Embedded Motion Control 2019 Group 7: Difference between revisions
| Line 6: | Line 6: | ||
== Group members == | == Group members == | ||
{| class="wikitable" style="width: | {| class="wikitable" style="width: 300px;" | ||
|- | |- | ||
! Name | ! Name | ||
Revision as of 13:58, 20 June 2019
Embedded Motion Control 2019 Group 7: PicoBello
Credits to Group 1 2019 for the wiki layout
Group members
| Name | Student nr. |
|---|---|
| Guus Bauwens | 0958439 |
| Ruben Beumer | 0967254 |
| Ainse Kokkelmans | 0957735 |
| Johan Kon | 0959920 |
| Koen de Vos | 0955647 |
Introduction
This wiki page describes the design process for the software as applied to the PICO robot within the context of the "Embedded Motion Control" course project. The project is comprised of two challenges: the escape room challenge and the hospital challenge. The goal of the escape room challenge is to exit the room autonomously as fast as possible. The goal of the hospital challenge is to autonomously visit an unknown number of cabinets as fast as possible.
Design Document
The design document, describing the initial design requirements, functions, components, specifications and interfaces, can be found here.
Requirements
Functions
Components
Specifications
Interfaces
Challenge 1: The escape room
As an intermediate assignment, the PICO robot should autonomously escape a room through a door from any arbitrary initial position as fast as possible.
To complete this goal, the following steps are introduced:
- The sensors and actuator are initialized.
- From the initial position, the surroundings are scanned for gaps between the walls. If no openings are found, the robot is to rotate until the opening is within view.
- The robot will drive sideways towards a subtarget (to prevent loosing the target when moving in front of it), placed at a small distance from the opening in order to avoid wall collisions.
- Once arrived at the subtarget, the robot will rotate towards the target.
- After being aligned with the target, the robot will drive straight trough the corridor.
To this end, methods for the detection of gaps between walls, the placement of (sub)targets and the path planning are required.
Data preprocessing
Beforehand, some of the measured data can already be labelled not useful. That data is summarized below.
- As the provided data structures have built in minimum and maximum values, data that is out of these bounds is first filtered out. This concerns the laser range finder radius and angle.
- Data can have outliers or unexpected readings, therefore data is removed using a low pass filter. Datapoints that have no close by neighboring points are therefore removed.
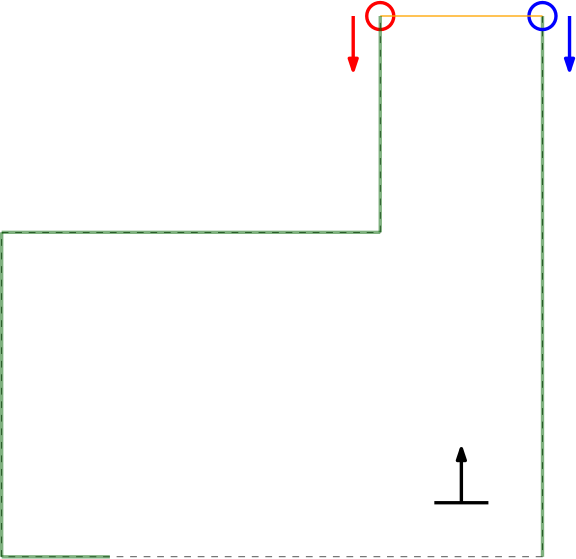
- Next to the initial angle correction, gap detection only works in the range of > 0 and < 180 degrees in front of PICO. This is to prevent reading out data that is perfectly in alignment with PICO's x-axis (lateral direction). This is to prevent data readings as depicted in the left Figure below.
Prevent lateral data measuring which cannot be used for gap detection.
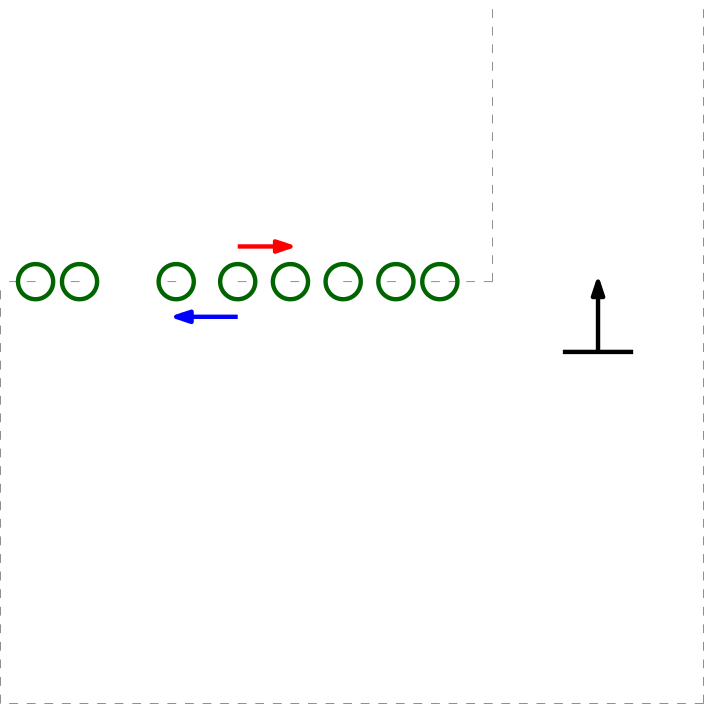
Remove data that does not have close by points.


