three separate pages (UI2 or UI3)? | |||
* Is it clear what the values on the page mean and how these can be adjusted? If not, what is unclear? | |||
* Mention an aspect of the styling which you like for both styles (UI1 and UI2). | |||
After all, users took the survey, the results could be analyzed | |||
===The results=== | |||
<b>Question 1: Which do you prefer: All panels on one page, or on three separate pages?</b> | |||
Almost all users preferred the style with all panels on one page over the style with three separate pages (94% vs 6%). | |||
[[File:UIQ1.png|500px|Question 1]] | |||
<b>Question 2: Is it clear what the values on the page mean and how these can be adjusted? If not, what is unclear?</b> | |||
56% of the users found the UI to already be very clear. However, the other 44% had some small comments about the existing interface. The majority of this group (24%) did not understand the meaning of the variable 'valence'. Other comments were about not understanding the difference between tempo and energy (8%) and about the range of the values not being clear, i.e. axes missing (14%). | |||
[[File:UIQ2.png|500px|Question 2]] | |||
<b>Question 3: Mention an aspect of the styling which you like for both styles.</b> | |||
For style 1, the majority of the users enjoyed the finished (44%) and professional (33%) look. A small part of the users liked this UI having a title (6%). However, some users did not enjoy this interface at all and decided not to give a strong point for the styling of this UI. | |||
[[File:UIQ3.1.png|500px|Question 3, style 1]] | |||
Style 2 was preferred more over style 1 since a smaller part of the users did not have a strong point for the style (6%). The majority of the users liked this style for it being easy to understand due to its simplicity (47%). Other users enjoyed the colors of this UI (31%) or that this style had a sleek design (17%). | |||
[[File:UIQ3.2.png|500px|Question 3, style 2]] | |||
<b>Other comments</b> | |||
The users were also given an option to give some extra feedback. These comments included: | |||
* Giving the panels a title so its purpose would be even more clear; | |||
* Showing the definition of a parameter (e.g. valence) when hovering your mouse above this parameter would increase the clarity of the page; | |||
* Putting range values beneath the sliders would make the interface more clear. | |||
<br/> | |||
==User test 2: The track-selection== | |||
To test the user need: "The system selects appropriate tracks regarding genre", a second user test was performed. This test was focussed on whether the "danceability", "energy" and "valence" values of the filtered music songs would match people's expectations. | |||
===The test set-up=== | |||
For this test, the three different parameters were tested separately. Furthermore, the features were split up into 5 parts. Each of them consisting of a range of 0.2. Starting at 0 to 0.2 and ending at 0.8 to 1.0. With these filter values 5 playlists were created for every feature, so 15 lists in total. These playlists consisted of 50 songs. This way, possible errors of a single song's feature value were eliminated. Moreover, the test persons had 50 songs to base their judgment on. Genres were not taken into account when filtering the songs, this would result in a more diverse set of songs. For the sake of convenience, the most popular songs were used. Users would then easier recognize the songs. | |||
[[File:division2.png|600px|Division of the playlists]] | |||
The test was split into two parts. To test how clearly the differences are, the first part consisted of comparing the two extreme regions and the middle one. List A, C, and E according to the figure. Then it was tested whether the differences would still be recognizable coming closer to the 0.5 values. Therefore lists B and D were compared. Obviously the test persons did not know the correct order. They were asked to sort the given playlists from most to least danceable, energetic or valent. So, first, they compared A, C, and E with each other, followed by the comparison of B and D. This means that there were six tests in total. | |||
===The results=== | |||
====Test 1==== | |||
These percentages are based on each separate playlist a participant has chosen correctly. This means that if someone has chosen only one of the three lists correct. There answer would not be completely wrong, but there answer would be 33.3% right. These results can be seen in the following table. | |||
{| class="wikitable", border="1" style="border-collapse:collapse" | |||
|- | |||
! scope="col"| | |||
! scope="col"| <b>Danceability</b> | |||
! scope="col"| <b>Energy</b> | |||
! scope="col"| <b>Valence</b> | |||
|- | |||
! scope="row"| <i>Correct answers</i> | |||
| 89.6% | |||
| 89.6% | |||
| 93.8% | |||
|- | |||
|} | |||
====Test 2==== | |||
For the second test, there were only 2 playlist to order, so the answer was either right or wrong. This test resulted in the following outcome. | |||
{| class="wikitable", border="1" style="border-collapse:collapse" | |||
|- | |||
! scope="col"| | |||
! scope="col"| <b>Danceability</b> | |||
! scope="col"| <b>Energy</b> | |||
! scope="col"| <b>Valence</b> | |||
|- | |||
! scope="row"| <i>Correct answers</i> | |||
| 93.8% | |||
| 87.5% | |||
| 93.8% | |||
|- | |||
|} | |||
Looking at these results it can be concluded that people’s perception of danceable, energetic and valent music fairly corresponds to the numeric values Spotify has assigned to these songs. However it must be noted that some people said that it was a difficult task due to the diversity in style of the 50 songs in one playlist. | |||
=Conclusion= | |||
For the conclusion of this project, we want to mention multiple things. We want to share our insights in the area of the State of the Art, our practical solutions and systems, and also the insights gained about our users. | |||
<br/> | |||
<b> State of the Art</b> | |||
In the [[#State of the Art|State of the Art]] section we discussed a few things. We described [[#Defining and influencing characteristics of the music | defining and influencing characteristics of the music]], where we explained audio features like energy, tempo, danceability, and valance and where they come from. [[#References|(Feldmeier, 2003)]][[#References|(Feldmeier & Paradiso, 2004)]][https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/ Spotify] | |||
We also discussed multiple [[#Algorithms for track selection|algorithms for track selection]]. There we introduced the Qualitative Tempo Trajectory (QTT)[[#References|(Cliff, 2006)]], Music Information Retrieval [[#References | (Choi & Cho, 2019)]][[#References | (Choi, Fazekas, Cho & Sandler, 2017)]][[#References | (Hamel & Eck, 2010)]], and genre-, instrument-, chord- and rhythm-detection methods[[#References | De Léon & Inesta (2007)]][[#References | Humphrey, Durand & McFee, 2018)]][[#References | (Kashino, Nakadi, Kinoshita & Tanaka, 1995)]]. [[#References | Pasick (2015)]] described the methods which Spotify uses to generate their "recommended songs" for users. Many other sources were quoted about track-seletion or -recommendation. | |||
We then described multiple ways of [[#Receiving feedback from the audience via technology |receiving feedback from the audience via technology]]. What was important to know is that audiences of people attending musical events generally like the idea of being able to influence performance [[#References|(Hödl et al., 2017)]]. We then mentioned many different ways of audience feedback. One that suited our project well was a wristband that is more quantitative in nature and transmits location, dancing movements, body temperature, perspiration rates and heart rate to the system[[#References|(Cliff, 2006)]]. | |||
<br/> | |||
<b> Systems and Solutions </b> | |||
We used many different methods in our final system. We used inputs such as genre-selection, specific ranges for filters such as tempo, danceability, and popularity, as well as a trajectory of the excitement over the time of a specific set. We used the audio features of Spotify and integrated it with our selfmade QET, consisting of a multiple regression model taking energy and valence. There is promise to the usage of these parameters for the creation of a playlist. The system needs to become a little smarter to be able to fully take advantage of them. Adding artificial intelligence into the mix might allow us to see patterns in the data that we ourselves could not find. | |||
<br/> | |||
<b> Users </b> | |||
We, of course, took the needs of the users into account very much. As mentioned before, audiences of people attending musical events generally like the idea of being able to influence performance [[#References|(Hödl et al., 2017)]]. We defined the user needs in [[#User| Users]]. From our conversation with the Effenaar we gathered that there was a market for an automated robot DJ, not to replace the main act, but to replace the playlists or DJs before and after the main act. | |||
Our validation shows that users do have a pretty good sense of music. They can quite well differentiate between a track with little and high danceability for example. This is important for our product, since user's choices ought to be made based on these parameters. | |||
<br/> | |||
<b> Conclusion </b> | |||
All in all, the system shows promise, but needs some refinements to actually be marketable. Casual users might desire easier controls, while music venues might want finer control. The current system should serve as a proof of concept for a more elaborate system. One that is hopefully based on more actual parties, since we could not test for those scenarios due to the circumstances. | |||
=Discussion= | |||
The main discussion point of this project would be the lack of in the field testing. While, partially due to the Corona circumstances, it would have been nice to try and be more creative with solutions to overcome this problem. The next steps would definitely include doing these tests, to validify the usefulness of the system in a real-life scenario. Although the User Interface was validated by people, it could have helped to include some professional or amateur DJs in these tests. We have had contact with an amateur DJ who liked our project and concept, but we have not done a formal user test or validation with him. For many decisions, we based our choice on the information of Spotify or other sources, who have done user tests and have a good understanding of the general taste. This validates our project to a certain extent, but it is always better to rely on own results. | |||
The project, overall, went well. We had a meeting every week where we discussed our findings and updated each other on our progress. We had a clear division of labour during this project, so everyone knew what his/her responsibilities were. However, not every member of the group contributed the same amount of work. This could have had multiple reasons. One is that not everyone was as knowledgable in the area of coding, of which there was a lot. The other reason could be that we did not properly consider how to divide the tasks in a way that everyone could contribute the same. | |||
At first, we had very big ambitions. We wanted to create a fully autonomous Robot DJ, possibly with accompanying light show and physical robot. During the project, with the help of our coaches, we were able to specify the area which we wanted to focus on. This way we were able to create something working, complete, and well designed because we could really focus on this one system instead of a large system with many different aspects. | |||
=Future Works= | |||
There are multiple topics that need refinement if the product were to actually come to market. The following paragraphs summarize some of the point of improvement. | |||
==Better handle input== | |||
The user input currently gets literally and linearly translated to the filter. It would be benificial to the system if this part became smarter. It currently is quite easy to set the sliders in a way where no songs meet the criteria. This should be improved. | |||
[[File: | Improved in this area lead to a better output, as well as a better user experience. Developments here would bridge the gap from specialized software for users wanting someting specific, to more casual users who might use the application more casually. | ||
Furthermore, the user should be able to set a certain length for the set. This was currently not realized due to time constraints, but should definitely be implemented into the actual system, since the QET diagram only makes sense with the correct timing. | |||
==Turing tests== | |||
Due to all the current social distancing measures it is not possible to test our final product in practise. However different kinds of Turing tests have been invented. | |||
The first test would be to hire a café or disco were our DJ would take care of the music. The guest would of course not know that the DJ is not a human. But for their illusion, someone will be standing behind a DJ booth to make it look like the music is indeed arranged by a human. To measure the popularity of the café that night, different guests will be asked what they think of the music. Also the average amount of guests per hour will be counted. Because the amount of consumed alcohol would influence this rating, should the results be adjusted to what time in the evening it is. To get significant results. These test have to be performed several nights. As a control group to test the normal popularity of this café or disco, there should also be tested with a human DJ for several times. | |||
An easier but similar test would be to conduct our test in a silent disco. Silent discos often use RGB headphones with 3 different music channels with 3 different DJs playing. The headphone will turn red, green or blue, depending on which channel it is listening to. One of these channels could be our robot DJ. Thereafter the average percentage of the guest listening to “our” channel over the night could be measured. Doing this several nights would reduce the chance of the human DJs having a bad day and it could be calculated whether people rather listen to “our” music set or that of some other human DJ. | |||
=Who's Doing What?= | |||
==Personal Goals== | |||
The following section describes the main roles of the teammates within the design process. Each team member has chosen an objective that fits their personal development goals. | |||
{| class="wikitable" style= | |||
!style="text-align:left;"| Name | |||
!style="text-align:left"| Personal Goal | |||
|- | |||
| Mats Erdkamp || Play a role in the development of the artificial intelligence systems. | |||
|- | |||
| Sjoerd Leemrijse || Gain knowledge in recommender systems and pattern recognition algorithms in music. | |||
|- | |||
| Daan Versteeg || | |||
|- | |||
| Yvonne Vullers || Play a role in creating the prototype/artificial intelligence | |||
|- | |||
| Teun Wittenbols || Combine all separate parts into one good concept, with a focus on user interaction. | |||
|} | |||
==Planning== | |||
Based on the approach and the milestones, goals for each week have been defined to use as a planning. This planning is not definite and will be updated regularly, however it will be a guideline for the coming weeks. | |||
<br> | |||
<b>Week 2</b> | |||
<br> | |||
Goal: Do literature research, define problem, make a plan, define users, start research into design and prototype | |||
<br/> | |||
<b>Week 3</b> | |||
<br> | |||
Goal: Continue research, start on design | |||
<br/> | |||
<b>Week 4</b> | |||
<br> | |||
Goal: Finish first design, start working on software. | |||
<br/> | |||
<b>Week 5</b> | |||
<br> | |||
Goal: Work on software | |||
<br/> | |||
<b>Week 6</b> | |||
<br> | |||
Goal: Finish software , do testing | |||
<br/> | |||
<b>Week 7</b> | |||
<br> | |||
Goal: Finish up the last bits of the software | |||
<br/> | |||
<b>Week 8</b> | |||
<br> | |||
Goal: Finish wiki, presentation | |||
[[File:timeline.png|750px|The timeline for this project]] | |||
==Weekly Log== | |||
The weekly log can be found here: [[Weekly Log PRE2019 3 Group15]]. | |||
=References= | =References= | ||
| Line 773: | Line 752: | ||
<br/> | <br/> | ||
Zhang, L., Wu, Y., & Barthet, M. (ter perse). <i>A Web Application for Audience Participation in Live Music Performance: The Open Symphony Use Case</i>. NIME. | Zhang, L., Wu, Y., & Barthet, M. (ter perse). <i>A Web Application for Audience Participation in Live Music Performance: The Open Symphony Use Case</i>. NIME. Retrieved from https://core.ac.uk/reader/77040676 | ||
==Summary of Related Research== | |||
This patent describes a system, something like a personal computer or an MP3 player, which incorporates user feedback in it's music selection. The player has access to a database and based on user preferences it chooses music to play. When playing, the user can rate the music. This rating is taken into account when choosing the next song. (Atherton, Becker, McLean, Merkin & Rhoades, 2008) | |||
<br/> | |||
This article describes how rap-battles incorporate user feedback. By using a cheering meter, the magnitude of enjoyment of the audience can be determined. This cheering meter was made by using Java's Sound API. (Barkhuus & Jorgensen, 2008) | |||
<br/> | |||
Describes a system that transcribes drums in a song. Could be used as input for the DJ-robot (light controls for example). (Choi & Cho, 2019) | |||
<br/> | |||
This paper is meant for beginners in the field of deep learning for MIR (Music Information Retrieval). This is a very useful technique in our project to let the robot gain musical knowledge and insight in order to play an enjoyable set of music. (Choi, Fazekas, Cho & Sandler, 2017) | |||
<br/> | |||
This article describes different ways on how to automatically detect a pattern in music with which it can be decided what genre the music is of. By finding the genre of the music that is played, it becomes easier to know whether the music will fit the previously played music.(De Léon & Inesta, 2007) | |||
<br/> | |||
This describes "Glimmer", an audience interaction tool consisting of light sticks which influence live performers. (Freeman, 2005) | |||
<br/> | |||
Describes the creation of a data set to be used by artificial intelligence systems in an effort to learn instrument recognition. (Humphrey, Durand & McFee, 2018) | |||
<br/> | |||
This describes the methods to learn features of music by using deep belief networks. It uses the extraction of low level acoustic features for music information retrieval (MIR). It can then find out e.g. of what genre the the musical piece was. The goal of the article is to find a system that can do this automatically. (Hamel & Eck, 2010) | |||
<br/> | |||
This article communicates the results of a survey among musicians and attenders of musical concerts. The questions were about audience interaction. <i>"... most spectators tend to agree more on influencing elements of sound (e.g. volume) or dramaturgy (e.g. song selection) in a live concert. Most musicians tend to agree on letting the audience participate in (e.g. lights) or dramaturgy as well, but strongly disagree on an influence of sound."</i> (Hödl, Fitzpatrick, Kayali & Holland, 2017) | |||
<br/> | |||
This article explains the workings of the musical robot Shimon. Shimon is a robot that plays the marimba and chooses what to play based on an analysis of musical input (beat, pitch, etc.). The creating of pieces is not necessarily relevant for our problem, however choosing the next piece of music is of importance. Also, Shimon has a social-interactive component, by which it can play together with humans. (Hoffman & Weinberg, 2010) | |||
<br/> | |||
This article introduces Humdrum, which is software with a variety of applications in music. One can also look at humdrum.org. Humdrum is a set of command-line tools that facilitates musical analysis. It is used often in for example Pyhton or Cpp scripts to generate interesting programs with applications in music. Therefore, this program might be of interest to our project. (Huron, 2002) | |||
<br/> | |||
This article focuses on next-track recommendation. While most systems base this recommendation only on the previously listened songs, this paper takes a multi-dimensional (for example long-term user preferences) approach in order to make a better recommendation for the next track to be played. (Jannach, Kamehkhosh & Lerche, 2017) | |||
<br/> | |||
In this interview with a developer of the robot DJ system POTPAL, some interesting possibilities for a robot system are mentioned. For example, the use of existing top 40 lists, 'beat matching' and 'key matching' techniques, monitoring of the crowd to improve the music choice and to influence people's beverage consumption and more. Also, a humanoid robot is mentioned which would simulate a human DJ. (Johnson, n.a.) | |||
<br/> | |||
In this paper a music scene analysis system is developed that can recognize rhythm, chords and source-separated musical notes from incoming music using a Bayesian probability network. Even though 1995 is not particularly state-of-the-art, these kinds of technology could be used in our robot to work with music. (Kashino, Nakadai, Kinoshita, & Tanaka, 1995) | |||
<br/> | |||
This paper discusses audience interaction by use of hand-held technological devices. (McAllister, Alcorn, Strain & 2004) | |||
<br/> | |||
This article discusses the method by which Spotify generates popular personalized playlists. The method consists of comparing your playlists with other people's playlists as well as creating a 'personal taste profile'. These kinds of things can be used by our robot DJ by, for example, creating a playlist based on what kind of music people listen to the most collectively. It would be interesting to see if connecting peoples Spotify account to the DJ would increase performance. (Pasick, 2015) | |||
<br/> | |||
This paper takes a mathematical approach in recommending new songs to a person, based on similarity with the previously listened and rated songs. These kinds of algorithms are very common in music systems like Spotify and of utter use in a DJ-robot. The DJ-robot has to know which songs fit its current set and it therefore needs these algorithms for track selection. (Pérez-Marcos & Batista, 2017) | |||
<br/> | |||
This paper describes the difficulty of matching two musical pieces because of the complexity of rhythm patterns. Then a procedure is determined for minimizing the error in the matching of the rhythm. This article is not very recent, but it is very relevant to our problem. (Shmulevich, & Povel, 1998) | |||
<br/> | |||
In this article, the author states that the main melody in a piece of music is a significant feature for music style analysis. It proposes an algorithm that can be used to extract the melody from a piece and the post-processing that is needed to extract the music style. (Wen, Chen, Xu, Zhang & Wu, 2019) | |||
<br/> | |||
This research presents a robot that is able to move according to the beat of the music and is also able to predict the beats in real time. The results show that the robot can adjust its steps in time with the beat times as the tempo changes. (Yoshii, Nakadai, Torii, Hasegawa, Tsujino, Komatani, Ogata & Okuno, 2007) | |||
<br/> | |||
This paper describes Open Symphony, a web application that enables audience members to influence musical performances. They can indicate a preference for different elements of the musical composition in order to influence the performers. Users were generally satisfied and interested in this way of enjoying the musical performance and indicated a higher degree of engagement. (Zhang, Wu, & Barthet, ter perse) | |||
Latest revision as of 00:04, 7 April 2020
Di-J: The Digital DJ
Group Members
| Name | Study | Student ID |
|---|---|---|
| Mats Erdkamp | Industrial Design | 1342665 |
| Sjoerd Leemrijse | Psychology & Technology | 1009082 |
| Daan Versteeg | Electrical Engineering | 1325213 |
| Yvonne Vullers | Electrical Engineering | 1304577 |
| Teun Wittenbols | Industrial Design | 1300148 |
Introduction
Problem Statement
DJ-ing is a relatively new profession. It has only been around for less than a century but has become more and more widespread in the last few decades. This activity has for the most part been executed by human beings, since creating a nice flow from track to track requires a skilled professional. With the rise of artificial intelligence systems in recent years, however, it might be possible to delegate some tasks to a digital system.
Current technology in the music industry has become better and better at generating playlists, or 'recommended songs' as, for example, Spotify does (Pasick, 2015). If this technology is integrated with the DJ world, would a ‘robot DJ’ be possible to create? Such a robot DJ would autonomously create playlists and mix songs, based on algorithms and real-life feedback in order to entertain an audience.
This leads to the question: How to develop an autonomous system/robot DJ which enables the user to easily use it as a substitute for a human DJ? After exploring this question we will also discuss whether this robot DJ will be valued by the user so that it will actually be used.
Approach
The goal of this project is to create software that functions as a DJ and provides entertainment for an audience. In order to create this software, first, a literature study will be performed to find out about the current state of the art regarding the problem. After enough information has been collected, the goals and milestones can be determined, which will guide the group during this process. Then, the user and technical aspects of the problem will be researched. The needs of the user will be strongly taken into account when making the design choices. The technical knowledge can then be used to actually create the software. Sub-teams will work on different tasks that are essential for the product, which will later be integrated to create the working software. During the design process of the software, user-tests will be executed to validate the software is satisfying the users' needs.
Milestones
In order to complete the project and meet the objectives, milestones have been determined. These milestones include:
- A clear problem and goal have been determined
- The literature research is finished, this includes research about:
- Users (attenders of music events, DJs, club owners)
- The state of the art in the music (AI) industry
- The research on how to create the DJ-software is finished, this includes research about:
- How to predict which songs will fit in DJ set
- The Spotify API
- How to order the songs in a set to create the most excitement in a crowd
- How to build a user interface
- The DJ-software is created
- User tests are performed to validate the satisfaction of the user needs
- The wiki is finished and contains all information about the project
- A presentation (video) about the project is made
Other milestones, which probably are not attainable in the scope of 8 weeks, are
- A test is executed in which the environment the software will be used in is simulated
- A test in a larger environment is executed (bar, festival)
- A full scale robot is constructed to improve the crowd’s experience
- A light show is added in order to improve the crowd’s experience
- Research on ways to obtain feedback from a crowd is conducted
Deliverables
The deliverables for this project are:
- The DJ-software, which is able to use feed-forward and incorporate user feedback in order to create the most entertaining DJ-set
- Depending on what type of user feedback is chosen, a prototype/sensor also needs to be delivered
- The wiki-page containing all information on the project
- The final presentation in week 8
Users
The identification of the primary and secondary users and their needs is based on extensive literature research on the interaction between the DJ and the audience in a party setting. The reader is referred to the references section for the full articles. This section is written based on (Gates, Subramanian & Gutwin, 2006), (Gates & Subramanian, 2006) and (Berkers & Michael, 2017).
Primary users
- Dance industry: this is the overarching organization that will possess most of the robots.
- Organizer of a music event: this is the user that will rent or buy the robot to play at their event.
- Owner of a discotheque or club: the robot can be an artificial alternative for hiring a DJ every night.
Primary user needs
- The DJ-robot is more valued than a human performer.
- The DJ-robot system provides something extraordinary and special.
- The system is better than a human DJ in gathering information regarding audience appreciation.
- The system's user interface is easy to understand, no experts needed.
Secondary users
- Attenders of a music event: these people enjoy the music and lighting show that the robot makes.
- Human DJ's: likely to "cooperate" with a DJ-robot to make their show more attractive.
Secondary user needs
- The music set played is structured and progressive.
- Track selection should fit the audience background.
- The system selects appropriate tracks regarding genre.
- The musical presentation should reflect the audience energy level.
- There is a balance between playing familiar tracks and providing rare, new music.
- The system selects popular tracks that are valued by the audience.
- Similar tracks to what the audience is into are played.
- The dancers are taken on a cohesive and dynamical music journey.
- Track selection should fit the audience background.
- The audience desires control over the music being played, to a certain extent.
- The audience wants to hear their favourite music.
- The audience doesn't want a predictable set of music.
- The DJ-robot takes the audience reaction into account in track selection.
The Effenaar
Since 1971 The Effenaar has developed into one of the biggest music venues of the Netherlands. Having one main hall made for 1300 people and a second hall with a capacity of 400 people. Besides their music halls and restaurant, a part of their group is working on their so called Effenaar Smart Venue. Their goal is to improve the music experience of their guests, and the artists, during their shows. In order to do this, the Smart Venue focuses on existing parts of technology. They ask themselves: what is available? And, what fits in certain shows?
For example, at a concert of Ruben Hein, they had 12 people wearing sensors measuring brainwaves, heartrates and sweat intensity on their fingertips. As seen in this video. Afterwards, they were able to see which music tracks triggered their enthusiasm and which tracks didn’t. The difference between our project and theirs is that we want to have the user feedback at the same time of the music playback. However, retrieving information this way could still be valuable. It can be measured on real people how their body reacts to certain music tracks.
Besides only focusing on music, they had several other projects. During one show they had 4 control panels set up in the hall. With these panels the guests could change the visuals of the show. Moreover, they had a project where they would make a 3D scan of guests to be used by the artist as visuals or holograms. In another experiment, they introduced an app which would raise the awareness of the importance of wearing earplugs. They used team spirit as a tool to drive this behavior, since they see sense of community as a strong value. They had a project running on feedforward based on a user database, but this was shut down due to it not being financially profitable.
The Effenaar can still benefit from an improvement of their crowd control. For example, their main hall has a bar right next to the entrance, which sometimes causes blockades. Here, technology could play a role. The crowd could be directed by the use of lighting or what songs are being played.
Our robot could help the Effenaar in their needs when focusing on music being played before and after the shows. In their second hall, the lights are already automatically adapted on the music that is being played. However the music before and after shows is controlled by an employer of the Effenaar. Most of the time this results in just playing an ordinary Spotify playlist. It would be more convenient if this could be automated and have a music set which fits to the show. They don’t see much potential in replacing the artist of a show by a robot DJ. It would rather result in a collaboration between a DJ and the technology. As said, they emphasize on the social aspect of a night out, to create a memorable moment.
State of the Art
The dance industry is a booming business that is very receptive to technological innovation. A lot of research has already been conducted on the interaction between DJ's and the audience and also in automating certain cognitively demanding tasks of the DJ. Therefore, it is necessary to give a clear description of the current technologies available in this domain. In this section, the state of the art on the topics of interest when designing a DJ-robot is described by means of recent literature.
Defining and influencing characteristics of the music
When the system receives feedback from the audience it is necessary that it is also able to do something useful with that feedback and convert it into changes in the provided musical arrangement. The most important aspects of this arrangement are chaos, energy, tempo, danceability, and valence.
Chaos is the opposite of order. Dance tracks with order can be assumed as having a repetitive rhythmic structure, contain only a few low-pitched vocals and display a pattern in arpeggiated lines and melodies. Chaos can be created by undermining these rules. Examples are playing random notes, changing the rhythmic elements at random time-points, or increasing the number of voices present and altering their pitch. Such procedures create tension in the audience. This is necessary because without differential tension, there is no sense of progression (Feldmeier, 2003).
The factors energy and tempo are inherently linked to each other. When the tempo increases, so does the perceived energy level of the track. In general, the music's energy level can be intensified by introducing high-pitched, complex vocals and a strong occurrence of the beat. Related to that is the activity of the public. An increase in activity of the audience can signal that they are enjoying the current music, or that they desire to move on to the next energy level (Feldmeier, 2003). Because in general, people enjoy the procedure of tempo activation in which they dance to music that leads their current pace (Feldmeier & Paradiso, 2004).
Danceability relates to the extent to which it is easy to dance on the music. This is a feature, described by Spotify as "to what extent can people dance on it based on tempo, rhythm stability, beat strength, and overall regularity". Valence relates to the positivity (or negativity) of the song - so either positive or negative emotions.
Algorithms for track selection
One of the most important tasks of a DJ-robot - if not the most important - is track selection. In (Cliff, 2006) a system is described that takes as input a set of selected tracks and a qualitative tempo trajectory (QTT). A QTT is a graph of the desired tempo of the music during the set with time on the x-axis and tempo on the y-axis. Based on these two inputs the presented algorithm basically finds the sequence of tracks that fit the QTT best and makes sure that the tracks construct a cohesive set of music. The following order is taken in this process: track mapping, trajectory specification, sequencing, overlapping, time-stretching and beat-mapping, crossfading.
In this same article, genetic algorithms are used to determine the fitness of each song to a certain situation. This method presents a sketch of how to encode a multi-track specification of a song as the genes of the individuals in a genetic algorithm (Cliff, 2006).
Multiple papers describe new methods of music transcription or MIR (Music Information Retrieval) through which a system can "read" music in order to match the next song to it. (Choi & Cho, 2019) (Choi, Fazekas, Cho & Sandler, 2017) (Hamel & Eck, 2010). Also, advances have been made in the field of genre-detection, as described by De Léon & Inesta (2007), as well as instrument-detection, as described by Humphrey, Durand & McFee, 2018). Other methods are using Bayesian probability networks to analyze music based on rhythm, chords and source-separated musical notes (Kashino, Nakadi, Kinoshita & Tanaka, 1995).
Pasick (2015) describes the methods which Spotify uses to generate their "recommended songs" for users. They use their existing playlists and like songs as well as creating a 'personal taste profile' for each of its users. Atherton et al. (2008) describe an alternative way in which users actively rate each song that is recommended to them by the system. That info is then used to improve the recommendations.
The article of Jannach, Kamehkhosh & Lerche (2017) focuses on next-track recommendation. While most systems base this recommendation only on the previously listened songs, this paper takes a multi-dimensional (for example long-term user preferences) approach in order to make a better recommendation for the next track to be played.
Other papers about track selection are (Yoshii, Nakadai, Torii, Hasegawa, Tsujino, Komatani, Ogata & Okuno, 2007) (Wen, Chen, Xu, Zhang & Wu, 2019)(Shmulevich, & Povel, 1998) (Pérez-Marcos & Batista, 2017)
Receiving feedback from the audience via technology
Audiences of people attending musical events generally like the idea of being able to influence performance (Hödl et al., 2017). What is important is the way of interaction with the performers, what works well and what do users prefer?
There are of course many natural ways of interacting such as clapping, cheering and dancing. These elements can be measured to a certain extent with, for example, a cheering meter which was used by Barkhuus & Jorgensen (2008)
In the article of Hödl et al. (2017), multiple ways of interacting are described, namely, mobile devices, as can be seen in the article of McAllister et al. (2004), smartphones and other sensory mechanisms, such as the light sticks discussed in the paper of Freeman (2005).
The system presented by Cliff (Cliff, 2006) already proposes some technologies that enable the crowd to give feedback to a DJ-robot. They discuss under-floor pressure sensors that can sense how the audience is divided over the party area. They also discuss video surveillance that can read the crowd's activity and valence towards the music. Based on this information the system determines whether the assemblage of the music should be changed or not. In principle, the system tries to stick with the provided QTT, however, it reacts dynamically on the crowd's feedback and may deviate from the QTT if that is what the public wants.
Another option for crowd feedback discussed by Cliff is a portable technology, more in the spirit of a wristband. One option is a wristband that is more quantitative in nature and transmits location, dancing movements, body temperature, perspiration rates and heart rate to the system. Another option is a much simpler and therefore cheaper solution. A simple wristband with two buttons on it; one "positive" button and one "negative" button. In that sense, the public lets the system know whether they like the current music or not, and the system can react upon it.
Hoffman & Weinberg (2010) describe a robot Shimon which plays the marimba. It can be influenced by other musicians as it used inputs like pitch, rhythm. POTPAL is another robot-DJ that uses top 40 lists, 'beat matching' and 'key matching' techniques and even monitoring of the crowd to improve music choices. (Johnson, n.a.)
Open Symphony is a web application that enables audience members to influence musical performances. They can indicate a preference for different elements of the musical composition in order to influence the performers. Users were generally satisfied and interested in this way of enjoying the musical performance and indicated a higher degree of engagement (Zhang, Wu & Barthet, te perse).
A first model
Based on the state of the art and the user needs a first model of our automated DJ system is made. We chose to depict it in a block diagram with separate blocks for the feedforward, the feedback and the algorithm itself.