Gap detection
From the initial position, the surroundings are scanned using a Laser Range Finder (LRF). A gap is detected when there is a significant jump (of more than 0.4 [m]) between two subsequent data points. This method is chosen for its simplicity, it does not require any mapping or detection memory.
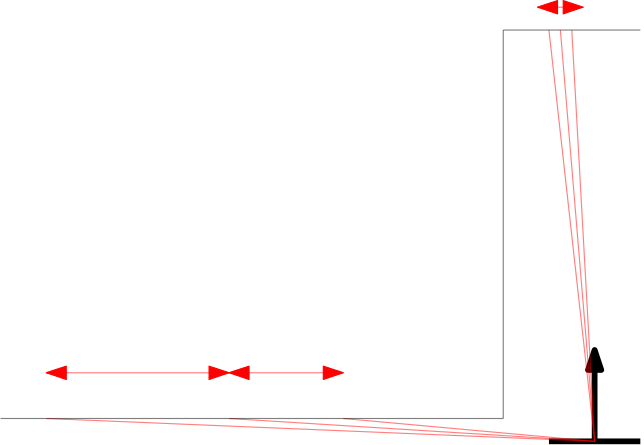
Within the context of the escape room challenge, either from within the escape room or from within the corridor a gap can be detected, as depicted in respectively the left and right Figures below.
As can be seen in these Figures, dependent on PICO's orientation, gaps can be detected under an angle resulting in a sub optimal recognition of the corridor entry. To this end, the gap size is minimized by moving the points on the left and right side of the gap respectively counterclockwise (to the left) and clockwise (to the right). The result of this data processing is shown in the left Figure where the dotted orange line depicts the initial gap, and the straight orange line depicts the final gap. Here, the left (red) point is already optimal and the right (blue) point is optimized.
In the right depicted example of a possible situation, PICO is located straight in front of the corridor. In this case the gap cannot be optimized in the same way because moving either of the points increases the distance between the points (as they are not iterated at the same time). However, the detected gap can be used as target for PICO and should result in a successful exit of the escape room if followed correct.y
Scheme of a possible Escape Room, with PICO located in the upper left corner.
Scheme of a possible Escape Room, with PICO located in the lower right corner.


Dealing With Boundary Scenarios
Initially 2 detected data points are be expected, 1 of each corner of the exit. This would be the case if the escape rooms exit would have empty space behind it. Topology wise this is true, but in practice the LRF will possibly detect the back wall of the room the escaperoom is placed in or other obstructions standing around the exit.
In the case a (more or less solid) backwall is detected, the gap finder will find 2 gaps, one on each side of the exit. In this case the closest left and right points are taken to set the target. The target is defined as the midpoint between these two closest data points.
(Sub)Target Placement
As driving straight to the target, the midpoint of a detected gap, should actually result in a collision with a wall in most circumstances (refer to the left Figure in the previous section), a subtarget is created. The target is interpolated into the escape room to a fixed distance perpendicular to the gap. This point is first targeted.
PICO will turn on its central axis so that it is facing parallel to the direction of the sub target to the target, and will drive in a straight line to reach it (which is therefore lateral). When PICO is approaching the subtarget, the corridor will become visible. As this removes the discontinuity in the data (as PICO can now see into the corridor), a new target is found consisting out of either 2 or 4 points. In the first case no backwall is detected, in the second case a back wall is detected. In this scenario two gaps will be found; to the left and to the right of the end of the exit. The new target will become the middle of the 1st and 4th point as again the closest left and right point are taken. A subtarget is set, but will not change PICO's desired actuation direction.
Path Planning
The loop of finding gaps is gone through continuously. The following cases are build in:
- 0 data points found
Protocol 1
If no data points are found, PICO should turn until it finds two valid data points which form a gap. If still no data points are found, PICO assumes he is to far away from the exit so switches to protocol 2.
Protocol 2
If after a full turn not data points were found, apparently no gaps are in range. PICO should move forward in a safe direction until it either cannot move anymore, a maximum distance is reached, or data points are detected. If none are detected, return to protocol 1.
- 2 data points found
The 2 points are interpolated as target, the sub target is interpolated. PICO should align itself with the sub target to target direction and move lateral towards it the lateral error is to big. If the lateral error is small enough, move straight forward.
- more than 2 data points found
The closest two points are used to calculate the gap.
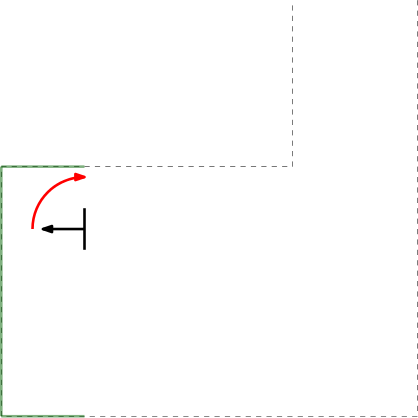
Step 1 of finding the escape room exit.
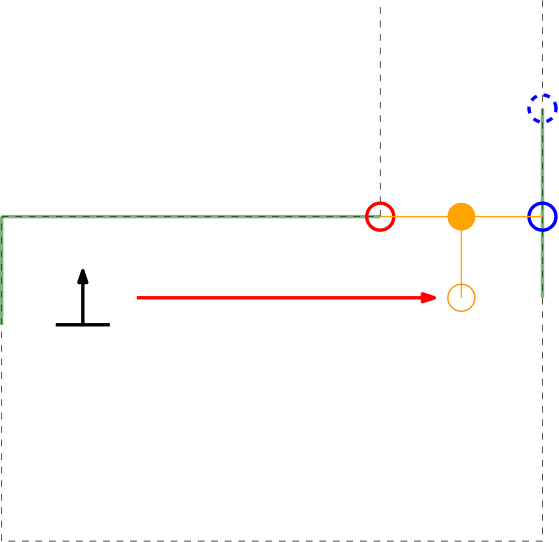
Step 2 of finding the escape room exit.
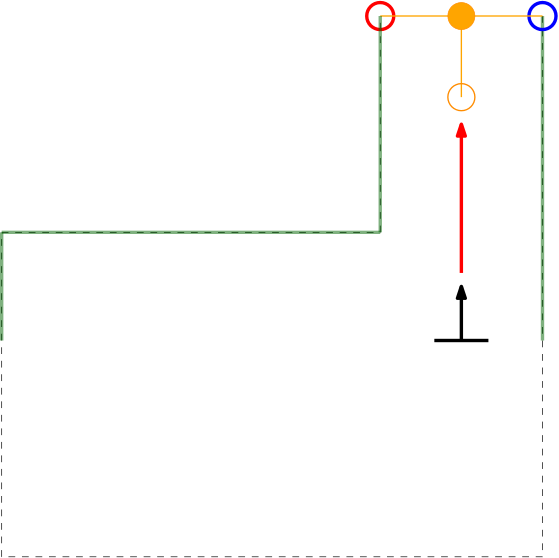
Step 3 of finding the escape room exit.



Dealing With Discontinuities In Walls
If a wall is not placed perfect, the LRF could find an obstruction behind the wall and indicate it as a gap (as the distance between the escape rooms wall and the obstruction will be bigger than the minimum value of a gap), while in practice the gap is too small to fit through and is not intended as the correct exit. These false positives should be filtered.
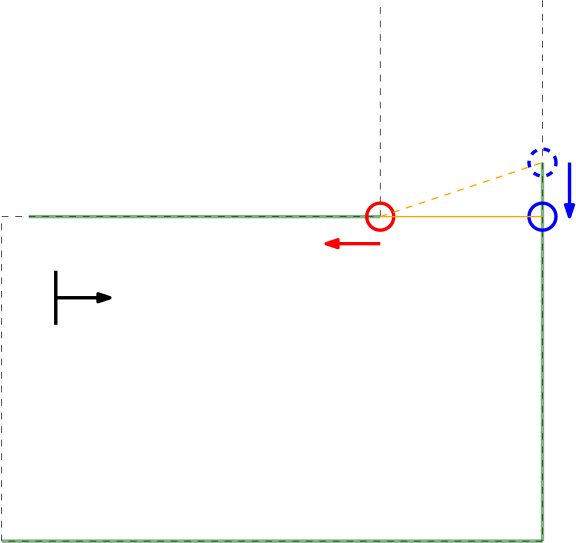
In the Figure below the algorithm used is depicted. From right to left (as this is the direction PICO stores data) first the actual gap is detected (yellow line), then 2 other gaps are detected as the LRF can see through the wall. The first point of every jump (the blue points) are checked for data points to the left that are too close by in local x and y coordinates. If this is the case, the gap cannot be an exit. Likewise, the left (the red points) are checked for data too close by to the right. This is done over all available valid data in the corresponding direction. If data is detected which is too close by, the set of points which form the gap are deleted. Note that the data will not be deleted when a back wall is detected behind the actual exit as the desired gap to be found is big enough.