Feedforward
The feedforward part of our system is completely based on the user input. The user has a lot of knowledge about the desired DJ set to be played beforehand. This information is fed to the system to control it. Because this feedforward block is based on user input, it has to answer to the user needs. Below, a scheme is presented to show how the user needs relate to the feedforward parameters.

The first part of the feedforward is the desired QTT of the set. What a QTT is, is described in the state of the art section. The ability for the user to input a QTT answers to the primary user need of an easy user interface. Providing a QTT to the system also makes it easy for the system to play a structured and progressive set of music, which is a secondary user need. This is in line with the secondary user need that dancers are taken on a cohesive and dynamical music journey. This structure in the music will also keep the audience engaged.
To fulfill the desired QTT certain tracks are delivered to the system to pick from as feedforward. These tracks are delivered via an enormous database with all kinds of music in it, such that the system has enough options to pick from in order to form the best set. In that sense, the system can pick from the audience favourite tracks that are popular and valued by the audience, which are some of our secondary user needs. Since people come to certain music events with certain expectations, the tracks to pick from should be appropriate regarding genre. That way, the audience background is taken into account and it keeps them engaged. This is also an opportunity to limit the algorithm's options for track selection, making the system more stable. Because the database the system can choose from is very large and diverse, the user need of wanting to hear rare, new music is answered. Also, this contributes to an unpredictable set of music that is not boring.
The most important Spotify features that we will use in our technology are "tempo", "danceability", "energy" and "valence". Tempo is just the BPM of the song as defined by existing DSP algorithms. It is a floating point number that has no limit. Spotify describes danceability as "to what extent can people dance on it based on tempo, rhythm stability, beat strength, and overall regularity." This is a floating point number with a range from 0 (not danceable) to 1 (very danceable). Energy is described by Spotify as the "perceptual measure of intensity and activity based on dynamic range, perceived loudness, timbre, onset rate, and general entropy." It is a floating point number with a range from 0 (no energy) to 1 (high energy). Valence represents the degree of positiveness of a song. It is a floating point number that ranges from 0 (very negative) to 1 (very positive).
Furthermore, the system also includes the ability to filter by "song popularity" and "artist popularity". These parameters are a part of Spotify's database, and they both describe the current popularity of a song and artist respectively. Since these parameters change over time they are not included in the regression model. They are included in the filtering system however, to allow for users to decide how obscure they want their generated music to be
In order to satisfy the audience we have to feedforward background information of the audience members to the system. In that way the system has knowledge about what the current audience is into. What someone is into could include their preferences regarding audience features based on their Spotify profile and their favourite or most hated tracks. This answers to the primary user needs of making the system something extraordinary and more valued than a human DJ because a human DJ can never know this information of every audience member. This also makes that the system is better than a human DJ at gathering information regarding audience appreciation, which is also a primary user need. It also answers to the secondary user needs of keeping balance between familiar and new music (because the system knows which tracks are familiar) and audience members wanting to express themselves - be it by providing information to a computer. It also values the DJ's desire to play similar tracks to what the audience is into and the desire to create a collective experience by means of a music set. This collective is generated because every audience member contributes a part to the feedforward of the system.
Feedback
The feedback of the system consists of sensor output. This is the part where the audience takes more control. The feedback sensor system detects how many people are present on the dance floor, relative to the rest of the event area. This can be done by means of pressure sensors in the floor. This information cues whether the current music is appreciated or not. Another cue for appreciation of the music can be generated via active feedback of the crowd. For example, valence can be assessed by the public by means of technologies described in the state of the art section. Because audience feedback is not commonly used at music events, the primary user need of providing something special and extraordinary is answered. The ability for the crowd to give feedback answers the primary user need that the system should be better at gathering information regarding audience appreciation than a human DJ. This ability also lets the public as a whole have influence on the music, which creates a collective experience. Additionally, it answers the secondary user need of having control over the music being played. In that sense, the track selection procedure takes the audience reaction into account such that it comes up with tracks that are valued by the audience members. This also lets the public control whether the music is predictable or not, which should keep them engaged.
The other part of sensory feedback is the audience energy level. This energy level may include the activity or movement of the audience members. This can be measured passively by means of a wristband with different options for sensing activity or energy by means of heart rate, accelerometer data, sweat response or other options described in the state of the art section and in the conversation with the Effenaar. The incorporation of audience energy level feedback answers to the primary user need of gathering information about the audience appreciation in a better way than a human DJ can. It also answers to the secondary user need of making the musical presentation reflect the audience energy level.
Below, a scheme is presented with all the user needs that call for feedback sensors.