This detection algorithm will break the exit finding procedure when a back wall is placed to close to the exit, but it is a given that the escape room will have an open exit.
When the algorithm i this to data points found in an actual gap. These points will never be too close by as the blue point will never have a data point to the left closer by then the minimum exit size (as will the red point to the left). Again (correctly) assuming that the escape room has an open exit. Important to note is that this check is done with the initial gap detection data points, not with the optimized location. If it would, in this example the blue point of the actual exit has directly neighboring data to its left (solid blue circle)!
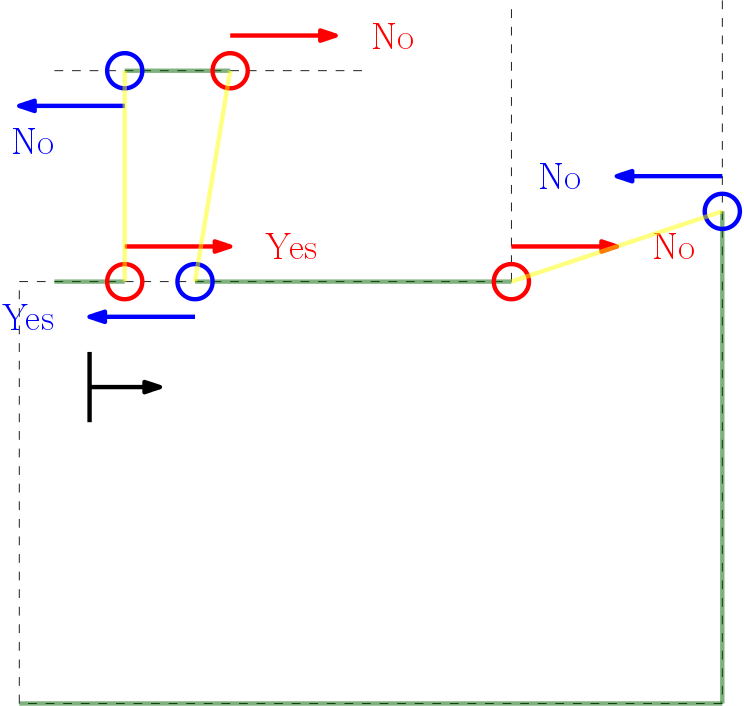
Checking discontinuity in walls.

Challenge Review
We became second with a finishing time of 60 seconds!
Initially 2 doors where introduced in the escape room. PICO would not have been able to find the correct exit as no check was implemented for the extra requirement that the walls of the exit are 3 m. PICO would have driven to the exit it saw first. If both exits would have been seen at the same time, PICO should have chosen the closest one with a risk of constantly switching between both if the distance is similar. The implementation of first aligning to the direction of the exit would have helped as the other gap should not have been visible anymore.
Despite of completing the challenge successfully, some undesired behavior was observed:
- Due to the long exit walls, PICO kept compensating its orientation position in front of the exit. Buffers which should have limited this behavior where implemented (a valid range for the orientation instead of a single value), but due to the big distance these are currently assumed to be non-sufficient. Also, due to the length of the exit the exit opening was closer to the obstacles around the RoboCup field, which is expected to have partially messed up the non-valid gap detection. Luckily there was a moment where the orientation was correct which moved PICO forwards.
- PICO stopped very close to the finish line. We expect this happened due to too much disturbance behind the escape rooms exit. We always tested with short exit corridors (as explained above), so during the challenge the exit was located much closer to the table standing in the hallway. We expect some other or even no valid exits were seen for a short moment. Luckily PICO did find the valid exit again and drove over the finish line!
- During the first try PICO hit the wall, so the safe distance to a wall should be validated. As we do not have the data, we do not know if the collision was caused by overshoot of the initial driving to sub target or due to not reacting/measuring the wall that was too close. As the second try was programmed to turn to opposite direction for gap detection, we probably avoided this error.
Our lessons learned during the Escape room challenge are that we should:
- be more strict in how we interpreted world information (two exits was technically allowed as one was defined with the correct corridor wall length),
- not assume that certain scenarios (longer walls) work without testing,
- validate the collision avoidance.