The algorithm
Based on the feedforward and feedback of the crowd, the tracks to be played and their sequence are selected as described here.
The next step in the algorithm is overlapping the tracks in the right way. Properly working algorithms that handle this task already exist. For example, the algorithm described in (Cliff, 2006). We will describe the working principles of that algorithm in this section. The overlap section is meant to seamlessly go from one track to the other. In the described technology the time set for overlap is proportional to the specified duration of the set and the number of tracks, making it a static time interval. Alterations to the duration of this interval are made when the tempo maps of the overlapping tracks produce a beat breakdown or when the overlap interval leads to an exceedance of the set duration.
If the system wants to play a next track in a smooth transition but there is a difference between the tempo (BPM) of the current track and the next track, time-stretching and beat-mapping need to be applied. Time-stretching will slow down or bring up the tempo such that the tempo of the current and next track are nearly identical in order to produce a smooth transition to the next track. Technically speaking time-stretching is a (de)compression of time or changing the playback speed of the samples and applying proper interpolation in order to maintain sound quality. Once the tempos match, the beats of the two songs need to be aligned in order to acquire zero phase difference to avoid beat breakdown.
The last step is proper cross-fading. Although ramping down the volume of the current track while ramping up the volume of the next track is often sufficient for a good cross-fade, the algorithm described uses more sophisticated techniques to achieve proper cross-fading. The algorithm analyses the audio frequency-time spectograms of the two tracks to be cross-faded. This can be used to selectively suppress certain frequency components in the tracks such that current melodies seem to disappear and the next melody becomes more prominent. It can also filter out components of tracks that clash with each other, allowing for a smooth cross-fade (Cliff, 2006).
The final product: Di-J
System overview
Below a graphic overview of the system is given. Important to note is that the grey area is the scope of our project; to design the rest is not feasible within our time budget. Besides, a lot of research is already done on the modules outside the grey region. Mixing tracks together seamlessly is a desirable skill for all DJs and therefore a skill for which a lot of DJs seek help in the form of technology. Due to this high demand, a lot of properly working mixing algorithms already exist, for example (Cliff, 2006). Certain feedback sensors that measure the excitement of the audience also already exist. A lot of wearable devices that measure all sorts of things like heart rate or motion already exist and have been used. One can look at one of the prior sections to gain information on this. Another real-life example is the Effenaar that has used technology to measure brain activity and excitement among attendees of a music event. This lets us make the assumption that the mixing and the feedback part will work.
Globally, the system works as follows. The system has a large database to pick music from. This database contains for every song an "excitement" value that is based on a multiple regression output of the Spotify audio features "valence" and "energy". The database is freely available to the user. The music of this database is let through the pre-filter. The pre-filter filters the songs in the database on genre and Spotify features "tempo", "danceability", "energy", "valence", "song popularity" and "artist popularity". This input is made possible by the user interface. In that sense, the pre-filter puts out an array of tracks that is already filtered according to the user's desire. Next, the filtered tracks will be matched according to the desired QET (we will use an excitement graph instead of a tempo graph but the principle is the same). The result of this matching is a sequence of tracks that creates the playlist to be played for that evening (or morning?). This playlist is also freely available to the user. The playlist is then fed to the mixing algorithm to make sure that the system outputs a nicely mixed set of music to enjoy. This music is rated on excitement by means of feedback sensors. This feedback is used to update the playlist via the excitement matching module. Thus, if the audience is not happy with the currently playing music the system can act upon that.