Challenge 2: Hospital
Overview
For the hospital challenge, the software design can be split into four parts: Planning, Control, Monitor and Perception. These parts will be explained in the sections below.

Planning
Control
When PICO knows its current pose (location and orientation) and its desired pose or trajectory, the software should determine which velocities (translational and rotational) will be sent to the base to achieve this in a stable and safe way. The chosen control strategy consists of two main parts:
- A 'normal' control strategy using feedforward and feedback to steer PICO towards its desired pose or trajectory, based on the world model.
- An extra check to avoid bumping into walls and (static and dynamic) obstacles by steering PICO away from those when it comes to close, based on the direct LRF data.
On a semantic level, these two strategies interact as follows: when PICO is not so close to walls and obstacles, the normal control strategy will dominate. When PICO comes very close to a wall or obstacle, the extra check will start to have more and more influence, to prevent bumping into them, even when the normal controller would steer PICO into their direction. The two seperate strategies are explained in more detail in the subsections below.
Normal control strategy
Obstacle avoidance
The need of an extra safety check
Once the path has been planned and is tracked by the feedforward and/or feedback controller, there still is a risk to hit a wall or obstacle. The path is planned based on the (updated) map and the tracking is done by means of the pose estimation from the particle filter. However, this pose estimation can and will have a small error, an obstacle could somehow not have been included in our (updated) map, etcetera. Therefore, a more direct approach is used as an extra safety means to avoid obstacles: potential fields.
Working principle
The potential fields are based on only the most recent LRF data. In a small neighborhood (a square of 2 by 2 meter) around PICO, a local gridmap is made, with dots (the LRF data) that indicate where walls/obstacles are. This map is then converted to a field, in which the height is an indication of the distance from that point to its closest wall/obstacle. The scaled (discretized) gradient of this field is used as the actuation for the translational directions of PICO, to prevent collisions.
Using only the direct LRF data for these potential fields also has a disadvantage: there is no data available in the region behind PICO. This problem is to a large extent overcome by not driving backwards.
Mathematical implementation
For the resolution of the local gridmap, a balance has been found between accuracy and speed by choosing 120 pixels per meter, giving an accuracy of slightly less than a centimeter. Such an accuracy is required, because PICO should be pushed away from obstacles and walls when they are very close, but the potential fields should not push PICO away too early, because then PICO would for example not be able to drive through a small gap. Given that the width of PICO is about 40 cm and it is desired to still be able drive through a gap of about 50 cm, the potential fields should thus not totally counteract the controller anymore at a distance of about 5 cm from a wall. Taking a too small distance is dangerous, because PICO will not always drive through gaps perfectly straight and the robot is not round but rather square with rounded edges. When simulating and testing, taking 3.5 cm appeared to be a suited value.

Further, it is not desired that there is a specific distance from obstacles that causes the potential fields to switch from providing no force to full force. Therefore, the slope of the field should increase gradually when coming closer to the wall. This has been implemented by shaping the field with the function:
[math]\displaystyle{ f(x) }[/math] = [math]\displaystyle{ \alpha }[/math][math]\displaystyle{ x }[/math]-[math]\displaystyle{ n }[/math]
in which [math]\displaystyle{ f(x) }[/math] is the height of the grid point in the field, [math]\displaystyle{ \alpha }[/math] is a constant that will be explained later, [math]\displaystyle{ x }[/math] is the distance from the grid point to its closest grid point with an obstacle and [math]\displaystyle{ n }[/math] is the tunable exponent that determines to fast the function decreases for increasing [math]\displaystyle{ x }[/math]. The (negative) gradient* of this field will be added to the reference that is sent to the base. When there would for example only be a wall in front of PICO, we can consider the one dimensional case, in which the gradient is the derivative:
[math]\displaystyle{ d }[/math][math]\displaystyle{ f(x) }[/math]/[math]\displaystyle{ dx }[/math] = -[math]\displaystyle{ n }[/math][math]\displaystyle{ \alpha }[/math][math]\displaystyle{ x }[/math]-[math]\displaystyle{ n }[/math]-[math]\displaystyle{ 1 }[/math]
*The gradient has in fact been implemented as the finite central difference in both directions. When choosing the grid size small enough and the exponent [math]\displaystyle{ n }[/math] not too high, this will not cause any problems.