User interface
User Interface of Web-Application
When the user browses to the webpage, he/she first encounters a window where they can input their Spotify account. This way, the generated playlist is automatically added to the user's Spotify account. When the Spotify account has been entered, the user lands on the main page. On this page, the user can enter all the different settings he/she wants. He/she can make adjustments to the Filters, where a specific range of values can be selected for multiple variables. The user can then choose the trajectory for the excitement over time in the Excitement Graph section. There are three different options: wave, in which the excitement goes up and down a few times, ramp, in which the excitement gradually builds up over time, and plateau, in which the excitement starts low, gets up to a certain level and stays there to eventually build down. Then the user can select specific genres in Genres from a list of 15 different genres. Once the user is happy with the settings he/she chose, the Generate Playlist button at the bottom of the page can be clicked and a playlist will be developed and automatically added to the user's Spotify account.
Why we chose for this particular layout and design of the Webpage can be found in the section Validation of the user needs under User test 1: The user-interface.
-
 The Spotify Page
The Spotify Page -
 The Full Page
The Full Page


-
 The Filters section with specific settings
The Filters section with specific settings -
 The Graph displaying the different excitement trajectories
The Graph displaying the different excitement trajectories


-
 The Genres section with some selected
The Genres section with some selected -
 The button you press to generate the playlist
The button you press to generate the playlist


Pre-filter
The goal of the pre-filtering is to give users the ability to discard several tracks and make sure that said tracks do not end up in their final playlist. There are two categories in the pre-filter. The 'filter' section provides the ability to set an upper and lower bound for certain parameters. the 'genre' section provides the ability to either include or exclude certain genres.
The database is then filtered according to the user's desire. The algorithm excludes all songs that do not have their parameters within the set thresholds. From this, a new, filtered, list is created, which then gets sorted in order of excitement. The song with the lowest excitement score gets stored since this will be the 'floor' on which the QET will begin. The same is done with the song that has the highest energy score since this allows the QET matching algorithm to specify the excitement value of the global maximum within the graph. It can then subsequently calculate the desired excitement level at any point in time during the set.

Excitement prediction with multiple regression
In order to come up with a useable product, we need to narrow down the scope of this project. We decided to focus on engineering a proper pre-filter and feedforward system for track selection, based on the Spotify audio features. We mainly focus on the features "energy" and "valence". Even after extensive research, no formal definition or equation was found for the Spotify feature "energy". Spotify itself describes it as a perceptual measure of intensity and activity based on dynamic range, perceived loudness, timbre, onset rate, and general entropy. It is a floating-point number with a range between 0 and 1. The same holds for the "valence" feature; no equation can be found but Spotify describes it as a representation of the positivity or negativity of a track. It is a floating-point number with a range of 0 to 1 where values close to 1 represent positive songs, whereas values close to 0 represent sad songs.
The word excitement is very much linked to a highly energized state of positive feelings. As it is given a definition by the Oxford dictionary: "the state of feeling or showing happiness and enthusiasm." That is why we chose the features "energy" and "valence" to predict this variable.
Continuing, we rated 152 songs on "excitement" and then performed a multiple regression analysis with the Spotify features "energy" and "valence" to come up with a prediction equation for "excitement" based on these features. We rated "excitement" such that it represents how enthusiastic the song is, how excited one gets by listening to it. It is a floating-point number ranging from 0 to 1. Values close to 0 represent songs that will not get people enthusiastic, whereas values close to 1 represent songs that are very exciting and fosters enthusiasm among listeners. Please note that for now the feature "excitement" is completely made up by ourselves and inherently subjective in nature. However, we deemed "excitement" as it is defined now a good parameter for track selection that makes the audience happy. We picked songs from three different genres of dance music: Techno, Hardstyle, and Disco. We wanted to stick to dance music, but to diversify our research we considered three distinct genres. The results of the regression analyses are presented in the proceeding sections.
Multiple regression per genre
The first step in our analysis was to do a multiple regression for every distinct genre in our database - being either Techno, Hardstyle or Disco - to see whether the equation for "excitement" differs between genres and whether it gives any significant results to start with.
Multiple regression techno
The multiple regression model considering techno is the only one which turned out significant, R² = 0.1, F(2, 60) = 3.39, p = 0.04. Here, "excitement" was based on the Spotify features "energy" and "valence". It means that for techno the appropriate equation for excitement is the following: ex = 0.39 + 0.183*en + 0.208*v. Where "ex" is excitement, "en" is energy and "v" is valence. The exact results are presented in the table.
| excitement | Coefficient | Standard Error | t | p |
|---|---|---|---|---|
| energy | 0.183 | 0.116 | 1.57 | 0.121 |
| valence | 0.208 | 0.096 | 2.11 | 0.039 |
| constant | 0.390 | 0.100 | 3.91 | 0.000 |
Multiple regression hardstyle
The model for hardstyle turned out non-significant, R² = 0.05, F(2, 37) = 0.91, p = 0.41. It means that with this sample of hardstyle songs and their excitement ratings, no fitting equation is found by linear regression. The exact results are presented in the table.
| excitement | Coefficient | Standard Error | t | p |
|---|---|---|---|---|
| energy | -0.171 | 0.154 | -1.11 | 0.276 |
| valence | -0.057 | 0.063 | -0.91 | 0.371 |
| constant | 0.800 | 0.142 | 5.61 | 0.000 |
Multiple regression disco
The model for disco turned out non-significant, R² = 0.1, F(2, 46) = 2.55, p = 0.09. It means that with this sample of disco songs and their excitement ratings, no fitting equation is found by linear regression. The exact results are presented in the table.
| excitement | Coefficient | Standard Error | t | p |
|---|---|---|---|---|
| energy | 0.079 | 0.109 | 0.72 | 0.474 |
| valence | -0.142 | 0.077 | -1.86 | 0.070 |
| constant | 0.693 | 0.118 | 5.86 | 0.000 |
Multiple regression across genres
In the next step, we took all genres together and performed the same multiple regression analysis on that dataset. This regression turned out significant, R² = 0.06, F(2, 149) = 4.99, p = 0.008. It means that there is a linear equation to predict "excitement" of a track based on the audio features "energy" and "valence" if you consider the three dance genres together. This equation is as follows: ex = 0.45 + 0.16*en + 0.07*v. If we generated this new predicted value from the equation, took the absolute difference between this predicted value and the "real" value for "excitement", the mean difference was 0.07 with a standard deviation of 0.06. All exact results can be found in the table below.
| excitement | Coefficient | Standard Error | t | p |
|---|---|---|---|---|
| energy | 0.160 | 0.070 | 2.28 | 0.024 |
| valence | 0.070 | 0.024 | 2.93 | 0.004 |
| constant | 0.450 | 0.063 | 7.13 | 0.000 |
Discussion of the regression results
When we took each genre separately to come up with a prediction equation for "excitement", the results were not always promising. Only the regression for techno turned out significant. We think that this was mainly due to the small sample size (only 40, 49 and 63 songs used in every list) and the inherent subjective nature of the feature "excitement". Only one person rated this feature for every song making it a very subjective, personal variable. However, we should look beyond the results of this regression analysis only. In the future when our system will be used at large music events, the variable "excitement" can be deduced in a much better way than by quantifying the subjective opinion of one person. One option could be to let every attendee of a music festival rate about 10 relevant songs before attending the event. If 10,000 people do this the system can create 100,000 data points to base the regression on, instead of 152. One can imagine that this would give much better results than the provided analysis. Besides, when considering the regression analysis across genres we already came up with a model that has an average error of only 7%. One can imagine how small the error would become if 100,000 data points are used.
Another option could be to generate the "excitement" information in a more physical sense. For example, based on information gathered from heart rate monitors and/or brain activity sensors as used by the Effenaar. This information is more quantitative in nature than people's subjective opinion on "excitement" level of a track. So, maybe this could function as input that generates a more robust equation for "excitement".
Concluding, how the information on "excitement" is gathered is a point of discussion as well as an opportunity for improvement. What is most important is that a multiple regression model might be a good way to incorporate feedforward for track selection in our system. In that sense, the value of this particular research is not in the results of these regressions but in the method behind it.
Excitement matching with QET
One module of the system is the excitement matching algorithm. What we mean by this is a system that takes in a graph (which can be a set of points) from the user with the desired course of "excitement" of the music set. This is called a Qualitative Excitement Trajectory (QET). Thus, we want a module that takes in a QET from the user and transforms it into a mathematical equation, because a graph is what humans can work with, while an equation is what computers can work with. With this mathematical equation, the module can output different values of "excitement" for every point in time in the music set and thus also outputs "excitement" values at points where a new music track should start. These latter points can then be matched with existing music tracks with an "excitement" value close to this desired value by a Spotify filter. Because we want to answer the user need of keeping the system simple and easy to use, we decided to let the user input the QET by means of "key points of excitement" in the music set. This is easier than drawing a whole graph. Thus, the user can specify at what points in time it desires certain values of excitement and the system does the rest. We created a MATLAB script to simulate such software and prove its working.
A script for QET matching algorithm
As an example, we chose as user input a 30 minutes long music set, divided in 1-minute intervals. In the example case the user inputs the following desires: start the set at an excitement of 0.7, after 5 minutes drop to 0.6 within 5 minutes, continuing climb to 0.8 within 10 minutes, then drop to 0.7 again within the next 5 minutes and finish of the set by climbing to the maximum excitement of 1.00 in the last 5 minutes. This input from the user is read from a ".txt" file. This file is transformed into data points and depicted below.

The next step is to interpolate for values between these key excitement points (in order to get a value for every minute of the set). We chose to use simple linear interpolation which gave decent results, however other sorts of interpolation are also possible and easily implemented using MATLAB. After interpolation, a polynomial fit is applied in order to come up with a mathematical equation for the QET. In this example, a 7th order polynomial was created to describe the QET. The result is depicted below.