Instead of using [math]\displaystyle{ \alpha }[/math] and [math]\displaystyle{ n }[/math], it would be desirable to have a distance [math]\displaystyle{ d }[/math] and the exponent [math]\displaystyle{ n }[/math] as tuning knobs. If the distance [math]\displaystyle{ d }[/math] should be the distance at which the potential fields always cause full actuation away from the obstacles, independent of the normal controller, it should hold that:
[math]\displaystyle{ n }[/math][math]\displaystyle{ \alpha }[/math][math]\displaystyle{ d }[/math]-[math]\displaystyle{ n }[/math]-[math]\displaystyle{ 1 }[/math] = [math]\displaystyle{ 2 }[/math][math]\displaystyle{ v_{max} }[/math]
in which [math]\displaystyle{ v_{max} }[/math] is the maximum velocity, which is also used to bound the normal controller output. Using two times this velocity therefore ensures that full actuation in the opposite direction can be achieved. Rewriting the formula above yields:
[math]\displaystyle{ \alpha }[/math] = [math]\displaystyle{ 2 }[/math][math]\displaystyle{ v_{max} }[/math][math]\displaystyle{ d }[/math][math]\displaystyle{ n }[/math]+1/[math]\displaystyle{ n }[/math]
which has been implemented in the software, so that the tuning knobs are [math]\displaystyle{ d }[/math] and [math]\displaystyle{ n }[/math]. As explained above, a suited value for [math]\displaystyle{ d }[/math] was found to be 23.5 cm (half the robot width plus the margin of 3.5 cm). A suited value for [math]\displaystyle{ n }[/math] partly depends on the used normal controller (due to the interaction with it as explained above), and was in our case found to be about 2.5.
Monitor
Perception
The perception component is responsible for translating the output of the sensors, i.e. odometry data and LRF data, into conclusions on the position and enivorment of PICO.
Localization on the global map is performed using a particle filter. Detection of static obstacles is done using a histogram filter.
Monte Carlo Particle Filter (MCPF)
In the hosptial challenge it is very important that PICO is able to localize itself on the global map, which is provided before the start of the challenge. The particle filter is responsible for finding the starting location of PICO when the executable is started. After the initilization procedure it will keep monitoring and updating the position of PICO based on the available LRF and odometry data.
General Implementation
- Initialization
When the excecutable is started PICO does not know where it is, besides being somewhere in the predefined starting area. In order to find the most likely starting position (more on this later), an initialization procedure was devised which is able to, whithin a limited time frame, find a set of possible starting positions. Finding this starting position is best described by the following pseudo code.
...
loop for N times
{
Intialize particles randomly
Calculate probability of particles
Pick and store X particles with largest probability
}
...

This algortihm provides the particle filter with a list of particles which describe the possible starting position of PICO. This list of particles is then used as an initial guess of the probability distribution which describes the location of PICO. This distribution is not necessarily unimodal, i.e. it is possible that a certain starting position delivers identical data with respect to another starting location. It is therefore not possible to immediately conclude that the mean of this distribution is the starting location of PICO. The probability distribution stored in the particle filter must first converge to a certain location, before the mean position can be send to the world model. Convergence of the probability distribution is tested by calculating the maximum distance between "likely" particles, in which a "likely" particle is defined as a particle with a probability larger than a certain value. This distance is constantly monitored to determine whether convergance has been achieved.
Often it is not possible for the particle filter to converge without additional information. This is for instance the case when PICO is in a corner of a perfectly square room with no exit and perfectly straight corners. In this case the particle filter will first signal to the state machine that it has not yet converged, the state machine will then conclude that it has to start turning or exploring to provide the particle filter with extra information on the current location of PICO. When sufficient information has been collected to result in an unqiue location and orientation for PICO the particle filter will signal the state machine that it has converged. After convergence the particle filter will start its nominal operation, described below.
- Propagating on the basis of odometry data
After initalization of the particle filter the starting position of PICO is known, however PICO is a mobile robot so its position is not constant. It is possible to run the initialisation procedure every iteration to find the new location of PICO, this is however not very efficient. We know the probability distribution of the location of PICO in the last iteration, before it moved to a new location. Additionally we have an estimate of the difference in location since we last calculated the location of PICO, this estimate is namely based on the odometry data of the wheel encoders of PICO. This estimate can be used to propagate all particles, and thereby propagate the probability distribution itself, to the new location.
In simulation this propagating of the particles on the basis of the wheel encoders would exaclty match the actual difference in location of PICO, as there is no noise or slip implemented in the simulator. In reality these effects do occur though. In order to deal with these effects a random value is added to the propagation of each particle. This makes sure that the particles are located in a larger area than would be the case if the particles were propagated naively, without any noise. This larger spread of particles then ensures that the actual change of location of PICO is still within the cloud of particles, which would not be the case when the spread of particles was smaller.
In pseudo code the propagating of particles can be described in the following way:
...
for all particles
{
X = sample(uniform distribution (a,b))
Y = sample(uniform distribution (a,b))
O = sample(uniform distribution (c,d))
x location += xshift + X
y location += yshift + Y
orientation += oshift + O
}
...