One can see that the result is quite promising. The polynomial curve follows the desired QET without an undesirable large error. The coefficients of the polynomial curve are also outputted by this script and can thus be used to construct a mathematical equation for the QET. This equation can then again be sampled (with a sampling period depending on the desired song length) to obtain the distinct excitement values the songs should have in time. In that way, the system can construct and output an ordering of the provided tracks based on this sampled equation for QET and the algorithm works. These tracks are depicted as the orange bars in the graph. In this example case a duration of 2 minutes is chosen for every song such that a lot of music can be played while there is time enough for every song to play its core part. The output of the system is a ".txt" file that contains the excitement ratings of the tracks in the generated set from the user input. The MATLAB script that does all these calculations is provided below.
%Input the key data points (degree of polynomial should be < data points)
QET_matrix = readmatrix('sample_input.txt'); %First row is time, Second row is excitement
x_keydata = QET_matrix(1,:); %The time points from the user input file
y_keydata = QET_matrix(2,:); %The corresponding excitement ratings
p_keydata = polyfit(x_keydata,y_keydata,3); %Get polynomial coefficients for the key data points
f_keydata = polyval(p_keydata,x_keydata); %Generate a fucntion from coefficients
figure;
plot(x_keydata,y_keydata,'o',x_keydata,f_keydata,'-'); %Not a desirable outcome -> use interpolation
title("Input of key data points and polynomial fit");
xlabel("Time [m]");
ylabel("Excitement rating [0,1]");
%Interpolation for the key data points
samples = max(x_keydata); %#samples to interpolate
x_interpolation = 1:samples;
for i = 1:samples
y_interpolation(i) = interp1(x_keydata,y_keydata,i); %Linear interpolation between input points
end
%Get a formula for the graph
n = 7; %Degree of the polynomial
p_polynomial = polyfit(x_interpolation,y_interpolation,n); %Get polynomial coefficients for the interpolated data
f_polynomial = polyval(p_polynomial,x_interpolation); %Make a function from these coefficients
%Create discrete bars (the songs)
songlength = 2; %In minutes
for i = 1:songlength:length(f_polynomial)
track_histogram(i) = f_polynomial(i); %Generate the discrete tracks
end
figure;
hold on;
plot(x_interpolation,y_interpolation,'o',x_interpolation,f_polynomial,'-'); %Plot graphs
alpha(bar(track_histogram,songlength),0.1); %Plot bars
ylim([0.6 1.05]);
title("Interpolation result and polynomial fit");
xlabel("Time [m]");
ylabel("Excitement rating [0,1]");
legend("Interpolated values", "Polynomial curve", "Tracks on the set");
%Output the formula coefficients
fprintf("Fitted formula coefficients (a1*x^n + a2*x^(n-1) + ...): \n");
for i = 1:n+1
fprintf("%d \n",p_polynomial(i)); %Prints the coefficients
end
%Output the tracks' excitement rating to a text-file
fileID = fopen('sample_output.txt','w');
fprintf(fileID,"%1.3f\r\n",track_histogram);
fclose(fileID);
A GUI for QET matching
Given the time budget, it was unfeasible to integrate the QET matching algorithm in the Java-based website. Therefore, we decided to let it function as a standalone application that comes as an extra to our system. Because the algorithm is of value to the project as a whole we worked further on it and created an executable GUI for it. The working principles are exactly the same as described in the prior sections, but now it is easier for the user to put in his or her desired QET via a visual tool. A screenshot of the tool is provided below.

If the user follows through the numbered steps it can totally control the desired QET of his or her music set. In the first step, the user defines the duration of the music set in minutes. In the next step, the user defines the number of time points he or she wants to control - the depth of control so to speak. In the third step, the user makes use of a slider to set the desired excitement values of all the time points. If the user makes any mistakes in this, it is possible to go back to previous points. In the last step, the user defines the length that he or she wants to hear all songs and then presses "Generate matching values". When this button is pushed the user gets to see the graph with the interpolation result, polynomial fit and bar graph of the tracks - as described and displayed in the prior section. Also, this bar graph of the tracks and their excitement values is transformed into data (an array) and outputted to a ".txt" file so the rest of the system could work with it.
By providing the user with a visual tool for deciding on a QET, the system answers to the primary user need of an easy to understand user interface for which no experts are needed to operate it. Besides, it answers to the secondary user needs of a structured and progressive music set and that dancers are taken on a cohesive and dynamic music journey.
Validation of the user needs
In order to make sure the product satisfies the user needs, the product needs to be validated. For each user need a method of validation is presented. However, due to limited time and/or resources, not all user needs were able to be verified. The primary user need "The system's user interface is easy to understand, no experts needed" and the secondary user need "Track selection should fit the audience background" were possible to validate. The results of these tests are also discussed in this section
User test 1: The user-interface
In order to validate the satisfaction of the user need: "The system's user interface is easy to understand, no experts needed.", a user test has been executed. This user-test consisted of a survey, which asked the users question about different user-interfaces. This test has been executed with 14 people.
The test set-up
The people that were part of this user test were shown three different user-interfaces, which are displayed below:
-
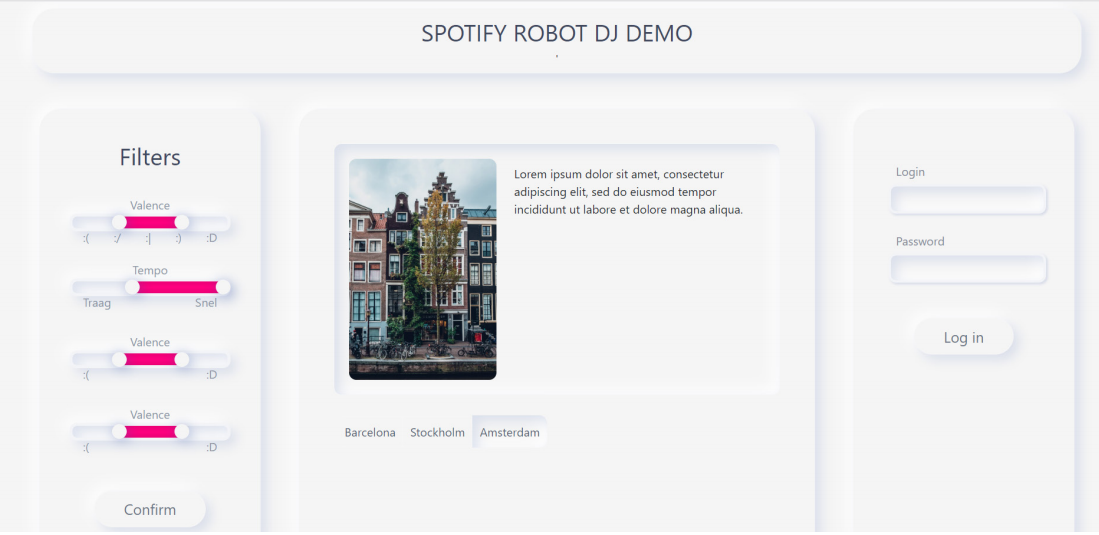 UI1
UI1 -
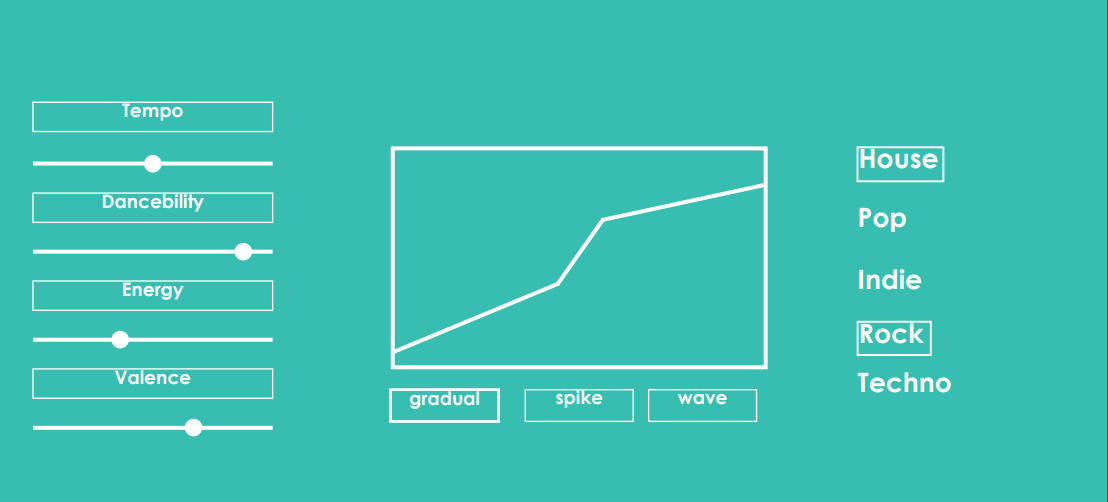 UI2
UI2


-
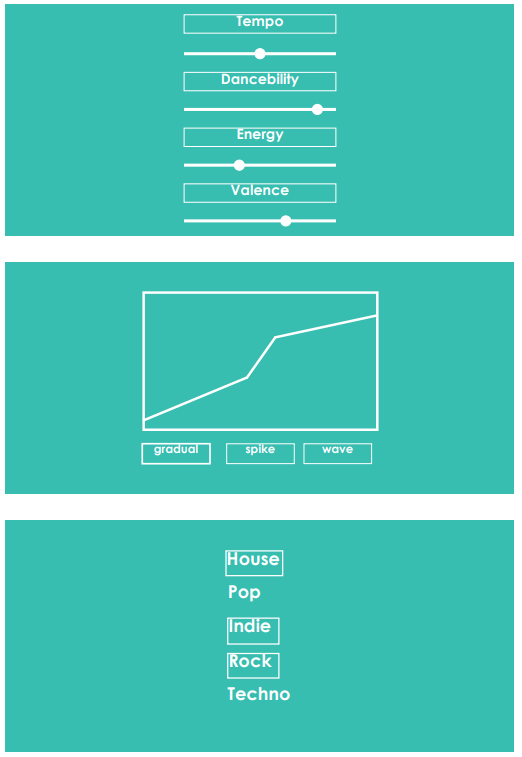 UI3
UI3

UI1 and UI2 differ in style: UI1 has a neumorphic design, where UI2 has a very simplistic and "flat" style. UI2 and UI3 are shown to demonstrate the difference in layout: UI2 has all panels on one page, where UI3 consists of three separate pages. Then, the people that were apart of this test were asked to fill in a survey about these user-interfaces. The survey that was executed consists of three questions:
- Which do you prefer: All panels on one page, or on three separate pages (UI2 or UI3)?
- Is it clear what the values on the page mean and how these can be adjusted? If not, what is unclear?
- Mention an aspect of the styling which you like for both styles (UI1 and UI2).
After all, users took the survey, the results could be analyzed
The results
Question 1: Which do you prefer: All panels on one page, or on three separate pages?
Almost all users preferred the style with all panels on one page over the style with three separate pages (94% vs 6%).

Question 2: Is it clear what the values on the page mean and how these can be adjusted? If not, what is unclear?
56% of the users found the UI to already be very clear. However, the other 44% had some small comments about the existing interface. The majority of this group (24%) did not understand the meaning of the variable 'valence'. Other comments were about not understanding the difference between tempo and energy (8%) and about the range of the values not being clear, i.e. axes missing (14%).