- Find probability of each particle
Up until now the described particle filter is only able to create and propagate particles, however it is not yet able to conclude anything about its current position in any quantative way. A probability model for each particle is needed before any conclusions can be drawn. The LRF data is the perfect candidate to draw conclusions on the current position of PICO. The LRF data does not have the disadvantage of the odometry data, i.e. that it is unreliable over large distances. The LRF data by definition always describes what can be seen from a certain location. It is possible that there are objects within sight, which are not present on the map, however it will later be shown that a particle filter is robust against these deviations from the ideal situation.
The probability of a particle is defined on the basis of an expected measured LRF distance and the actually measured distance. This however assumes that the expected measured LRF distance is already known. This is partly true, as the approximate map and particle location are both known. Calculating the distance between one point, given an orientation and map, is however not a computationally trivial problem. In order to efficiently implement the particle filter, given the time constraints of the EMC course, it was chosen to use a C++ library, to solve the socalled raycasting problem. The documentation, github repository, and accompanying publication of the range_libc library can be found in the references. [1] In order to be able to run the particle filter in realtime the fastest algorithm, i.e. Ray Marching, was chosen to be used in the particle filter. The exact working of these raycasting algorithms will not be discussed on this wiki.
With both the measured and expected distance (based on the particle location) known, it is possible to define a probability density function (PDF), which maps these two values to a likelihood of the considered ray. In this implementation the decision was made to choose a PDF which is combination of a uniform and gaussian distribution. The gaussian distribution is centered around the measured value and has a small enough variance to drastically lower the likelihood of particles that do not describe the measurement, but a large enough variance to deal with noise and small mapping inaccuraries. The uniform distribution is added to prevent measurements of obstacles immediately resulting in a zero likelihood ray. The likelihood of rays is assumed to be independent, this is done in order to be able to easily calculate the likelihood of a particle. When the measurements are independent the likelihood of a praticle is namely the product of the likelihoods of the rays. After determining the likelihood of each particle, their likelihoods need to be normalized such that the sum of all likelihoods is equal to one.
In order to implement the above stated probability model two important deviations from this general setup were made. Firstly it was noticed that it is difficult to represent the particle likelihoods, before normalisation, using the standard C++ data types. Given that the above stated probability model has a maximum value of approximately 0.6, it is easy to compute that even likely particles, which each contain 1000 rays, will have likelihoods smaller than 1e-200. In order to solve this problem another way of storing the likelihoods was devised. For the final implementation a scientific notation object was developed. In this object two values are stored seperatley. A double to store the coefficient and an integer to store the exponent. This allows us to store a large range of very small and very large values.
A second implementational aspect has to do with the maximum achievable excecution speed. One can imagine that the before stated raycasting algorithm is quite heavy to run, compared to other parts of the software. In order to prevent slow downs the particle filter is assigned a separate thread, as discussed before. However to further reduce the excecution time a decision was made to down sample the available data. Out of all 1000 available rays, only 100 are used. There is a risk of missing features when heavy down sampling is used, however no significant reduction in accuracy has been noticed due to down sampling the available data. In literature, most notably the source of the ray casting library, down sampling the LRF is standard practice in order to reduce the computational load.[2]
- Finding Location of PICO
With the probability distribution (represented by the particles and their likelihoods) known, it is possible to estimate the location of PICO. Ideally one would take the weighted median of the probability distribution to find the most likely position of PICO. However taking the median of a three dimensional probability distribution is not trivial. One could take the median over each dimension, however this is not guaranteed to result in a location which is actually in the distribution. The initialisation procedure was devised in order to tackle this problem. The procedure makes sure that the distribution is unimodal. Given this unimodal distribution it is possible to take the weighted mean of the distribution to find the most likely location of PICO.

- Resampling
The "real trick" [3] and important step of the particle filter algortihm is resampling. A particle filter without resampling would require a lot more particles in order to accuratly describe the earlier discussed probability distribution. This hypothetical particle filter would have a lot of particles in regions where the likelihood is very small. The basic idea of resampling is to remove these particles from the particle filter and replace them either with a random particle, or with a particle placed in a region with a high probability. Selection of particles is done in a non-determenisitic way, a particle is chosen with a probability of its likelihood.
In resampling it is often preferred to also inject random particles in the filter. Random particles allow the particle filter to re-converge to the true location when the current estimate is no longer valid. The risk of random particles is most apparent in an identical room situation. A particle that is initialised in a situation close to identical to the true location will lead to a risk of losing the true estimate. In this implementation random particles are not injected into the filter during normal operation, to prevent losing the accuracy of the estimate.