Question 3: Mention an aspect of the styling which you like for both styles.
For style 1, the majority of the users enjoyed the finished (44%) and professional (33%) look. A small part of the users liked this UI having a title (6%). However, some users did not enjoy this interface at all and decided not to give a strong point for the styling of this UI.

Style 2 was preferred more over style 1 since a smaller part of the users did not have a strong point for the style (6%). The majority of the users liked this style for it being easy to understand due to its simplicity (47%). Other users enjoyed the colors of this UI (31%) or that this style had a sleek design (17%).

Other comments
The users were also given an option to give some extra feedback. These comments included:
- Giving the panels a title so its purpose would be even more clear;
- Showing the definition of a parameter (e.g. valence) when hovering your mouse above this parameter would increase the clarity of the page;
- Putting range values beneath the sliders would make the interface more clear.
User test 2: The track-selection
To test the user need: "The system selects appropriate tracks regarding genre", a second user test was performed. This test was focussed on whether the "danceability", "energy" and "valence" values of the filtered music songs would match people's expectations.
The test set-up
For this test, the three different parameters were tested separately. Furthermore, the features were split up into 5 parts. Each of them consisting of a range of 0.2. Starting at 0 to 0.2 and ending at 0.8 to 1.0. With these filter values 5 playlists were created for every feature, so 15 lists in total. These playlists consisted of 50 songs. This way, possible errors of a single song's feature value were eliminated. Moreover, the test persons had 50 songs to base their judgment on. Genres were not taken into account when filtering the songs, this would result in a more diverse set of songs. For the sake of convenience, the most popular songs were used. Users would then easier recognize the songs.

The test was split into two parts. To test how clearly the differences are, the first part consisted of comparing the two extreme regions and the middle one. List A, C, and E according to the figure. Then it was tested whether the differences would still be recognizable coming closer to the 0.5 values. Therefore lists B and D were compared. Obviously the test persons did not know the correct order. They were asked to sort the given playlists from most to least danceable, energetic or valent. So, first, they compared A, C, and E with each other, followed by the comparison of B and D. This means that there were six tests in total.
The results
Test 1
These percentages are based on each separate playlist a participant has chosen correctly. This means that if someone has chosen only one of the three lists correct. There answer would not be completely wrong, but there answer would be 33.3% right. These results can be seen in the following table.
| Danceability | Energy | Valence | |
|---|---|---|---|
| Correct answers | 89.6% | 89.6% | 93.8% |
Test 2
For the second test, there were only 2 playlist to order, so the answer was either right or wrong. This test resulted in the following outcome.
| Danceability | Energy | Valence | |
|---|---|---|---|
| Correct answers | 93.8% | 87.5% | 93.8% |
Looking at these results it can be concluded that people’s perception of danceable, energetic and valent music fairly corresponds to the numeric values Spotify has assigned to these songs. However it must be noted that some people said that it was a difficult task due to the diversity in style of the 50 songs in one playlist.
Conclusion
For the conclusion of this project, we want to mention multiple things. We want to share our insights in the area of the State of the Art, our practical solutions and systems, and also the insights gained about our users.
State of the Art
In the State of the Art section we discussed a few things. We described defining and influencing characteristics of the music, where we explained audio features like energy, tempo, danceability, and valance and where they come from. (Feldmeier, 2003)(Feldmeier & Paradiso, 2004)Spotify
We also discussed multiple algorithms for track selection. There we introduced the Qualitative Tempo Trajectory (QTT)(Cliff, 2006), Music Information Retrieval (Choi & Cho, 2019) (Choi, Fazekas, Cho & Sandler, 2017) (Hamel & Eck, 2010), and genre-, instrument-, chord- and rhythm-detection methods De Léon & Inesta (2007) Humphrey, Durand & McFee, 2018) (Kashino, Nakadi, Kinoshita & Tanaka, 1995). Pasick (2015) described the methods which Spotify uses to generate their "recommended songs" for users. Many other sources were quoted about track-seletion or -recommendation.
We then described multiple ways of receiving feedback from the audience via technology. What was important to know is that audiences of people attending musical events generally like the idea of being able to influence performance (Hödl et al., 2017). We then mentioned many different ways of audience feedback. One that suited our project well was a wristband that is more quantitative in nature and transmits location, dancing movements, body temperature, perspiration rates and heart rate to the system(Cliff, 2006).
Systems and Solutions
We used many different methods in our final system. We used inputs such as genre-selection, specific ranges for filters such as tempo, danceability, and popularity, as well as a trajectory of the excitement over the time of a specific set. We used the audio features of Spotify and integrated it with our selfmade QET, consisting of a multiple regression model taking energy and valence. There is promise to the usage of these parameters for the creation of a playlist. The system needs to become a little smarter to be able to fully take advantage of them. Adding artificial intelligence into the mix might allow us to see patterns in the data that we ourselves could not find.
Users
We, of course, took the needs of the users into account very much. As mentioned before, audiences of people attending musical events generally like the idea of being able to influence performance (Hödl et al., 2017). We defined the user needs in Users. From our conversation with the Effenaar we gathered that there was a market for an automated robot DJ, not to replace the main act, but to replace the playlists or DJs before and after the main act.
Our validation shows that users do have a pretty good sense of music. They can quite well differentiate between a track with little and high danceability for example. This is important for our product, since user's choices ought to be made based on these parameters.
Conclusion
All in all, the system shows promise, but needs some refinements to actually be marketable. Casual users might desire easier controls, while music venues might want finer control. The current system should serve as a proof of concept for a more elaborate system. One that is hopefully based on more actual parties, since we could not test for those scenarios due to the circumstances.
Discussion
The main discussion point of this project would be the lack of in the field testing. While, partially due to the Corona circumstances, it would have been nice to try and be more creative with solutions to overcome this problem. The next steps would definitely include doing these tests, to validify the usefulness of the system in a real-life scenario. Although the User Interface was validated by people, it could have helped to include some professional or amateur DJs in these tests. We have had contact with an amateur DJ who liked our project and concept, but we have not done a formal user test or validation with him. For many decisions, we based our choice on the information of Spotify or other sources, who have done user tests and have a good understanding of the general taste. This validates our project to a certain extent, but it is always better to rely on own results.
The project, overall, went well. We had a meeting every week where we discussed our findings and updated each other on our progress. We had a clear division of labour during this project, so everyone knew what his/her responsibilities were. However, not every member of the group contributed the same amount of work. This could have had multiple reasons. One is that not everyone was as knowledgable in the area of coding, of which there was a lot. The other reason could be that we did not properly consider how to divide the tasks in a way that everyone could contribute the same.
At first, we had very big ambitions. We wanted to create a fully autonomous Robot DJ, possibly with accompanying light show and physical robot. During the project, with the help of our coaches, we were able to specify the area which we wanted to focus on. This way we were able to create something working, complete, and well designed because we could really focus on this one system instead of a large system with many different aspects.
Future Works
There are multiple topics that need refinement if the product were to actually come to market. The following paragraphs summarize some of the point of improvement.
Better handle input
The user input currently gets literally and linearly translated to the filter. It would be benificial to the system if this part became smarter. It currently is quite easy to set the sliders in a way where no songs meet the criteria. This should be improved.
Improved in this area lead to a better output, as well as a better user experience. Developments here would bridge the gap from specialized software for users wanting someting specific, to more casual users who might use the application more casually. Furthermore, the user should be able to set a certain length for the set. This was currently not realized due to time constraints, but should definitely be implemented into the actual system, since the QET diagram only makes sense with the correct timing.
Turing tests
Due to all the current social distancing measures it is not possible to test our final product in practise. However different kinds of Turing tests have been invented.
The first test would be to hire a café or disco were our DJ would take care of the music. The guest would of course not know that the DJ is not a human. But for their illusion, someone will be standing behind a DJ booth to make it look like the music is indeed arranged by a human. To measure the popularity of the café that night, different guests will be asked what they think of the music. Also the average amount of guests per hour will be counted. Because the amount of consumed alcohol would influence this rating, should the results be adjusted to what time in the evening it is. To get significant results. These test have to be performed several nights. As a control group to test the normal popularity of this café or disco, there should also be tested with a human DJ for several times.
An easier but similar test would be to conduct our test in a silent disco. Silent discos often use RGB headphones with 3 different music channels with 3 different DJs playing. The headphone will turn red, green or blue, depending on which channel it is listening to. One of these channels could be our robot DJ. Thereafter the average percentage of the guest listening to “our” channel over the night could be measured. Doing this several nights would reduce the chance of the human DJs having a bad day and it could be calculated whether people rather listen to “our” music set or that of some other human DJ.
Who's Doing What?
Personal Goals
The following section describes the main roles of the teammates within the design process. Each team member has chosen an objective that fits their personal development goals.
| Name | Personal Goal |
|---|---|
| Mats Erdkamp | Play a role in the development of the artificial intelligence systems. |
| Sjoerd Leemrijse | Gain knowledge in recommender systems and pattern recognition algorithms in music. |
| Daan Versteeg | |
| Yvonne Vullers | Play a role in creating the prototype/artificial intelligence |
| Teun Wittenbols | Combine all separate parts into one good concept, with a focus on user interaction. |
Planning
Based on the approach and the milestones, goals for each week have been defined to use as a planning. This planning is not definite and will be updated regularly, however it will be a guideline for the coming weeks.
Week 2
Goal: Do literature research, define problem, make a plan, define users, start research into design and prototype
Week 3
Goal: Continue research, start on design
Week 4
Goal: Finish first design, start working on software.
Week 5
Goal: Work on software
Week 6
Goal: Finish software , do testing
Week 7
Goal: Finish up the last bits of the software
Week 8
Goal: Finish wiki, presentation