Resampling is done using a resampling wheel. A resampling wheel is an algorithm which allows us to resample the particles in the particle filter without having to make and search a list of the cumulative sum of all likelihoods, which would be required when one would draw a random number and select a particle purely based on the interval in which this number is located. Our implementation of the resampling wheel can be found in the code snippet at the end of this page. Conceptually a resampling wheel works in the following way. Some changes to the maximum step size were made in order to incorporate random particles and dynamic resizing of the amount of particles in the particle filter.
Performance
Obstacle Detection
The perception of PICO is not limited to finding its position on the provided map. Based on the location data PICO is able to keep track of obstacles and walls that it can see using its LRF. Based on this observations it creates a secondary map using the histogram filter described in this chapter.

General Implementation
The histogram filter contains a grid map of the probabilities of objects in a certain location. This grid map is initialized at robot start up as an uniform distribution. When one ray of PICO lands inside an element of this grid, i.e. when PICO detects something in this grid square, the histogram filter will update the likelihood of an object at this location. Updating the likelihood is done according to Bayes theorem, which effectivley means that the probability is incrementally updated at each observation. The big advantage of this approach is that multiple observations of an object are necessary before conclusions are drawn. The incremental updating decreases the sensitivity of the histogram filter for noise on the observations, outliers in the data and most importantly (sufficiently) dynamic objects.
Not only does detecting an object provide information about the presence of an object, so does not detecting an object at a certain location. This is for instance the case when we know that a certain detection is only possible when there is no object between PICO's current location and the object that was detected. In order to test wheter this is the case for points in the grid a point polygon test is performed, using OPENCV. The polygon is defined as the cloud of LRF data around PICO, the points that are inside this polygon provide infromation on the absence of objects.
In order to be less sensitive for mapping inaccuracies it is important to realize that only local information can be fully trusted. A slightly shorter corridor could otherwise be recognized as an obstacle when viewed from a distance. Therefore a maximum range is set which can be updated. When a point is outside of this range, in the final implemenation two meters, it will not be updated. This does not only make the implementation more robust it also significantly decreases the required computational time.
Furthermore to prevent path infeasibilities, and therefore increase robustness, it is explicilty assumed that all cabinets are reachable. When the path planning algorithmn becomes infeasible the histogram filter is re-initialized as a uniform distribution. This removes all detected objects from the map, making the path feasible again. Due to the specifics of the implementation this will only remove the objects, the original provided map will remain known to the robot and path planner.

Performance
The performance of the localization, performed by the particle filter, and obstacle detection, performed by the hisogram filter, is best analysed simultaneously. Inaccurate estimates provided by the particle filter would be an input of the histogram filter, and would therefore immediately be noticiable on the obstacle map. It can furthermore be checked wheter the histogram filter is robust enough to the slight variations in estimates of the location provided by the particle filter.
The output of the particle and histogram filters after completing the final hospital challenge are shown in the Figure next to this chapter. The output shows the estimated position of PICO in green and the particles in the particle filter in red. The obstacles and walls are plotted in white and part of the path of PICO is shown as a green line. It can be seen that all of the objects that were added to the hospital enviroment during the challenge are present in the output of the perception. It should be noted that only the front of these objects are present, since this is the only part of the objects that is actually visible.
Some of the objects present in the output can not be explained as being a static object. The first of which are the diagonal lines which are present next to cabinets. The origin of these points is explained when one views the LRF data of PICO. When sharp corners are encountered it is possible that the LRF returns on the lines shown in the output, this is due to the inner working of the sensor. Normally these points are removed after some time due to the working of the histogram filter, however this is not the case in the area around cabinets. This is because PICO will hardly see this area, without being in front of the cabinet. The histogram filter does not have the time to see that there is no object there.
The second non static object seen on the output are some seemingly random groups of pixels located, among other, next to the boxes in the corridor. This can likely be explained when one watches the video of the final challenge. The dynamic object stands still for some time next to these boxes. The histogram filter likely recognizes this as an object, and afterwards does not have to chance to see that there is actually no object there.
World Model
Conclusion
Snippets
Resampling Wheel[1]
References
- ↑ kctess5(2017). range_libc: A collection of optimized ray cast methods for 2D occupancy grids including the CDDT algorithm. Written in C++ and CUDA with Python wrappers. https://github.com/kctess5/range_libc
- ↑ H. Walsh, Corey & Karaman, Sertac. (2018). CDDT: Fast Approximate 2D Ray Casting for Accelerated Localization. 1-8. 10.1109/ICRA.2018.8460743.
- ↑ Thrun, S., Burgard, W., & Fox, D. (2006). Probabilistic robotics. Cambridge, Mass: The MIT Press.