Weekly Log
The weekly log can be found here: Weekly Log PRE2019 3 Group15.
References
Atherton, W. E., Becker, D. O., McLean, J. G., Merkin, A. E., & Rhoades, D. B. (2008). U.S. Patent Application No. 11/466,176.
Barkhuus, L., & Jørgensen, T. (2008). Engaging the crowd: studies of audience-performer interaction. In CHI'08 extended abstracts on Human factors in computing systems (pp. 2925-2930).
Berkers, P., & Michael, J. (2017). Just what makes today’s music festivals so appealing?.
Choi, K., Cho, K. “Deep Unsupervised Drum Transcription”, 20th International Society for Music Information Retrieval Conference, Delft, The Netherlands, 2019.
Choi, K., Fazekas, G., Cho, K., & Sandler, M. (2017). A tutorial on deep learning for music information retrieval. arXiv preprint arXiv:1709.04396.
Cliff, D. (2006). hpDJ: An automated DJ with floorshow feedback. In Consuming Music Together (pp. 241-264). Springer, Dordrecht.
De León, P. J. P., & Inesta, J. M. (2007). Pattern recognition approach for music style identification using shallow statistical descriptors. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 37(2), 248-257.
Feldmeier, M. C. (2003). Large group musical interaction using disposable wireless motion sensors (Doctoral dissertation, Massachusetts Institute of Technology).
Feldmeier, M., & Paradiso, J. A. (2004, April). Giveaway wireless sensors for large-group interaction. In CHI'04 Extended Abstracts on Human Factors in Computing Systems (pp. 1291-1292).
Freeman, J. (2005) Large Audience Participation, Technology, and Orchestral Performance in Proceedings of the International Computer Music Conference, 2005, pp. 757–760.
Gates, C., & Subramanian, S. (2006). A Lens on Technology’s Potential Roles for Facilitating Interactivity and Awareness in Nightclub. University of Saskatchewan: Saskatoon, Canada.
Gates, C., Subramanian, S., & Gutwin, C. (2006, June). DJs' perspectives on interaction and awareness in nightclubs. In Proceedings of the 6th conference on Designing Interactive systems (pp. 70-79).
Greasley, A. E. (2017). Commentary on: Solberg and Jensenius (2016) Investigation of intersubjectively embodied experience in a controlled electronic dance music setting. Empirical Musicology Review, 11(3-4), 319-323.
Humphrey, E.J., Durand, S., McFee, B. “OpenMIC-2018: An open dataset for multiple instrument recognition”, 19th International Society for Music Information Retrieval Conference, Paris, France, 2018.
Hamel, P., & Eck, D. (2010, August). Learning features from music audio with deep belief networks. In ISMIR (Vol. 10, pp. 339-344).
Hödl, Oliver; Fitzpatrick, Geraldine; Kayali, Fares and Holland, Simon (2017). Design Implications for TechnologyMediated Audience Participation in Live Music. In: Proceedings of the 14th Sound and Music Computing Conference,
July 5-8 2017, Aalto University, Espoo, Finland pp. 28–34.
Hoffman, G., & Weinberg, G. (2010). Interactive Jamming with Shimon: A Social Robotic Musician. Proceedings of the 28th of the International Conference Extended Abstracts on Human Factors in Computing Systems, 3097–3102.
Huron, D. (2002). Music information processing using the Humdrum toolkit: Concepts, examples, and lessons. Computer Music Journal, 26(2), 11-26.
Jannach, D., Kamehkhosh, I., & Lerche, L. (2017, April). Leveraging multi-dimensional user models for personalized next-track music recommendation. In Proceedings of the Symposium on Applied Computing (pp. 1635-1642).
Johnson, D. (n.a.) Robot DJ Used By Nightclub Replaces Resident DJs. Retrieved on 09-02-2020 from http://www.edmnightlife.com/robot-dj-used-by-nightclub-replaces-resident-djs/
Kashino, K., Nakadai, K., Kinoshita, T., & Tanaka, H. (1995). Application of Bayesian probability network to music scene analysis. Computational auditory scene analysis, 1(998), 1-15.
McAllister, G., Alcorn, M., Strain, P. (2004) Interactive Performance with Wireless PDAs Proceedings of the International Computer Music Conference, 2004, pp. 1–4.
Pasick, A. (21 December 2015) The magic that makes Spotify's Discover Weekly playlists so damn good. Retrieved on 09-02-2020 from https://qz.com/571007/the-magic-that-makes-spotifys-discover-weekly-playlists-so-damn-good/
Pérez-Marcos, J., & Batista, V. L. (2017, June). Recommender system based on collaborative filtering for spotify’s users.In International Conference on Practical Applications of Agents and Multi-Agent Systems (pp. 214-220). Springer, Cham.
Shmulevich, I., & Povel, D. J. (1998, December). Rhythm complexity measures for music pattern recognition. In 1998 IEEE Second Workshop on Multimedia Signal Processing (Cat. No. 98EX175) (pp. 167-172). IEEE.
Wen, R., Chen, K., Xu, K., Zhang, Y., & Wu, J. (2019, July). Music Main Melody Extraction by An Interval Pattern Recognition Algorithm. In 2019 Chinese Control Conference (CCC) (pp. 7728-7733). IEEE.
Yoshii, K., Nakadai, K., Torii, T., Hasegawa, Y., Tsujino, H., Komatani, K., Ogata, T. & Okuno, H. G. (2007, October). A biped robot that keeps steps in time with musical beats while listening to music with its own ears. In 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems (pp. 1743-1750). IEEE.
Zhang, L., Wu, Y., & Barthet, M. (ter perse). A Web Application for Audience Participation in Live Music Performance: The Open Symphony Use Case. NIME. Retrieved from https://core.ac.uk/reader/77040676
Summary of Related Research
This patent describes a system, something like a personal computer or an MP3 player, which incorporates user feedback in it's music selection. The player has access to a database and based on user preferences it chooses music to play. When playing, the user can rate the music. This rating is taken into account when choosing the next song. (Atherton, Becker, McLean, Merkin & Rhoades, 2008)
This article describes how rap-battles incorporate user feedback. By using a cheering meter, the magnitude of enjoyment of the audience can be determined. This cheering meter was made by using Java's Sound API. (Barkhuus & Jorgensen, 2008)
Describes a system that transcribes drums in a song. Could be used as input for the DJ-robot (light controls for example). (Choi & Cho, 2019)
This paper is meant for beginners in the field of deep learning for MIR (Music Information Retrieval). This is a very useful technique in our project to let the robot gain musical knowledge and insight in order to play an enjoyable set of music. (Choi, Fazekas, Cho & Sandler, 2017)
This article describes different ways on how to automatically detect a pattern in music with which it can be decided what genre the music is of. By finding the genre of the music that is played, it becomes easier to know whether the music will fit the previously played music.(De Léon & Inesta, 2007)
This describes "Glimmer", an audience interaction tool consisting of light sticks which influence live performers. (Freeman, 2005)
Describes the creation of a data set to be used by artificial intelligence systems in an effort to learn instrument recognition. (Humphrey, Durand & McFee, 2018)
This describes the methods to learn features of music by using deep belief networks. It uses the extraction of low level acoustic features for music information retrieval (MIR). It can then find out e.g. of what genre the the musical piece was. The goal of the article is to find a system that can do this automatically. (Hamel & Eck, 2010)
This article communicates the results of a survey among musicians and attenders of musical concerts. The questions were about audience interaction. "... most spectators tend to agree more on influencing elements of sound (e.g. volume) or dramaturgy (e.g. song selection) in a live concert. Most musicians tend to agree on letting the audience participate in (e.g. lights) or dramaturgy as well, but strongly disagree on an influence of sound." (Hödl, Fitzpatrick, Kayali & Holland, 2017)
This article explains the workings of the musical robot Shimon. Shimon is a robot that plays the marimba and chooses what to play based on an analysis of musical input (beat, pitch, etc.). The creating of pieces is not necessarily relevant for our problem, however choosing the next piece of music is of importance. Also, Shimon has a social-interactive component, by which it can play together with humans. (Hoffman & Weinberg, 2010)
This article introduces Humdrum, which is software with a variety of applications in music. One can also look at humdrum.org. Humdrum is a set of command-line tools that facilitates musical analysis. It is used often in for example Pyhton or Cpp scripts to generate interesting programs with applications in music. Therefore, this program might be of interest to our project. (Huron, 2002)
This article focuses on next-track recommendation. While most systems base this recommendation only on the previously listened songs, this paper takes a multi-dimensional (for example long-term user preferences) approach in order to make a better recommendation for the next track to be played. (Jannach, Kamehkhosh & Lerche, 2017)
In this interview with a developer of the robot DJ system POTPAL, some interesting possibilities for a robot system are mentioned. For example, the use of existing top 40 lists, 'beat matching' and 'key matching' techniques, monitoring of the crowd to improve the music choice and to influence people's beverage consumption and more. Also, a humanoid robot is mentioned which would simulate a human DJ. (Johnson, n.a.)
In this paper a music scene analysis system is developed that can recognize rhythm, chords and source-separated musical notes from incoming music using a Bayesian probability network. Even though 1995 is not particularly state-of-the-art, these kinds of technology could be used in our robot to work with music. (Kashino, Nakadai, Kinoshita, & Tanaka, 1995)
This paper discusses audience interaction by use of hand-held technological devices. (McAllister, Alcorn, Strain & 2004)
This article discusses the method by which Spotify generates popular personalized playlists. The method consists of comparing your playlists with other people's playlists as well as creating a 'personal taste profile'. These kinds of things can be used by our robot DJ by, for example, creating a playlist based on what kind of music people listen to the most collectively. It would be interesting to see if connecting peoples Spotify account to the DJ would increase performance. (Pasick, 2015)
This paper takes a mathematical approach in recommending new songs to a person, based on similarity with the previously listened and rated songs. These kinds of algorithms are very common in music systems like Spotify and of utter use in a DJ-robot. The DJ-robot has to know which songs fit its current set and it therefore needs these algorithms for track selection. (Pérez-Marcos & Batista, 2017)
This paper describes the difficulty of matching two musical pieces because of the complexity of rhythm patterns. Then a procedure is determined for minimizing the error in the matching of the rhythm. This article is not very recent, but it is very relevant to our problem. (Shmulevich, & Povel, 1998)
In this article, the author states that the main melody in a piece of music is a significant feature for music style analysis. It proposes an algorithm that can be used to extract the melody from a piece and the post-processing that is needed to extract the music style. (Wen, Chen, Xu, Zhang & Wu, 2019)
This research presents a robot that is able to move according to the beat of the music and is also able to predict the beats in real time. The results show that the robot can adjust its steps in time with the beat times as the tempo changes. (Yoshii, Nakadai, Torii, Hasegawa, Tsujino, Komatani, Ogata & Okuno, 2007)
This paper describes Open Symphony, a web application that enables audience members to influence musical performances. They can indicate a preference for different elements of the musical composition in order to influence the performers. Users were generally satisfied and interested in this way of enjoying the musical performance and indicated a higher degree of engagement. (Zhang, Wu, & Barthet, ter perse)